Perkenalan
- Tujuan dari proyek ini adalah untuk memperluas batasan penggunaan Bert-Vits2, seperti TTS yang secara sinkron menghasilkan data ekspresi wajah.
- Lihat efeknya
- Demo Bilibili YouTube
- TT dengan audio2photoreal -> metahuman
- Menghasilkan tes emoticon dari nyanyian; Perbandingan emotikon saat berbicara dengan Azure TTS
- TTS menghasilkan Emoji First Version, dilengkapi dengan MotionGpt
Meluas ke cosyvoice
Diperluas ke GPT-Sovits
- Tes ekspresi GPT-Sovits
- Melatih kembali secara langsung pada GPT-Sovits, hasil tes aktual relatif buruk
- Metode sementara adalah untuk secara langsung menyalin model bagian posterior dan generasi ekspresi dari Bert-Vits2-Ext ke GPT-Sovits untuk pengujian.
- Ini menghasilkan perhitungan berulang dan lebih banyak prediksi
Tts
Kode TTS berasal dari BERT-VITS2 V2.3 Rilis Akhir [20 Des 2023]
- https://github.com/fishaudio/bert-vits2/commit/7ebc1aa28a055608f7e31da93928cf295fdffeba
Setelah pengujian, saya secara pribadi merasa bahwa efek pelatihan bahan Cina murni 2.1-2.3 sedikit lebih buruk daripada 1.0. Anda dapat mempertimbangkan mengurangi versi atau mencampurnya dengan Cina murni.
Metode pelatihan TTS itu sendiri ditampilkan dalam teks asli (setiap versi berbeda)
- Versi 1.0 https://github.com/yyux-1145/bert-vits2-integration-package
Emoji output sinkron
Ide
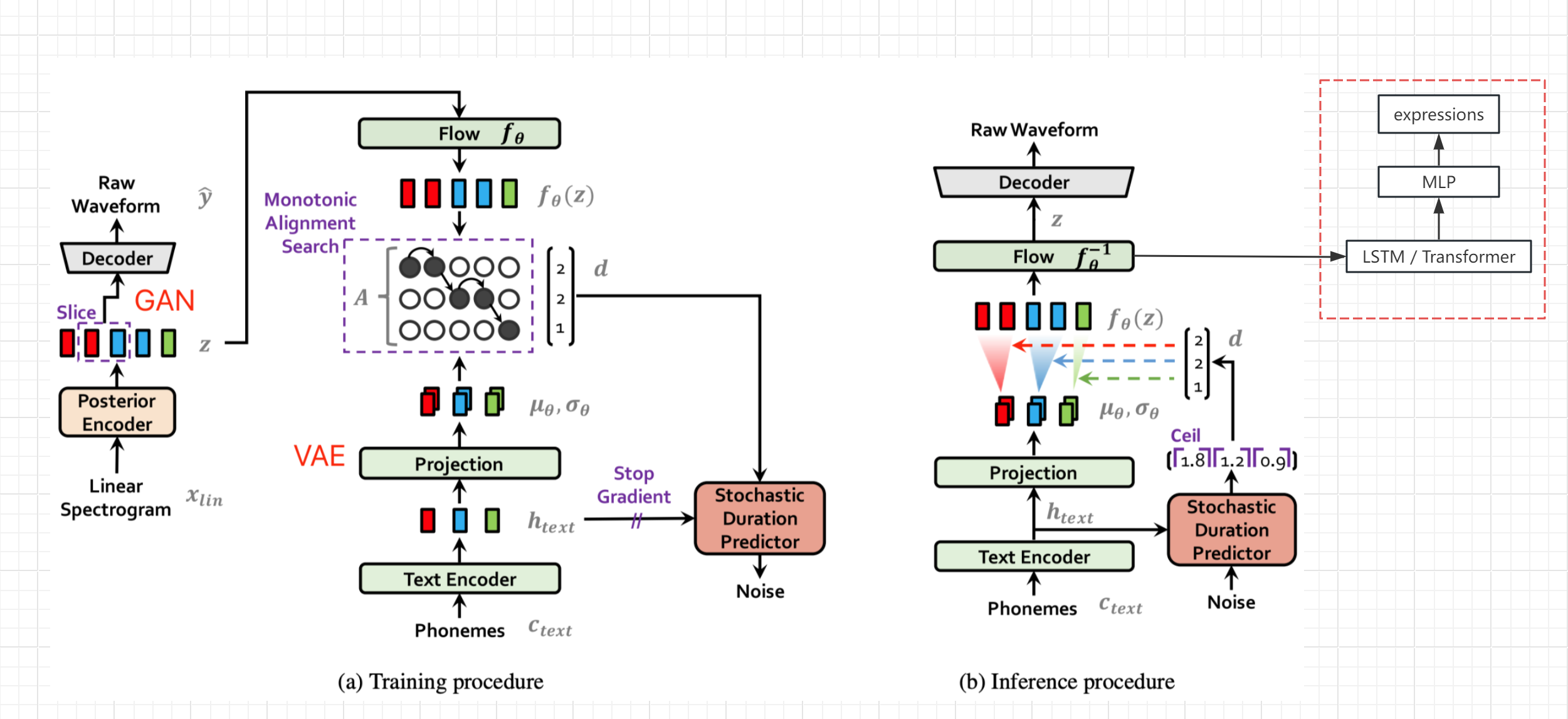
- Lihat Diagram Struktur Jaringan dari Kertas Vits (bukan Bert-Vits2, tetapi struktur umumnya sama), dapatkan variabel tersembunyi Z setelah pengkodean dan transformasi teks dan sebelum decoding, dan output nilai ekspresi dari bypass (nilai tautan langsung)
- Bekukan parameter jaringan asli, tambahkan pemrosesan LSTM dan MLP secara terpisah, dan lengkap pembuatan Seq2seq dan pemetaan z-ke-ekspresi
- Tentu saja, jika ada data ekspresi berkualitas tinggi, ekspresi juga dapat ditambahkan ke pelatihan jaringan TTS asli, yang seharusnya meningkatkan kualitas audio
Pengumpulan data
- Tetapkan target wajah tautan langsung ke IP asli, dan port default ke 11111
- Mengumpulkan suara dan nilai ekspresi yang sesuai dengan tautan langsung, dan menyimpannya ke folder catatan masing -masing
