การแนะนำ
- วัตถุประสงค์ของโครงการนี้คือการขยายขอบเขตการใช้งานของ BERT-VITS2 เช่น TTS สร้างข้อมูลการแสดงออกทางสีหน้าแบบซิงโครนัส
- ดูเอฟเฟกต์
- Demo Bilibili Youtube
- TTS กับ Audio2photoreal -> metahuman
- สร้างการทดสอบอิโมติคอนจากการร้องเพลง; การเปรียบเทียบอิโมติคอนเมื่อพูดคุยกับ Azure TTS
- TTS สร้าง Emoji เวอร์ชันแรกที่ติดตั้ง MotionGpt
ขยายไปสู่ cosyvoice
- การทดสอบ cosyvoice emoticon
ขยายไปสู่ GPT-Sovits
- การทดสอบการแสดงออกของ GPT-Sovits
- การฝึกอบรมโดยตรงบน gpt-sovits ผลการทดสอบจริงค่อนข้างไม่ดี
- วิธีการชั่วคราวคือการคัดลอกส่วนหลังและโมเดลการสร้างส่วนนิพจน์โดยตรงจาก Bert-VITS2-EXT ไปยัง GPT-Sovits สำหรับการทดสอบ
- ส่งผลให้เกิดการคำนวณซ้ำและการคาดการณ์มากขึ้น
TTS
รหัส TTS มีต้นกำเนิดมาจาก BERT-VITS2 v2.3 รีลีสสุดท้าย [20 ธ.ค. 2023]
- https://github.com/fishaudio/bert-vits2/commit/7EBC1AA28A055608F7E31DA93928CF295FDFFEBA
หลังจากการทดสอบฉันรู้สึกว่าผลการฝึกอบรมของวัสดุจีนบริสุทธิ์ 2.1-2.3 นั้นแย่กว่า 1.0 เล็กน้อย คุณสามารถพิจารณาลดรุ่นหรือผสมกับจีนบริสุทธิ์
วิธีการฝึกอบรมของ TTS นั้นแสดงในข้อความต้นฉบับ (แต่ละรุ่นแตกต่างกัน)
- แนะนำเวอร์ชัน 1.0 https://github.com/yyux-1145/bert-vits2-integration-package
TTS Synchronous เอาท์พุทอิโมจิ
ความคิด
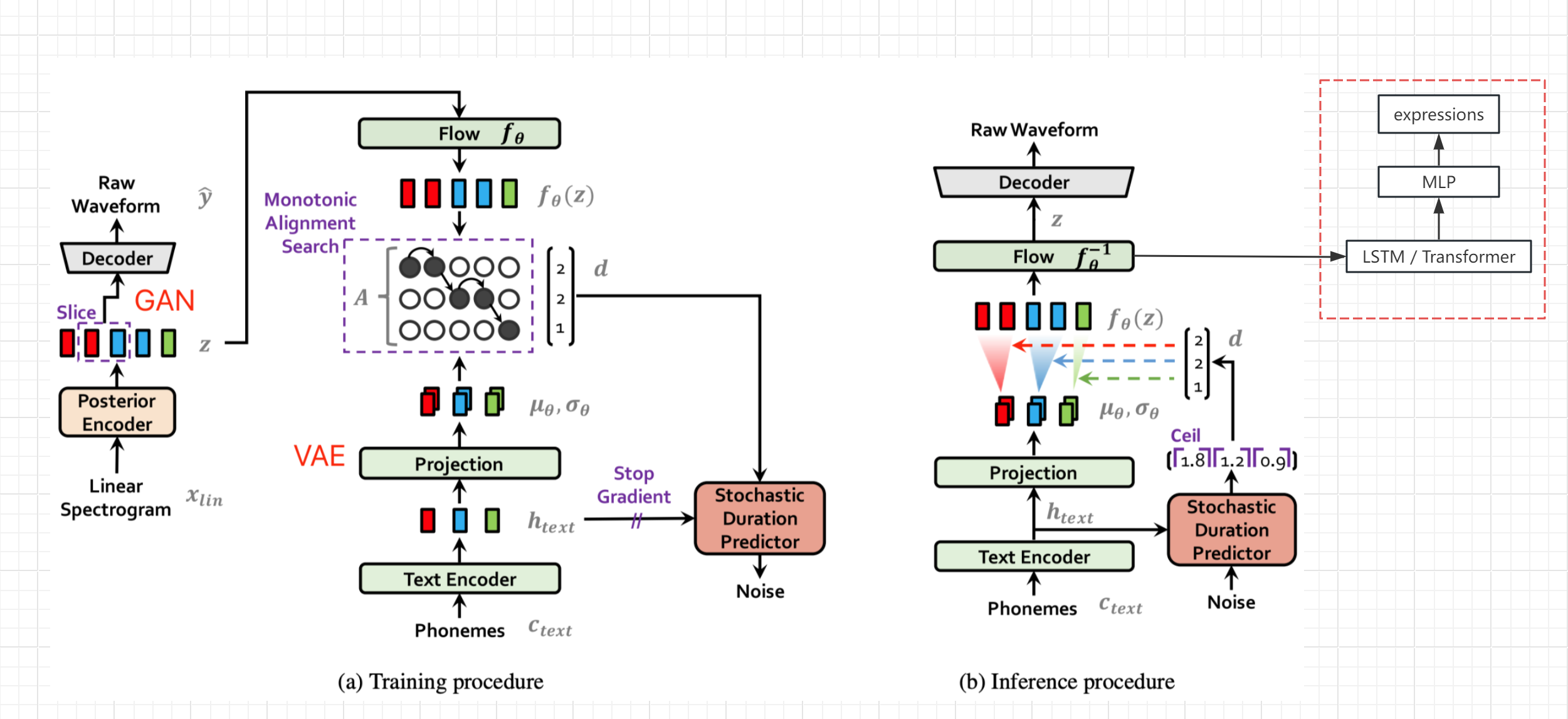
- อ้างถึงแผนภาพโครงสร้างเครือข่ายของกระดาษ VITS (ไม่ใช่ Bert-VITS2 แต่โครงสร้างทั่วไปเหมือนกัน) รับตัวแปรที่ซ่อนอยู่ Z หลังจากการเข้ารหัสข้อความและการแปลงและก่อนการถอดรหัสและส่งออกค่านิพจน์จากบายพาส
- ตรึงพารามิเตอร์ของเครือข่ายดั้งเดิมเพิ่มการประมวลผล LSTM และ MLP แยกกันและการสร้าง SEQ2SEQ ที่สมบูรณ์และการแมปของ Z-to-Expression
