導入
- このプロジェクトの目的は、TTSなどのBert-Vits2の使用境界を拡大することです。
- 効果を参照してください
- デモBilibili YouTube
- audio2photorealを備えたTTS->メタフマン
- 歌から絵文字テストを生成します。 Azure TTSと話すときの絵文字の比較
- TTSは、emojiの最初のバージョンを生成し、motiongptを備えています
Cosyvoiceに拡張します
gpt-sovitsに拡張されました
- GPT-SOVITS発現テスト
- GPT-Sovitsについて直接再訓練すると、実際のテスト結果は比較的悪いです
- 一時的な方法は、テストのために、事後部分と発現生成部分モデルをBert-vits2-ExtからGPT-Sovitsに直接コピーすることです。
- これにより、計算が繰り返され、予測が増えます
TTS
TTSコードはBert-Vits2 V2.3最終リリース[2023年12月20日]から発信されました
- https://github.com/fishaudio/bert-vits2/commit/7ebc1aa28a055608f7e31da93928cf295fdffeba
テスト後、私は個人的に、純粋な中国の材料2.1-2.3のトレーニング効果は1.0のトレーニング効果よりもわずかに悪いと感じています。バージョンを削減したり、純粋な中国語と混ぜたりすることを検討できます。
TTS自体のトレーニング方法は、元のテキストに表示されます(各バージョンは異なります)
- 推奨バージョン1.0 https://github.com/yyux-1145/bert-vits2-integration-package
TTS同期出力絵文字
アイデア
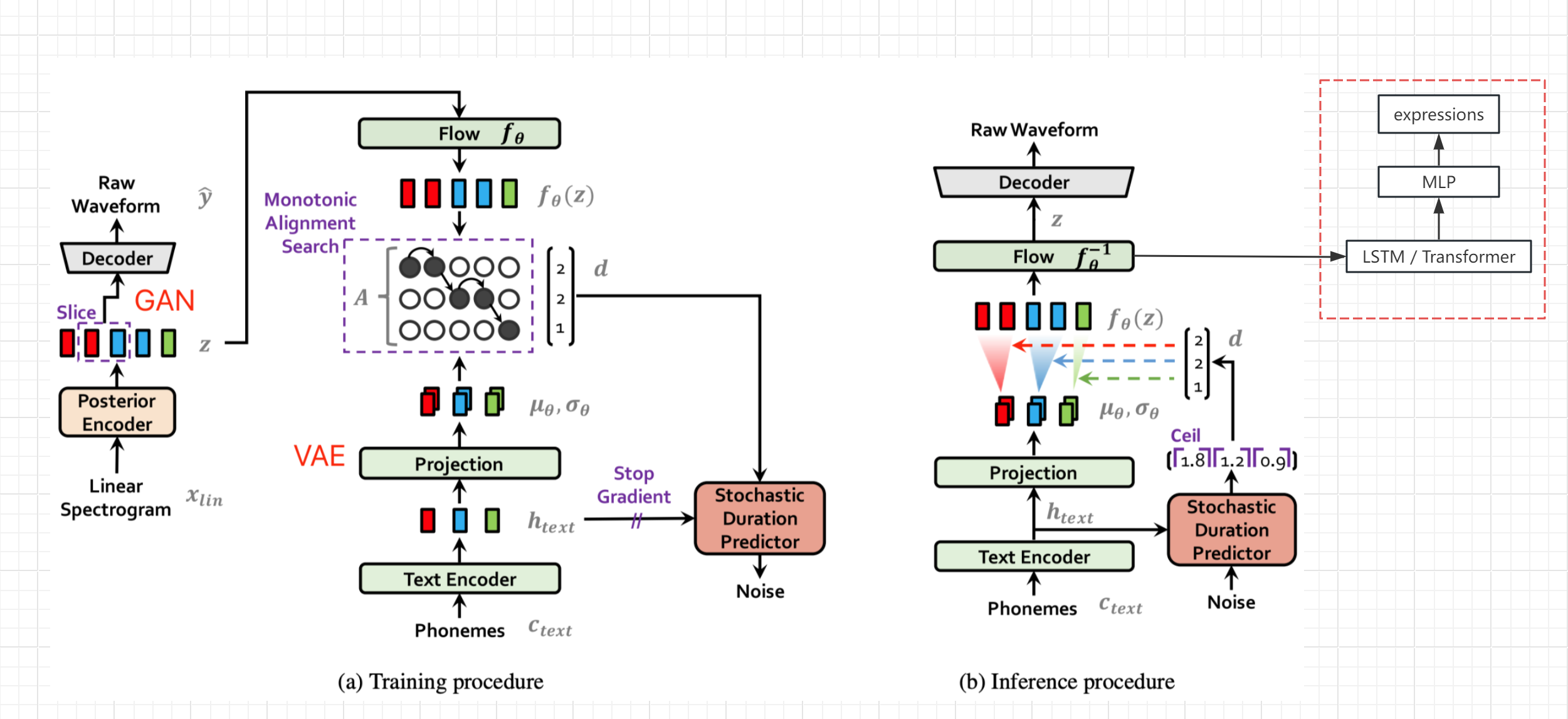
- Vits Paperのネットワーク構造図(Bert-Vits2ではなく、一般的な構造は同じです)を参照し、テキストのエンコードと変換の後に隠された変数zを取得し、解読前にバイパスから式値を出力します(ライブリンク額面値)
- 元のネットワークのパラメーターをフリーズし、LSTMとMLP処理を個別に追加し、z-to-Expressionの完全なSEQ2SEQ生成とマッピング
- もちろん、高品質の式データがある場合、式を元のTTSネットワークトレーニングに追加することもできます。これにより、オーディオ品質が向上するはずです
データ収集
- ライブリンクフェイスのターゲットをネイティブIPに設定すると、ポートがデフォルトで11111になります
- ライブリンクで音声と対応する式値出力を同期して収集し、それぞれレコードフォルダーに保存します
- スクリプトコレクションを毎回20秒間実行します
- オーディオのデフォルトは44100 Hzです
- オーディオと表現のコレクションはオフセットされる場合があります
- 同じデータソースの最適なオフセット位置を見つけるための検証セットの損失の比較
python ./motion/record.py
データが正常かどうかを確認してください
テストデータ
- 録音されたBSデータをライブリンクを介してUEのメタヒューマンに送信し、音声を同期して再生し、一致するかどうかを確認します
python ./motion/tts2ue.py --bs_npy_file ./records/2023-12-23-17-19-54.npy --wav_file ./records/2023-12-23-17-19-54.wav --fps 60
データの前処理
- すべてのオーディオファイルをレコード内の読み取り、後方エンコーダーを使用して、オーディオによってエンコードされた非表示変数zを *.z.npyに保存します
- トレーニングと検証のためにファイルのリストに書き込む
- fileslists/val_visemes.list
- fileslists/train_visemes.list
python ./motion/prepare_visemes.py
電車
- train_ms.pyの後のadd -visemesメインネットとトレーニングを区別する
python train_ms.py -m OUTPUT_MODEL --config ./configs/config.json --visemes
推論
- Webui.pyが実行されると、出力オーディオ、非表示変数、およびアニメーションデータが現在のディレクトリに書き込まれます。 TTS2UE.PYを使用して、生成された効果を表示できます