- Jalankan koleksi skrip selama 20 detik setiap kali
- Audio default ke 44100 Hz
- Koleksi audio dan ekspresi mungkin diimbangi
- Perbandingan hilangnya verifikasi yang ditetapkan untuk menemukan posisi offset optimal untuk sumber data yang sama
python ./motion/record.py
python ./motion/tts2ue.py --bs_npy_file ./records/2023-12-23-17-19-54.npy --wav_file ./records/2023-12-23-17-19-54.wav --fps 60
Preprocessing data
- Baca semua file audio dalam catatan, gunakan encoder posterior untuk menyimpan variabel tersembunyi Z yang dikodekan oleh audio ke dalam *.z.npy
- Tulis ke daftar file untuk pelatihan dan verifikasi
- FileSlist/val_visemes.list
- FileSlist/train_visemes.list
python ./motion/prepare_visemes.py
kereta
- Tambahkan --visem setelah train_ms.py untuk membedakan antara pelatihan dari Mainnet
python train_ms.py -m OUTPUT_MODEL --config ./configs/config.json --visemes
pemikiran
- Ketika webui.py dieksekusi, audio output, variabel tersembunyi, dan data animasi ditulis ke direktori saat ini. Anda dapat menggunakan tts2ue.py untuk melihat efek yang dihasilkan
- FP default dari animasi yang dihasilkan sama dengan variabel tersembunyi 86.1328125
- 44100/86.1328125 = 512, cukup dapat dibagi, ini ditentukan oleh frekuensi pengambilan sampel audio Bert-VITS2, struktur jaringan dan hidden_channels
python ./motion/tts2ue.py --bs_npy_file ./tmp.npy --wav_file ./tmp.wav --delay_ms 700
Suara untuk berekspresi
- Gunakan enkoder posterior untuk mengubah suara menjadi z, dan kemudian mengubah z menjadi ekspresi
- Audio perlu dikonversi menjadi file WAV 44100Hz dan hanya satu saluran yang disimpan (FFMPEG)
# 音频截取转换
ffmpeg -i input_file -ss 00:00:00 -t 00:00:10 -ar 44100 -f wav test.wav
# 保留通道1
ffmpeg -i test.wav -map_channel 0.0.0 output.wav
python ./motion/wav_to_visemes.py output.wav
Animasi Tubuh
Motiongpt
- Dengan suara dan ekspresi, Anda juga dapat menghasilkan deskripsi tindakan yang cocok di bawah drive LLM, dan kemudian menggunakan model teks ke gerakan untuk menghasilkan animasi tubuh yang cocok dengan konten ucapan, dan bahkan berinteraksi dengan adegan dan lainnya.