- แน่นอนหากมีข้อมูลการแสดงออกที่มีคุณภาพสูงการแสดงออกสามารถเพิ่มลงในการฝึกอบรมเครือข่าย TTS ดั้งเดิมซึ่งควรปรับปรุงคุณภาพเสียง
การรวบรวมข้อมูล
- ตั้งค่าเป้าหมายของ Live Link เผชิญกับ IP ดั้งเดิมและค่าเริ่มต้นพอร์ตเป็น 11111
- รวบรวมเสียงแบบซิงโครนัสและเอาต์พุตค่านิพจน์ที่สอดคล้องกันโดยลิงก์สดและจัดเก็บไว้ในโฟลเดอร์ระเบียนตามลำดับ
- ดำเนินการคอลเลกชันสคริปต์เป็นเวลา 20 วินาทีในแต่ละครั้ง
- เสียงเริ่มต้นเป็น 44100 Hz
- การรวบรวมเสียงและนิพจน์อาจถูกชดเชย
- การเปรียบเทียบการสูญเสียของการตรวจสอบที่ตั้งไว้เพื่อค้นหาตำแหน่งออฟเซ็ตที่ดีที่สุดสำหรับแหล่งข้อมูลเดียวกัน
python ./motion/record.py
python ./motion/tts2ue.py --bs_npy_file ./records/2023-12-23-17-19-54.npy --wav_file ./records/2023-12-23-17-19-54.wav --fps 60
การประมวลผลข้อมูลล่วงหน้า
- อ่านไฟล์เสียงทั้งหมดในระเบียนใช้ตัวเข้ารหัสด้านหลังเพื่อจัดเก็บตัวแปรที่ซ่อนอยู่ Z ที่เข้ารหัสโดยเสียงลงใน *.z.npy
- เขียนถึงรายการไฟล์สำหรับการฝึกอบรมและการตรวจสอบ
- FilesLists/val_visemes.list
- FilesLists/train_visemes.list
python ./motion/prepare_visemes.py
รถไฟ
- เพิ่ม -visemes หลังจาก train_ms.py เพื่อแยกความแตกต่างระหว่างการฝึกอบรมจาก mainnet
python train_ms.py -m OUTPUT_MODEL --config ./configs/config.json --visemes
การให้เหตุผล
- เมื่อมีการดำเนินการ webui.py เสียงเอาต์พุตตัวแปรที่ซ่อนอยู่และข้อมูลภาพเคลื่อนไหวจะถูกเขียนไปยังไดเรกทอรีปัจจุบัน คุณสามารถใช้ tts2ue.py เพื่อดูเอฟเฟกต์ที่สร้างขึ้น
- FPS เริ่มต้นของภาพเคลื่อนไหวที่สร้างขึ้นนั้นเหมือนกับตัวแปรที่ซ่อนอยู่ 86.1328125
