Introducción
- El propósito de este proyecto es expandir los límites de uso de Bert-VITS2, como TTS que generan datos de expresión facial sincrónicamente.
- Ver el efecto
- Demostración bilibili youtube
- TTS con audio2photoreal -> metahuman
- Generar pruebas de emoticones a partir del canto; Comparación de emoticones al hablar con Azure TTS
- TTS Generó la primera versión de emoji, equipada con MotionGpt
Extenderse a Cosyvoice
- Prueba de emoticón de cosyvoice
Extendido a gpt-sovits
- Prueba de expresión de Sovits GPT
- Ventrenamiento directamente en gpt-sovits, los resultados reales de la prueba son relativamente malos
- El método temporal es copiar directamente la parte posterior y el modelo de pieza de generación de expresión de Bert-VITS2-EXT a GPT-SOVITS para pruebas.
- Esto da como resultado un cálculo repetido y más predicciones
TTS
El código TTS se originó en Bert-VITS2 V2.3 Lanzamiento final [20 de diciembre de 2023]
- https://github.com/fishaudio/bert-vits2/commit/7ebc1aa28a0555608f7e31da93928cf295fdffeba
Después de las pruebas, personalmente siento que el efecto de entrenamiento de los materiales chinos puros 2.1-2.3 es ligeramente peor que el de 1.0. Puede considerar reducir la versión o mezclarla con chino puro.
El método de entrenamiento de TTS en sí se muestra en el texto original (cada versión es diferente)
- Versión recomendada 1.0 https://github.com/yyux-1145/bert-vits2-ingration-package
TTS EMOJI DE SALIDA SINCRONO
Ideas
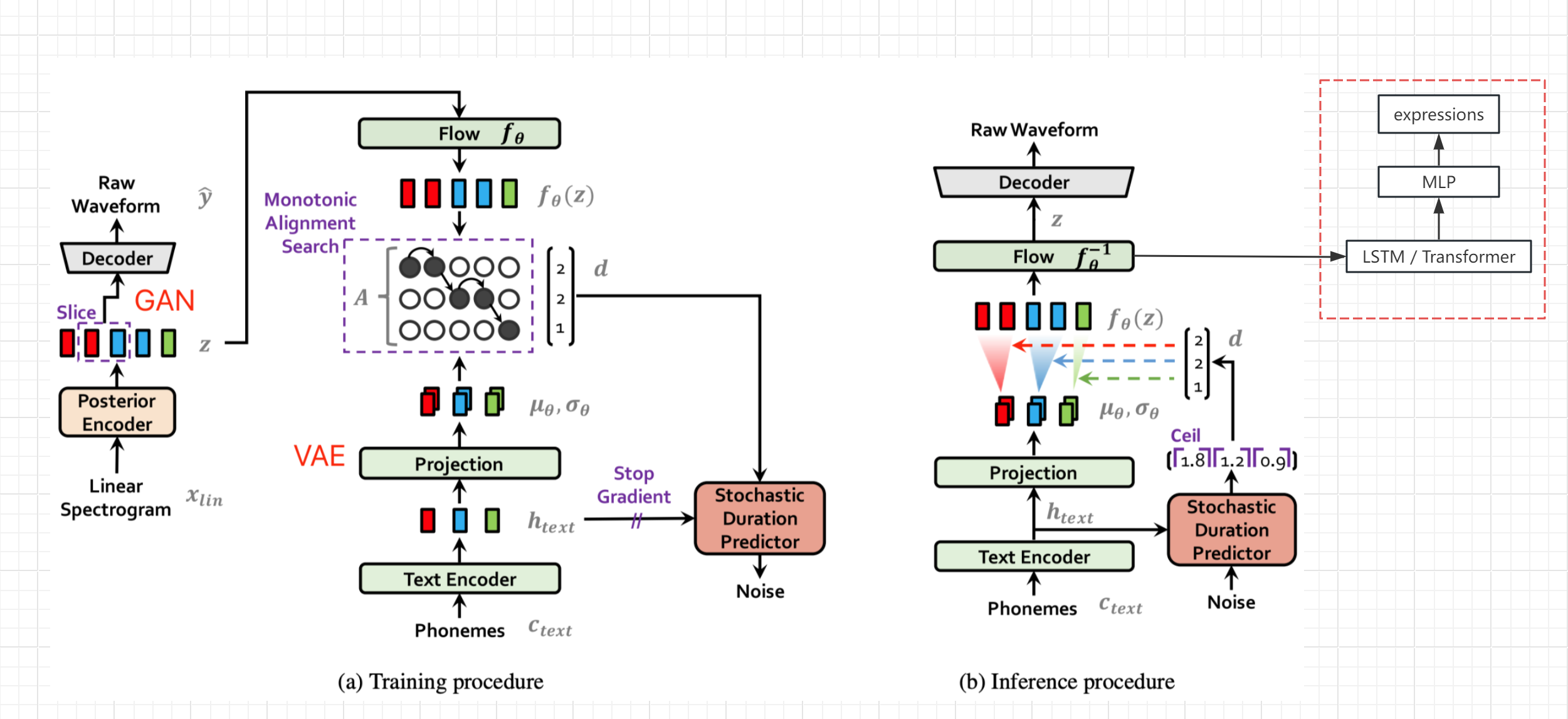
- Consulte el diagrama de la estructura de red del papel VITS (no Bert-VITS2, pero la estructura general es la misma), obtenga la variable Z oculta Z después de la codificación y transformación del texto y antes de decodificar, y generar el valor de expresión del bypass (valor nominal del enlace vivo)
- Congele los parámetros de la red original, agregue el procesamiento de LSTM y MLP por separado, y complete la generación SEQ2SEQ y el mapeo de Z a la expresión
- Por supuesto, si hay datos de expresión de alta calidad, la expresión también se puede agregar al entrenamiento de red TTS original, que debería mejorar la calidad de audio
Recopilación de datos
- Establezca los objetivos del enlace en vivo cara a la IP nativa, y el puerto predeterminado a 11111
- Recopile sincrónicamente los valores de voz y de expresión correspondientes por enlace en vivo, y guárdelos en la carpeta de registros respectivamente
- Ejecutar la colección de script por 20 segundos cada vez
- El valor predeterminado de Audio es 44100 Hz
- La colección de audio y expresión puede compensarse
- Comparación de la pérdida del conjunto de verificación para encontrar la posición de compensación óptima para la misma fuente de datos
python ./motion/record.py
python ./motion/tts2ue.py --bs_npy_file ./records/2023-12-23-17-19-54.npy --wav_file ./records/2023-12-23-17-19-54.wav --fps 60
Preprocesamiento de datos
- Lea todos los archivos de audio en los registros, use el codificador posterior para almacenar la variable Z oculta codificada por el audio en *.z.npy
- Escriba a la lista de archivos para capacitación y verificación.
