Introduction
- Le but de ce projet est d'élargir les limites d'utilisation de Bert-Vits2, telles que TTS générant de manière synchrone les données d'expression faciale.
- Voir l'effet
- Démo bilibili youtube
- TTS avec audio2photoreal -> Metahuman
- Générer des tests d'émoticône à partir du chant; Comparaison des émoticônes lorsque vous parlez à Azure TTS
- TTS générée en première version emoji, équipée de motiongpt
S'étendre au cosyvoice
- Test d'émoticône cosyvoice
Étendu aux sovits GPT
- Test d'expression de GPT-Sovits
- Recyclage directement sur GPT-SOVITS, les résultats réels des tests sont relativement mauvais
- La méthode temporaire consiste à copier directement la partie postérieure et le modèle de partie de génération d'expression de Bert-Vits2-Ext à GPT-Sovits pour les tests.
- Il en résulte un calcul répété et plus de prédictions
Tts
Le code TTS est originaire de Bert-Vits2 V2.3 Libération finale [20 décembre 2023]
- https://github.com/fishaudio/bert-vits2/commit/7ebc1aa28a055608f7e31da93928cf295fdffeba
Après les tests, je pense personnellement que l'effet de formation des matériaux chinois purs 2.1-2.3 est légèrement pire que celui de 1,0. Vous pouvez envisager de réduire la version ou de le mélanger avec un chinois pur.
La méthode de formation de TTS elle-même est montrée dans le texte d'origine (chaque version est différente)
- Version recommandée 1.0 https://github.com/yyux-1145/bert-vits2-integration-package
Emoji de sortie synchrone TTS
Idées
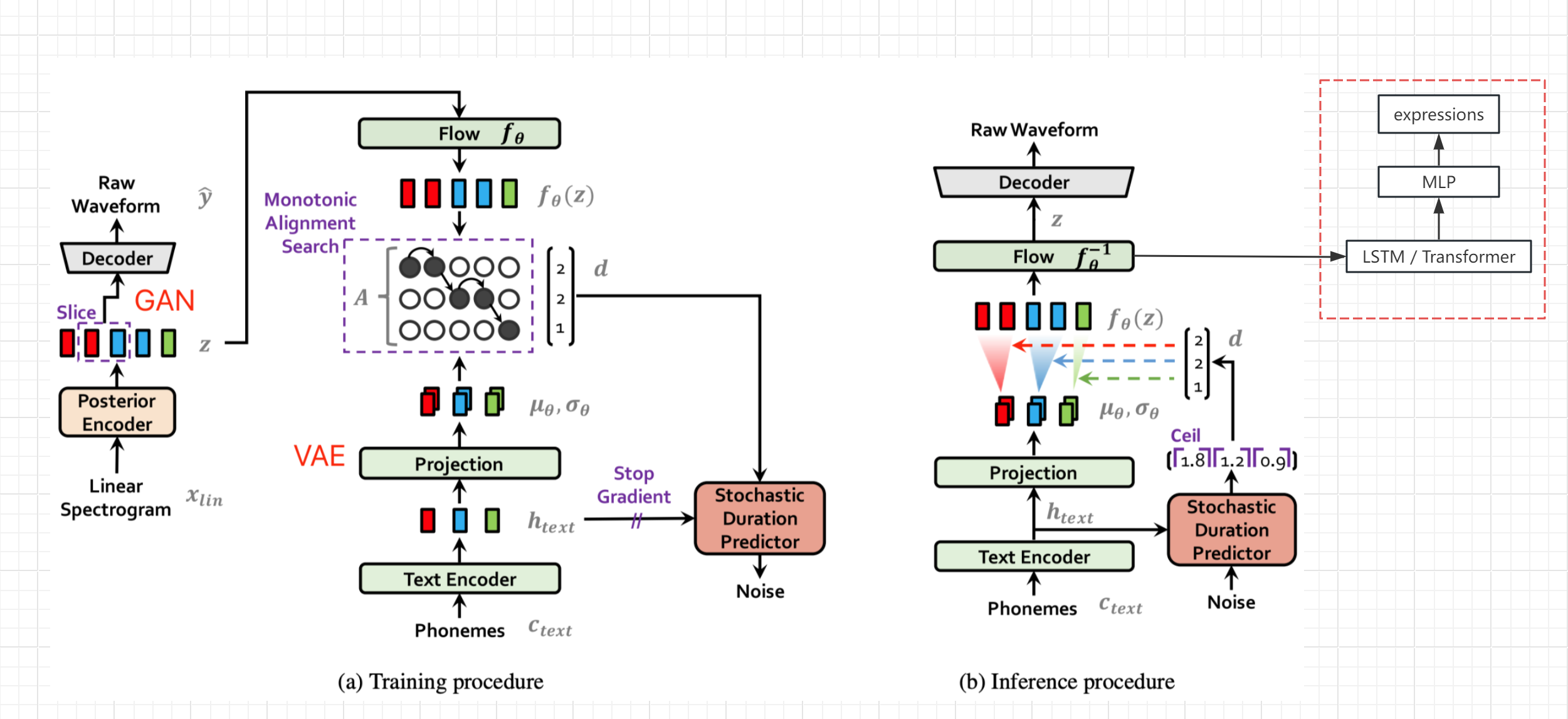
- Reportez-vous au diagramme de structure du réseau du papier VITS (pas Bert-Vits2, mais la structure générale est la même), obtenez la variable cachée z après codage et transformation du texte et avant le décodage, et émettez la valeur d'expression à partir du pontage (valeur nominale de liaison vivante)
- Gèler les paramètres du réseau d'origine, ajouter séparément le traitement LSTM et MLP, et terminer la génération SEQ2SEQ et la cartographie de l'expression Z
- Bien sûr, s'il existe des données d'expression de haute qualité, l'expression peut également être ajoutée à la formation du réseau TTS d'origine, ce qui devrait améliorer la qualité audio
Collecte de données
- Définissez les cibles de la face de liaison en direct à l'IP native, et le port par défaut à 11111
- Collectez de manière synchrone les valeurs de la voix et les valeurs d'expression correspondantes par lien en direct et stockez-les respectivement dans le dossier des enregistrements
- Exécuter la collection de scripts pendant 20 secondes à chaque fois
- Audio par défaut est à 44100 Hz
- La collection audio et d'expression peut être compensée
- Comparaison de la perte de l'ensemble de vérification pour trouver la position de décalage optimale pour la même source de données
python ./motion/record.py
python ./motion/tts2ue.py --bs_npy_file ./records/2023-12-23-17-19-54.npy --wav_file ./records/2023-12-23-17-19-54.wav --fps 60
Prétraitement des données
- Lisez tous les fichiers audio en enregistrements, utilisez l'encodeur postérieur pour stocker la variable cachée z codée par l'audio dans * .z.npy
- Écrivez dans la liste des fichiers pour la formation et la vérification
- Fileslists / Val_vismes.list
- Fileslists / Train_vismes.list
python ./motion/prepare_visemes.py
former
- Ajouter - revusmes après train_ms.py pour distinguer la formation de MainNet
python train_ms.py -m OUTPUT_MODEL --config ./configs/config.json --visemes
raisonnement
- Lorsque webui.py est exécuté, l'audio de sortie, les variables cachées et les données d'animation sont écrites dans le répertoire actuel. Vous pouvez utiliser tts2ue.py pour afficher l'effet généré