- 44100/86.1328125 = 512 เพียงแค่หารด้วยความถี่การสุ่มตัวอย่างเสียง Bert-VITS2 โครงสร้างเครือข่ายและ hidden_channels
python ./motion/tts2ue.py --bs_npy_file ./tmp.npy --wav_file ./tmp.wav --delay_ms 700
เสียงที่จะแสดงออก
- ใช้ตัวเข้ารหัสด้านหลังเพื่อแปลงเสียงเป็น z จากนั้นแปลง Z เป็นนิพจน์
- เสียงจะต้องถูกแปลงเป็นไฟล์ 44100Hz WAV และมีเพียงช่องเดียวเท่านั้นที่ถูกเก็บรักษาไว้ (FFMPEG)
# 音频截取转换
ffmpeg -i input_file -ss 00:00:00 -t 00:00:10 -ar 44100 -f wav test.wav
# 保留通道1
ffmpeg -i test.wav -map_channel 0.0.0 output.wav
python ./motion/wav_to_visemes.py output.wav
อนิเมชั่นร่างกาย
การเคลื่อนไหว
- ด้วยเสียงและการแสดงออกคุณยังสามารถสร้างคำอธิบายการกระทำที่ตรงกันภายใต้ไดรฟ์ LLM จากนั้นใช้รูปแบบข้อความกับโมเดลการเคลื่อนไหวเพื่อสร้างภาพเคลื่อนไหวของร่างกายที่ตรงกับเนื้อหาคำพูดและแม้แต่โต้ตอบกับฉากและอื่น ๆ
- โครงการที่ใช้สำหรับการทดสอบข้อความเพื่อการเคลื่อนไหวคือ MotionGpt
- ยังไม่มีการประมวลผลภาพเคลื่อนไหวมากเกินไป การเคลื่อนไหวในระหว่างนั้นได้รับการสนับสนุนโดยรูปแบบการแนะนำ
- Flan-T5-base ที่ใช้โดย MotionGpt ไม่สามารถเข้าใจภาษาจีนได้ดังนั้นจึงไม่สามารถสร้างภาพเคลื่อนไหวด้วยการซิงโครไนซ์สูงกับข้อความการพูด (คำสั่งซื้อการเปลี่ยนแปลงค่อนข้างหลังจากการแปลเป็นภาษาอังกฤษ)
- ไม่ว่าจะเป็นไปได้ที่จะใช้ข้อความที่พูดหรือตัวแปรที่ซ่อนอยู่ Z เพื่อเป็นแนวทางในการสร้างการกระทำยังไม่ทราบ
- MotionGpt ส่งออกตำแหน่งกระดูกซึ่งไม่สามารถเชื่อมต่อโดยตรงกับภาพเคลื่อนไหวโครงกระดูกของ UE
- ปัจจุบันวิธีการที่ง่ายขึ้นจะใช้ในการประเมินค่าการเคลื่อนไหวและจะมีการสูญเสียตำแหน่งจำนวนมาก
- คำนวณปริมาณการเปลี่ยนแปลงการหมุนของกระดูกที่สัมพันธ์กับโหนดหลัก (quaternion)
