مقدمة
- الغرض من هذا المشروع هو توسيع حدود استخدام Bert-Vits2 ، مثل TTS لتوليد بيانات تعبير الوجه بشكل متزامن.
- انظر التأثير
- Demo Bilibili YouTube
- TTS مع Audio2Photoreal -> metahuman
- توليد اختبارات عاطفية من الغناء ؛ مقارنة بين الرموز عند التحدث إلى Azure TTS
- أنشأت TTS الإصدار الأول من Emoji ، مزودة بـ MotionGpt
تمتد إلى cosyvoice
امتدت إلى GPT-sovits
- اختبار التعبير GPT-SOVITS
- إعادة التدريب مباشرة على GPT-Sovits ، نتائج الاختبار الفعلية سيئة نسبيا
- تتمثل الطريقة المؤقتة في نسخ نموذج الجزء الخلفي وتوليد التعبير مباشرة من BERT-VITS2-EXT إلى GPT-SOVITS للاختبار.
- يؤدي هذا إلى حساب متكرر والمزيد من التنبؤات
TTS
نشأ رمز TTS من الإصدار النهائي Bert-Vits2 V2.3 [20 ديسمبر ، 2023]
- https://github.com/fishaudio/bert-vits2/commit/7EBC1AA28A055608F7E31DA93928CF295FDFFFEBA
بعد الاختبار ، أشعر شخصياً أن تأثير التدريب للمواد الصينية النقية 2.1-2.3 أسوأ قليلاً من 1.0. يمكنك التفكير في تقليل الإصدار أو خلطه مع الصينية النقية.
يتم عرض طريقة التدريب لـ TTS نفسها في النص الأصلي (كل إصدار مختلف)
- الإصدار الموصى به 1.0 https://github.com/yyux-1145/bert-vits2-integration-package
TTS Tynchronous Output Emoji
الأفكار
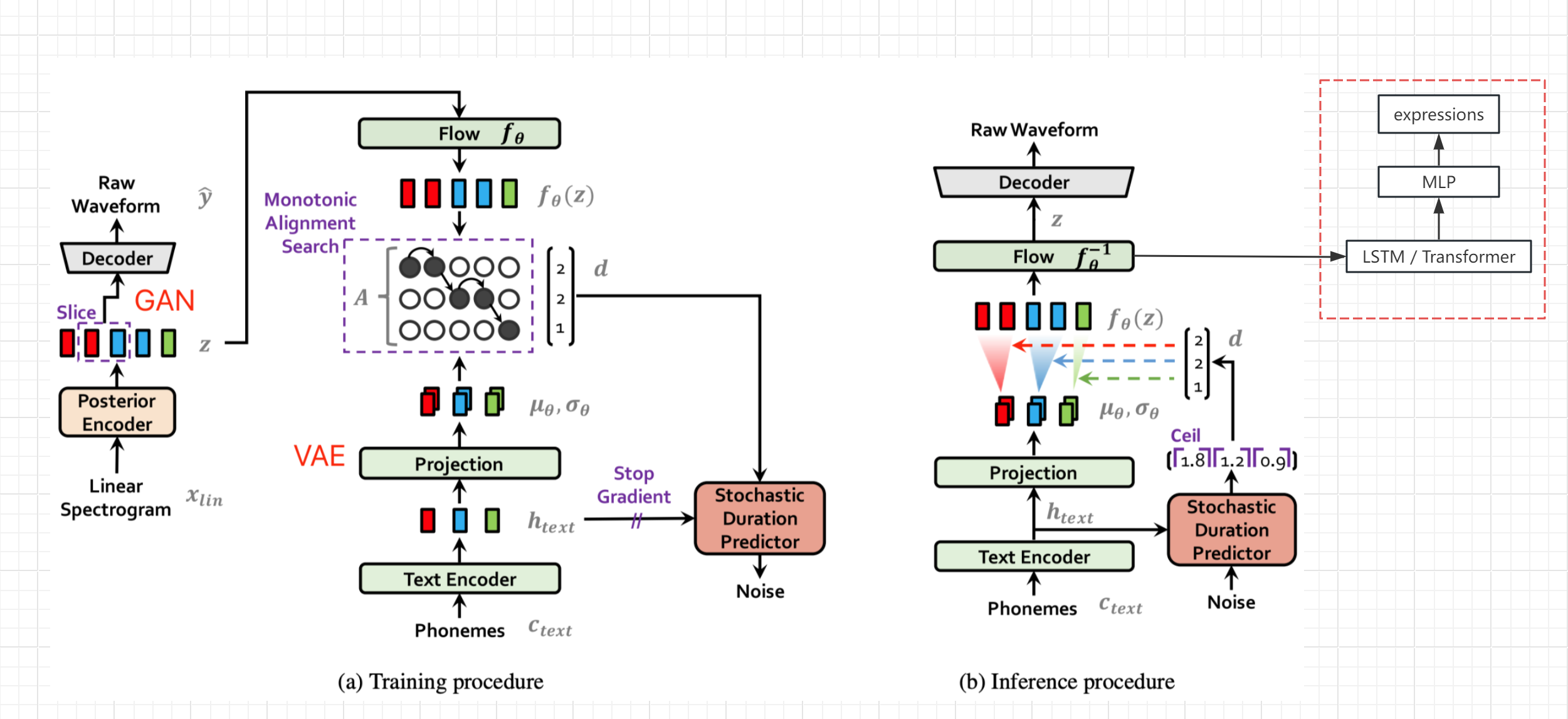
- ارجع إلى مخطط هيكل الشبكة لورقة Vits (وليس Bert-Vits2 ، ولكن الهيكل العام هو نفسه) ، والحصول على المتغير المخفي z بعد ترميز النص وتحوله وقبل فك التشفير ، وإخراج قيمة التعبير من الالتفافية (القيمة الاسمية Live Link)
- قم بتجميد معلمات الشبكة الأصلية ، وإضافة معالجة LSTM و MLP بشكل منفصل ، واستكمال توليد SEQ2Seq ورسم الخرائط من Z إلى التعبير
- بالطبع ، إذا كانت هناك بيانات تعبير عالية الجودة ، يمكن أيضًا إضافة التعبير إلى تدريب شبكة TTS الأصلي ، والذي يجب أن يحسن جودة الصوت
جمع البيانات
- قم بتعيين أهداف Live Link Face على IP الأصلي ، والمنفذ الافتراضي إلى 11111
- اجمع بشكل متزامن إخراج قيم التعبير الصوتي والتعبير المقابل عن طريق Live Link ، وقم بتخزينه في مجلد السجلات على التوالي