- 生成されたアニメーションのデフォルトのFPSは、非表示変数86.1328125と同じです
- 44100/86.1328125 = 512、分割可能、これはBert-vits2オーディオサンプリング頻度、ネットワーク構造、hidden_channelsによって決定されます
python ./motion/tts2ue.py --bs_npy_file ./tmp.npy --wav_file ./tmp.wav --delay_ms 700
声から表現
- 後部エンコーダーを使用してサウンドをzに変換し、zを式に変換します
- オーディオは44100Hz WAVファイルに変換する必要があり、1つのチャネルのみが保持されます(ffmpeg)
# 音频截取转换
ffmpeg -i input_file -ss 00:00:00 -t 00:00:10 -ar 44100 -f wav test.wav
# 保留通道1
ffmpeg -i test.wav -map_channel 0.0.0 output.wav
python ./motion/wav_to_visemes.py output.wav
ボディアニメーション
motiongpt
- 音声と表現を使用すると、LLMドライブの下で一致するアクションの説明を生成し、テキストからモーションモデルを使用して、音声コンテンツに一致するボディアニメーションを生成し、シーンやその他とやり取りすることもできます。
- テキストからモーションテストに使用されるプロジェクトはmotiongptです
- アニメーションのオーバー処理はまだ行われていません。その間の動きは、導入モデルによってサポートされています。
- MotionGPTが使用するFLAN-T5ベースは中国語を理解できないため、話すテキストとの高い同期を伴うアニメーションを生成することはできません(英語への翻訳後には、語順はいくらか変わります)
- 話すテキストまたは非表示変数zを使用してアクションの生成を導くことができるかどうかはまだわかっていません
- MotionGptは、UEのスケルトンアニメーションに直接接続することはできません。
- 現在、単純化された方法は移動値を推定するために使用されており、かなりの位置損失があります
- 親ノード(Quaternion)に対する骨の回転変化の量を計算する
- OSCプロトコルを介してVMCTOMOPプログラムに送信し、アニメーションをプレビューし、プロトコル変換を実行します
- MOPプラグインの助けを借りて、MOPデータをメタフマンにマップします
audio2photoreal
- 元のプロジェクトに基づいて変更する、Webインターフェイスの推論中にアニメーションデータをローカルファイルにエクスポートする
- エクスポートプロセス
- コードhttps://github.com/see2023/audio2photoreal
bert-vits2オリジナルステートメント
多言語のバートを備えたVits2バックボーン
クイックガイドについては、 webui_preprocess.pyを参照してください。
簡単なチュートリアルについては、 webui_preprocess.py参照してください。
このプロジェクトの中心的なアイデアは、anyvoiceai/massttsからの非常に良いTTSプロジェクトから来ていることに注意してください
Feng GEのAIバージョン用のMassttsのデモデモ、ゴールデントライアングルで失われた腰を取り戻しました
成熟した旅行者/トレイルブレイザー/キャプテン/ドクター/先生/wormurhunter/meowloon/vは、自分自身を訓練する方法を学ぶためにコードを参照する必要があります。
中華人民共和国憲法、中華人民共和国の刑法、中国人民共和国の罰法、および中国民法に違反するあらゆる目的でこのプロジェクトを使用することは厳密に禁止されています。
政治的に関連する目的のために厳密に禁止されています。
ビデオ:https://www.bilibili.com/video/bv1hp4y1k78e
デモ:https://www.bilibili.com/video/bv1tf411k78w
参照
- anyvoiceai/masstts
- jaywalnut310/vits
- p0p4k/vits2_pytorch
- SVC-Develop-Team/SO-Vits-SVC
- パドルパドル/パドルスピーチ
- 感情的な環境
- 魚のスピーチ
- bert-vits2-ui
すべての貢献者の努力に感謝します