- archivos lists/val_visemes.list
- FileSlists/Train_Visemes.list
python ./motion/prepare_visemes.py
tren
- Agregar -visualización después de Train_ms.py para distinguir entre el entrenamiento de Mainnet
python train_ms.py -m OUTPUT_MODEL --config ./configs/config.json --visemes
razonamiento
- Cuando se ejecuta Webui.py, el audio de salida, las variables ocultas y los datos de animación se escriben en el directorio actual. Puede usar tts2ue.py para ver el efecto generado
- El FPS predeterminado de la animación generada es la misma que la variable oculta 86.1328125
- 44100/86.1328125 = 512, simplemente divisible, esto está determinado por la frecuencia de muestreo de audio Bert-VITS2, la estructura de red y Hidden_channels
python ./motion/tts2ue.py --bs_npy_file ./tmp.npy --wav_file ./tmp.wav --delay_ms 700
Voz a la expresión
- Use el codificador posterior para convertir el sonido en z, y luego convertir la Z en una expresión
- El audio debe convertirse en un archivo WAV de 44100Hz y solo se conserva un canal (FFMPEG)
# 音频截取转换
ffmpeg -i input_file -ss 00:00:00 -t 00:00:10 -ar 44100 -f wav test.wav
# 保留通道1
ffmpeg -i test.wav -map_channel 0.0.0 output.wav
python ./motion/wav_to_visemes.py output.wav
Animación corporal
Motiongpt
- Con la voz y las expresiones, también puede generar una descripción de acción coincidente en LLM Drive, y luego usar el modelo de texto a movimiento para generar animaciones corporales que coincidan con el contenido del habla, e incluso interactúen con la escena y los demás.
- El proyecto utilizado para las pruebas de texto a movimiento es Motiongpt
- Todavía no se ha hecho sobreprocesamiento de animación. La moción intermedia está respaldada por el modelo de introducción.
- La base Flan-T5 utilizada por MotionGPT no puede entender el chino, por lo que no puede generar animaciones con alta sincronización con texto de habla (el orden de la palabra cambia un poco después de la traducción al inglés)
- Si es posible usar el texto de oratoria o la variable oculta z para guiar la generación de la acción aún no se sabe
- Motiongpt genera la posición ósea, que no se puede conectar directamente a la animación del esqueleto de la UE.
- Actualmente, los métodos simplificados se utilizan para estimar el valor de movimiento, y habrá pérdidas de posición considerables
- Calcule la cantidad de cambio de rotación del hueso en relación con el nodo principal (Cuaternion)
- Envíelo al programa VMCTOMOP a través del protocolo OSC, y previse la animación y realice la conversión del protocolo
- Mapear datos de MOP a Metahuman con la ayuda del complemento MOP
- La versión de prueba es UE5.3
audio2photoreal
- Modificar sobre la base del proyecto original, exportar datos de animación a archivos locales durante la inferencia de la interfaz web
- Proceso de exportación
- Código https://github.com/see2023/audio2photoreal
Declaración original de Bert-VITS2
VITS2 Backbone con Bert multilingüe
Para una guía rápida, consulte webui_preprocess.py .
Para un tutorial simple, consulte webui_preprocess.py .
Tenga en cuenta que la idea central de este proyecto proviene de Anyvoiceai/Masstts un muy buen proyecto TTS
La demostración de demostración de Masstts para la versión AI de Feng Ge, y recuperó su cintura perdida en el Triángulo Dorado
Viajero maduro/blazers de senderos/capitán/doctor/sensei/wormhunter/meowloon/v debe referirse al código para aprender cómo entrenar.
Está estrictamente prohibido utilizar este proyecto para todos los fines que violan la constitución de la República Popular de China, la ley penal de la República Popular de China, la ley de castigo de la República Popular de China y el Código Civil de la República Popular de China.
Está estrictamente prohibido para cualquier propósito políticamente relacionado.
Video: https: //www.bilibili.com/video/bv1hp4y1k78e
Demostración: https://www.bilibili.com/video/bv1tf411k78w
Referencias
- Anyvoiceai/Masstts
- jaywalnut310/vits
- P0P4K/VITS2_PYTORCH
- SVC-Develovel-Team/SO-VITS-SVC
- Paddlepaddle/paldlespech
- vits emocionales
- voz de pescado
- Bert-vits2-ui
Gracias a todos los contribuyentes por sus esfuerzos