- Les FP par défaut de l'animation générée sont les mêmes que la variable cachée 86.1328125
- 44100 / 86.1328125 = 512, juste divisible, ceci est déterminé par la fréquence d'échantillonnage audio Bert-Vits2, la structure du réseau et Hidden_Channels
python ./motion/tts2ue.py --bs_npy_file ./tmp.npy --wav_file ./tmp.wav --delay_ms 700
Voix à l'expression
- Utilisez le codeur postérieur pour convertir le son en z, puis convertir le z en une expression
- L'audio doit être converti en un fichier WAV 44100Hz et un seul canal est conservé (FFMPEG)
# 音频截取转换
ffmpeg -i input_file -ss 00:00:00 -t 00:00:10 -ar 44100 -f wav test.wav
# 保留通道1
ffmpeg -i test.wav -map_channel 0.0.0 output.wav
python ./motion/wav_to_visemes.py output.wav
Animation corporelle
Motiongpt
- Avec la voix et les expressions, vous pouvez également générer une description d'action correspondante sous le lecteur LLM, puis utiliser le modèle de texte en mouvement pour générer des animations corporelles qui correspondent au contenu de la parole, et même interagir avec la scène et d'autres.
- Le projet utilisé pour les tests de texto est MotionGpt
- Aucun surproduction d'animation n'a encore été effectué. Le mouvement entre les deux est soutenu par le modèle d'introduction.
- La base Flan-T5 utilisée par MotionGpt ne peut pas comprendre le chinois, il ne peut donc pas générer d'animations avec une synchronisation élevée avec du texte parlant (l'ordre des mots change quelque peu après la traduction en anglais)
- Qu'il soit possible d'utiliser le texte parlant ou la variable cachée z pour guider la génération de l'action n'est pas encore connue
- MotionGpt sortit la position osseuse, qui ne peut pas être directement connectée à l'animation squelette de l'UE.
- Actuellement, des méthodes simplifiées sont utilisées pour estimer la valeur du mouvement, et il y aura des pertes de position considérables
- Calculez la quantité de changement de rotation de l'os par rapport au nœud parent (Quaternion)
- Envoyez-le au programme VMCTOMOP via le protocole OSC, et prévisualisez l'animation et effectuez la conversion du protocole
- Carte les données de MOP à Metahuman à l'aide du plugin MOP
- La version de test est UE5.3
audio2 photoréal
- Modifiez sur la base du projet d'origine, exportez les données d'animation vers les fichiers locaux pendant l'inférence de l'interface Web
- Processus d'exportation
- Code https://github.com/see2023/audio2photoreal
Énoncé original de Bert-Vits2
VITS2 DRACKINE avec bert multilingue
Pour le guide rapide, veuillez consulter webui_preprocess.py .
Pour un tutoriel simple, voir webui_preprocess.py .
Veuillez noter que l'idée principale de ce projet vient d'Anyvoiceai / Masstts un très bon projet TTS
Demo de démonstration de Masstts pour la version AI de Feng Ge, et a retrouvé sa taille perdue dans le triangle d'or
Traveler / Trail Blazers / Captain / Doctor / Sensei / Wormurhunter / Meowloon / V devrait se référer au code pour apprendre à s'entraîner vous-même.
Il est strictement interdit d'utiliser ce projet à toutes fins qui viole la constitution de la République populaire de Chine, le droit pénal de la République populaire de Chine, la loi de punition de la République populaire de Chine et le Code civil de la République populaire de Chine.
Il est strictement interdit à tout but politiquement lié.
Vidéo: https: //www.bilibili.com/video/bv1hp4y1k78e
Demo: https://www.bilibili.com/video/bv1tf411k78w
Références
- Anyvoiceai / Masstts
- Jaywalnut310 / VITS
- p0p4k / vits2_pytorch
- svc-developpe-équipe / so-vits-svc
- Paddlepaddle / paddlespeech
- vits émotionnels
- pêcheur
- Bert-vits2-ui
Merci à tous les contributeurs pour leurs efforts


