Einführung
- Ziel dieses Projekts ist es, die Nutzungsgrenzen von Bert-Vits2 zu erweitern, wie z.
- Siehe den Effekt
- Demo Bilibili YouTube
- TTS mit Audio2photoreal -> metahuman
- Emoticon -Tests aus dem Singen erzeugen; Vergleich von Emoticons beim Sprechen mit Azure TTs
- TTS erzeugte Emoji erste Version, ausgestattet mit MotionGpt
Bis nach cosyvoice
Erweitert auf GPT-SoVits
- GPT-SoVits Expressionstest
- Die tatsächlichen Testergebnisse sind relativ schlecht
- Die temporäre Methode besteht darin, das posteriore Teil- und Expressionsgenerierungs-Teilmodell direkt von Bert-Vits2-EXTs auf GPT-SoVits zum Testen zu kopieren.
- Dies führt zu einer wiederholten Berechnung und mehr Vorhersagen
TTS
TTS-Code stammt aus Bert-Vits2 V2.3 Endveröffentlichung [20. Dezember 2023]
- https://github.com/fishaudio/bert-vits2/commit/7ebc1aa28a055608f7e31da93928cf295fdffeba
Nach dem Test habe ich persönlich das Gefühl, dass der Trainingseffekt reiner chinesischer Materialien 2.1-2.3 etwas schlechter ist als der von 1,0. Sie können in Betracht ziehen, die Version zu reduzieren oder sie mit reinem Chinesisch zu mischen.
Die Trainingsmethode von TTS selbst wird im Originaltext angezeigt (jede Version ist anders)
- Empfohlene Version 1.0 https://github.com/yyux-1145/bert-vits2-integration-package
TTS Synchron Output Emoji
Ideen
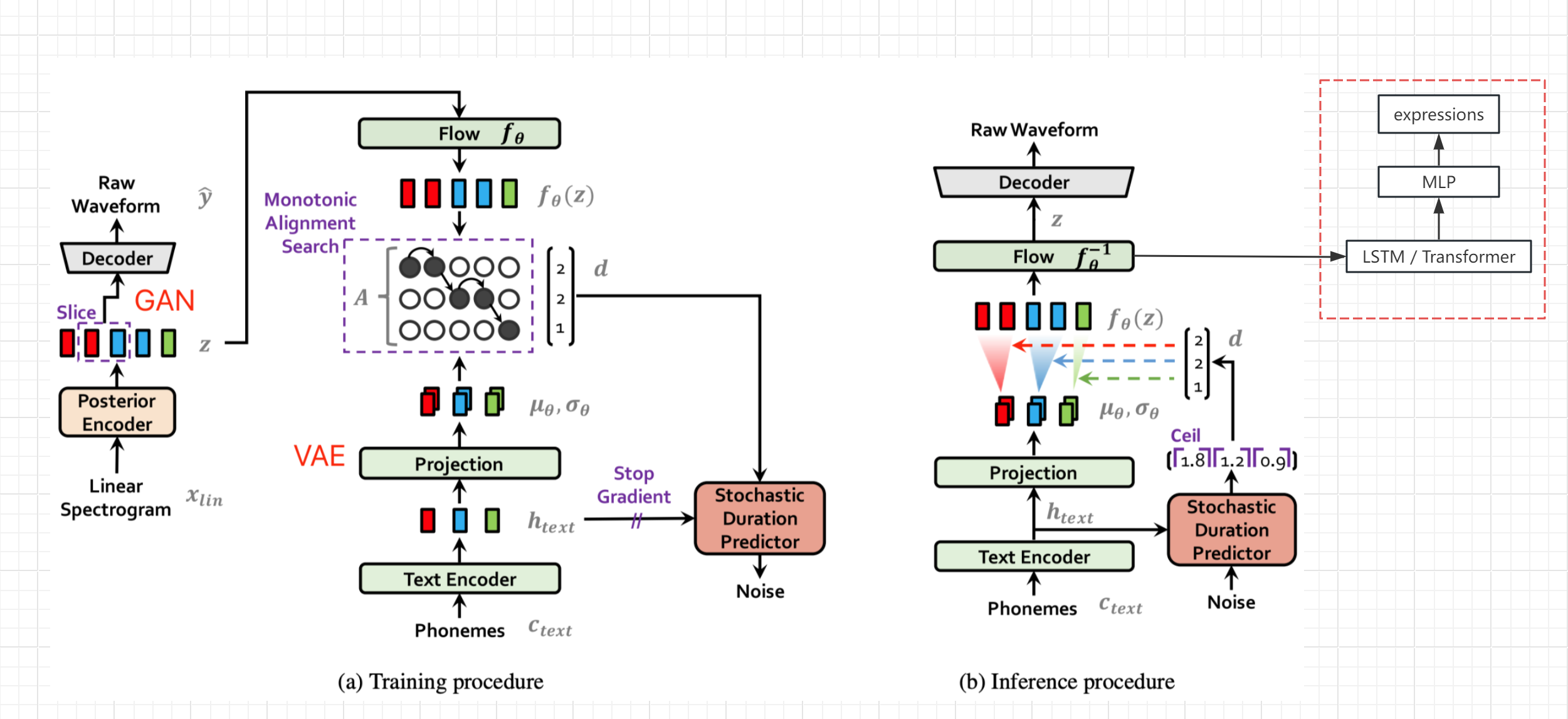
- Siehe das Netzwerkstrukturdiagramm des Vits-Papiers (nicht Bert-vits2, aber die allgemeine Struktur ist gleich), erhalten Sie die verborgene Variable Z nach der Textcodierung und -transformation und vor der Dekodierung und geben Sie den Ausdruckswert aus dem Bypass aus (Live-Link-Nennwert) aus.
- Frieren Sie die Parameter des ursprünglichen Netzwerks ein, fügen Sie die LSTM- und MLP-Verarbeitung separat hinzu und komplette SEQ2SEQ-Generierung und -zuordnung von Z-zu-Expression
- Wenn es hochwertige Expressionsdaten gibt, kann der Ausdruck auch dem ursprünglichen TTS-Netzwerktraining hinzugefügt werden, was die Audioqualität verbessern sollte
Datenerfassung
- Setzen Sie die Ziele des Live -Link -Gesichts zur nativen IP, und der Port wird standardmäßig auf 11111 eingestellt
- Synchron sammeln Sie Sprach- und entsprechende Expressionswerte,