- ส่งไปยังโปรแกรม VMCTOMOP ผ่านโปรโตคอล OSC และดูตัวอย่างภาพเคลื่อนไหวและดำเนินการแปลงโปรโตคอล
- แผนที่ข้อมูล MOP ไปยัง metahuman ด้วยความช่วยเหลือของปลั๊กอิน MOP
Audio2photoreal
- แก้ไขบนพื้นฐานของโครงการดั้งเดิมส่งออกข้อมูลภาพเคลื่อนไหวไปยังไฟล์ท้องถิ่นระหว่างการอนุมานเว็บอินเตอร์เฟส
- กระบวนการส่งออก
- รหัส https://github.com/see2023/audio2photoreal
คำสั่งดั้งเดิมของ Bert-Vits2
vits2 backbone กับ bert หลายภาษา
สำหรับคู่มือด่วนโปรดดูที่ webui_preprocess.py
สำหรับบทช่วยสอนง่าย ๆ ดู webui_preprocess.py
โปรดทราบว่าแนวคิดหลักของโครงการนี้มาจาก Anyvoiceai/Masstts โครงการ TTS ที่ดีมาก
การสาธิตการสาธิตของ Masstts สำหรับ Feng GE เวอร์ชั่น AI และกลับมาที่เอวที่หายไปในสามเหลี่ยมทองคำ
นักเดินทางที่เป็นผู้ใหญ่/เทรลเบลเซอร์/กัปตัน/หมอ/อาจารย์/เวิร์มูร์ฮันเตอร์/meowloon/v ควรอ้างถึงรหัสเพื่อเรียนรู้วิธีการฝึกฝนตัวเอง
มันเป็นสิ่งต้องห้ามอย่างเคร่งครัดที่จะใช้โครงการนี้เพื่อวัตถุประสงค์ทั้งหมดที่ละเมิดรัฐธรรมนูญของสาธารณรัฐประชาชนจีนกฎหมายอาญาของสาธารณรัฐประชาชนจีนกฎหมายการลงโทษของสาธารณรัฐประชาชนจีนและประมวลกฎหมายแพ่งของสาธารณรัฐประชาชนจีน
มันเป็นสิ่งต้องห้ามอย่างเคร่งครัดสำหรับวัตถุประสงค์ที่เกี่ยวข้องกับการเมืองใด ๆ
วิดีโอ: https: //www.bilibili.com/video/bv1hp4y1k78e
ตัวอย่าง: https://www.bilibili.com/video/bv1tf411k78w
การอ้างอิง
- Anyvoiceai/masstts
- jaywalnut310/vits
- p0p4k/vits2_pytorch
- SVC-Develop-Develop-Team/SO-VITS-SVC
- Paddlepaddle/Paddlespeech
- เครื่องดื่มอารมณ์
- การพูดปลา
- bert-vits2-ui
ขอบคุณผู้มีส่วนร่วมทุกคนสำหรับความพยายามของพวกเขา