- قم بتنفيذ مجموعة البرامج النصية لمدة 20 ثانية في كل مرة
- الافتراضات الصوتية إلى 44100 هرتز
- قد يتم تعويض جمع الصوت والتعبير
- مقارنة فقدان مجموعة التحقق للعثور على موضع الإزاحة الأمثل لنفس مصدر البيانات
python ./motion/record.py
python ./motion/tts2ue.py --bs_npy_file ./records/2023-12-23-17-19-54.npy --wav_file ./records/2023-12-23-17-19-54.wav --fps 60
البيانات المسبقة للبيانات
- اقرأ جميع ملفات الصوت في السجلات ، واستخدم المشفر الخلفي لتخزين المتغير المخفي Z المشفر بواسطة الصوت إلى *.z.npy
- اكتب إلى قائمة الملفات للتدريب والتحقق
- ملفات الملفات/val_visemes.list
- ملفات الملفات/train_visemes.list
python ./motion/prepare_visemes.py
يدرب
- إضافة -فصح بعد Train_Ms.py للتمييز بين التدريب من MainNet
python train_ms.py -m OUTPUT_MODEL --config ./configs/config.json --visemes
التفكير
- عند تنفيذ webui.py ، يتم كتابة صوت الإخراج والمتغيرات المخفية وبيانات الرسوم المتحركة إلى الدليل الحالي. يمكنك استخدام ttts2ue.py لعرض التأثير الذي تم إنشاؤه
- FPS الافتراضي للرسوم المتحركة التي تم إنشاؤها هي نفس المتغير المخفي 86.1328125
- 44100/86.1328125 = 512 ، قابلة للقسمة فقط ، يتم تحديد هذا بواسطة تردد أخذ عينات الصوت Bert-VITS2 ، بنية الشبكة و Hidden_Channels
python ./motion/tts2ue.py --bs_npy_file ./tmp.npy --wav_file ./tmp.wav --delay_ms 700
صوت للتعبير
- استخدم المشفر الخلفي لتحويل الصوت إلى z ، ثم تحويل z إلى تعبير
- يجب تحويل الصوت إلى ملف WAV 44100Hz ويتم الاحتفاظ بقناة واحدة فقط (FFMPEG)
# 音频截取转换
ffmpeg -i input_file -ss 00:00:00 -t 00:00:10 -ar 44100 -f wav test.wav
# 保留通道1
ffmpeg -i test.wav -map_channel 0.0.0 output.wav
python ./motion/wav_to_visemes.py output.wav
الرسوم المتحركة للجسم
MotionGpt
- باستخدام الصوت والتعبيرات ، يمكنك أيضًا إنشاء وصف للتطبيق تحت محرك الأقراص LLM ، ثم استخدام نموذج النصي إلى الحركة لإنشاء الرسوم المتحركة للجسم التي تتطابق مع محتوى الكلام ، وحتى التفاعل مع المشهد وغيرها.