- Proyek yang digunakan untuk pengujian teks untuk bergerak adalah MotionGpt
- Belum ada berlebihan animasi yang dilakukan. Gerakan di antara didukung oleh model pengantar.
- Flan-T5-base yang digunakan oleh MotionGpt tidak dapat memahami bahasa Mandarin, sehingga tidak dapat menghasilkan animasi dengan sinkronisasi tinggi dengan teks berbicara (kata urutan kata sedikit setelah diterjemahkan ke dalam bahasa Inggris)
- Apakah mungkin untuk menggunakan teks berbicara atau variabel tersembunyi z untuk memandu pembuatan tindakan belum diketahui
- MotionGpt mengeluarkan posisi tulang, yang tidak dapat terhubung langsung ke animasi kerangka UE.
- Saat ini, metode yang disederhanakan digunakan untuk memperkirakan nilai pergerakan, dan akan ada kerugian posisi yang cukup besar
- Hitung jumlah perubahan rotasi tulang relatif terhadap simpul induk (quaternion)
- Kirimkan ke program vmctomop melalui protokol OSC, dan pratinjau animasi dan lakukan konversi protokol
- Peta data pelayaran ke Metahuman dengan bantuan plugin MOP
Audio2Photoreal
- Ubah berdasarkan proyek asli, ekspor data animasi ke file lokal selama inferensi antarmuka web
- Proses ekspor
- Kode https://github.com/see2023/audio2photoreal
Pernyataan asli Bert-Vits2
Tulang punggung vits2 dengan Bert multibahasa
Untuk panduan cepat, silakan merujuk ke webui_preprocess.py .
Untuk tutorial sederhana, lihat webui_preprocess.py .
Harap dicatat bahwa ide inti dari proyek ini berasal dari Anyvoiceai/Masstts proyek TTS yang sangat bagus
Demo demo masstts untuk AI versi feng ge, dan mendapatkan kembali pinggangnya yang hilang di segitiga emas
Traveler dewasa/jejak blazer/kapten/dokter/sensei/wormurhunter/meowloon/v harus merujuk pada kode untuk belajar cara melatih diri sendiri.
Sangat dilarang untuk menggunakan proyek ini untuk semua tujuan yang melanggar konstitusi Republik Rakyat Tiongkok, hukum pidana Republik Rakyat Tiongkok, Hukum Hukum Republik Rakyat Tiongkok, dan KUH Perdata Republik Rakyat Tiongkok.
Ini sangat dilarang untuk tujuan yang terkait secara politis.
Video: https: //www.bilibili.com/video/bv1hp4y1k78e
Demo: https://www.bilibili.com/video/bv1tf411k78w
Referensi
- anyvoiceai/masstts
- jaywalnut310/vits
- p0p4k/vits2_pytorch
- SVC-Develop-Team/So-Vits-SVC
- Paddlepaddle/Paddlespeech
- Vok emosional
- pidato ikan
- Bert-vits2-ui
Terima kasih kepada semua kontributor atas upaya mereka