- Führen Sie jedes Mal 20 Sekunden lang die Skriptsammlung aus
- Audio standardmäßig auf 44100 Hz
- Die Audio- und Ausdruckssammlung kann ausgefallen sein
- Vergleich des Verlusts des Bestätigungssatzes, um die optimale Offset -Position für dieselbe Datenquelle zu finden
python ./motion/record.py
python ./motion/tts2ue.py --bs_npy_file ./records/2023-12-23-17-19-54.npy --wav_file ./records/2023-12-23-17-19-54.wav --fps 60
Datenvorverarbeitung
- Lesen Sie alle Audio -Dateien in Datensätzen und speichern Sie den vom Audio codierten versteckten Variablen -z in *.z.npy
- Schreiben Sie in die Liste der Dateien zum Training und zur Überprüfung
- fileSlists/val_visemes.list
- fileSlists/Train_visemes.list
python ./motion/prepare_visemes.py
Zug
- Hinzufügen -Visemes nach Train_ms.py, um zwischen dem Training vom Mainnet zu unterscheiden
python train_ms.py -m OUTPUT_MODEL --config ./configs/config.json --visemes
Argumentation
- Wenn webui.py ausgeführt wird, werden die Ausgabeminus -Audio-, versteckten Variablen und Animationsdaten in das aktuelle Verzeichnis geschrieben. Sie können TTS2Ue.py verwenden, um den generierten Effekt anzuzeigen
- Die Standard -FPS der generierten Animation entspricht der verborgenen Variablen 86.1328125
- 44100/86.1328125 = 512, nur teilbar. Dies wird durch Bert-Vits2 Audio-Stichprobenfrequenz, Netzwerkstruktur und Hidden_Channels bestimmt
python ./motion/tts2ue.py --bs_npy_file ./tmp.npy --wav_file ./tmp.wav --delay_ms 700
Stimme zum Ausdruck
- Verwenden Sie den hinteren Encoder, um den Ton in Z zu konvertieren, und wandeln Sie dann den Z in einen Ausdruck um
- Audio muss in eine 44100Hz -WAV -Datei konvertiert werden und nur ein Kanal wird beibehalten (FFMPEG)
# 音频截取转换
ffmpeg -i input_file -ss 00:00:00 -t 00:00:10 -ar 44100 -f wav test.wav
# 保留通道1
ffmpeg -i test.wav -map_channel 0.0.0 output.wav
python ./motion/wav_to_visemes.py output.wav
Körperanimation
MotionGpt
- Mit Voice and Expressions können Sie auch eine Matching -Aktionsbeschreibung unter LLM -Laufwerk erstellen und dann den Text zum Bewegungsmodell verwenden, um Körperanimationen zu generieren, die dem Sprachinhalt entsprechen, und sogar mit der Szene und anderen interagieren.