- المشروع المستخدم في اختبار النص إلى الحركة هو motiongpt
- لم يتم إجراء أي عملية تعامل مع الرسوم المتحركة بعد. يتم دعم الحركة بين الفترات من خلال نموذج المقدمة.
- لا يمكن لقاعدة Flan-T5 التي تستخدمها MotionGPT فهم الصينية ، لذلك لا يمكن أن تولد الرسوم المتحركة ذات المزامنة العالية مع نص التحدث (يتغير ترتيب الكلمة إلى حد ما بعد الترجمة إلى اللغة الإنجليزية)
- سواء كان من الممكن استخدام نص التحدث أو المتغير المخفي Z لتوجيه توليد الإجراء لم يكن معروفًا بعد
- يخرج MotionGPT موضع العظام ، والذي لا يمكن توصيله مباشرة بالرسوم المتحركة للهيكل العظمي لـ UE.
- حاليًا ، يتم استخدام طرق مبسطة لتقدير قيمة الحركة ، وستكون هناك خسائر كبيرة في الموضع
- احسب مقدار تغيير الدوران للعظم بالنسبة للعقدة الأصل (الرباعة)
- أرسله إلى برنامج VMCTOMOP من خلال بروتوكول OSC ، ومعاينة تحويل الرسوم المتحركة وأداء تحويل بروتوكول
- خريطة MOP بيانات إلى Metahuman بمساعدة المكون الإضافي MOP
Audio2photoreal
- تعديل على أساس المشروع الأصلي وتصدير بيانات الرسوم المتحركة إلى الملفات المحلية أثناء استدلال واجهة الويب
- عملية التصدير
- رمز https://github.com/see2023/audio2photoreal
BERT-VITS2 البيان الأصلي
Vits2 العمود الفقري مع بيرت متعدد اللغات
للحصول على دليل سريع ، يرجى الرجوع إلى webui_preprocess.py .
للحصول على برنامج تعليمي بسيط ، راجع webui_preprocess.py .
يرجى ملاحظة أن الفكرة الأساسية لهذا المشروع تأتي من anyvoiceai/masstts مشروع TTS جيد جدًا
العرض التوضيحي لـ Masstts لإصدار AI من Feng GE ، واستعاد خصصه المفقود في المثلث الذهبي
يجب أن يشير المسافر/المسافر الناضج/القبطان/الطبيب/Sensei/Wormurhunter/Meowloon/V إلى الكود لتعلم كيفية تدريب نفسك.
يُحظر بشدة استخدام هذا المشروع لجميع الأغراض التي تنتهك دستور جمهورية الصين الشعبية ، والقانون الجنائي لجمهورية الصين الشعبية ، وقانون عقوبة جمهورية الصين الشعبية ، والمدونة المدنية لجمهورية الصين الشعبية.
إنه محظور بشكل صارم لأي غرض من الناحية السياسية.
الفيديو: https: //www.bilibili.com/video/bv1hp4y1k78e
العرض التوضيحي: https://www.bilibili.com/video/bv1tf411k78w
مراجع
- anyvoiceai/masstts
- Jaywalnut310/vits
- P0P4K/VITS2_PYTORCH
- SVC-Develop-Team/SO-VITS-SVC
- PADDLEPADDLE/PADDLESPEEDE
- حركات عاطفية
- مكبوت الأسماك
- Bert-its2-ui
شكرا لجميع المساهمين على جهودهم