- Das Projekt, das für Text -to -Motion -Tests verwendet wird, ist MotionGPT
- Es wurde noch keine Animation überarbeitet. Die Bewegung dazwischen wird durch das Einführungsmodell unterstützt.
- Die von MotionGPT verwendete Flan-T5-Base kann Chinesen nicht verstehen, daher kann sie keine Animationen mit hoher Synchronisation mit Sprechtext generieren (die Wortreihenfolge ändert sich etwas nach der Übersetzung ins Englische).
- MotionGPT gibt die Knochenposition aus, die nicht direkt mit der Skelettanimation des UE verbunden werden kann.
- Derzeit werden vereinfachte Methoden verwendet, um den Bewegungswert abzuschätzen, und es wird erhebliche Positionsverluste geben
- Berechnen Sie die Rotationsänderung des Knochens relativ zum Elternknoten (Quaternion)
- Senden Sie es über das OSC -Protokoll an das VMCTOMOP -Programm und Vorschau der Animation und führen Sie die Protokollkonvertierung durch
- MAP -MOP -Daten nach Metahuman mit Hilfe des MOP -Plugins
- Die Testversion ist UE5.3
Audio2photoreal
- Ändern Sie auf der Grundlage des ursprünglichen Projekts, exportieren Sie Animationsdaten in lokale Dateien während der Inferenz von Weboberflächen
- Exportprozess
- Code https://github.com/see2023/audio2photoreal
Bert-vits2 Originalerklärung
Vits2 Rückgrat mit mehrsprachiger Bert
Für Quick Guide finden Sie bitte webui_preprocess.py .
Für ein einfaches Tutorial finden Sie webui_preprocess.py .
Bitte beachten Sie, dass die Kernidee dieses Projekts von Anyvoiceai/MASTTS ein sehr gutes TTS -Projekt stammt
Mastts 'Demo -Demo für AI -Version von Feng Ge und wiedererlangte seine verlorene Taille im Goldenen Dreieck
Reife Reisende/Trail Blazer/Captain/Doctor/Sensei/Wormurhunter/Meowloon/V sollten sich auf den Code beziehen, um zu erfahren, wie man sich selbst trainiert.
Es ist strengstens untersagt, dieses Projekt für alle Zwecke zu verwenden, die gegen die Verfassung der Volksrepublik China, das Strafrecht der Volksrepublik China, das Strafgesetz der Volksrepublik China und das Zivilgesetzbuch der Volksrepublik China verstoßen.
Es ist ausschließlich für einen politisch verwandten Zweck verboten.
Video: https: //www.bilibili.com/video/bv1hp4y1k78e
Demo: https://www.bilibili.com/video/bv1tf411k78w
Referenzen
- Anyvoiceai/masstts
- Jaywalnut310/vits
- p0p4k/vits2_pytorch
- SVC-Develop-Team/SO-Vits-SVC
- Paddlepaddle/Paddlespeech
- emotionale Vits
- Fischrede
- Bert-vits2-ui
Vielen Dank an alle Mitwirkenden für ihre Bemühungen


