Introdução
- O objetivo deste projeto é expandir os limites de uso do BERT-VITS2, como o TTS gerando síncronemente dados de expressão facial.
- Veja o efeito
- Demo Bilibili YouTube
- TTS com Audio2photoreal -> Metahuman
- Gerar testes de emoticon com canto; Comparação de emoticons ao falar com o Azure TTS
- A TTS gerou a primeira versão emoji, equipada com MotionGPT
Estenda -se ao cosyvoice
- Teste de emoticon cosyvoice
Estendido a Sovits GPT
- Teste de expressão GPT-Sovits
- Reciclando diretamente nas provas do GPT, os resultados reais dos testes são relativamente ruins
- O método temporário é copiar diretamente o modelo de peça de parte posterior e geração de expressão de Bert-Vits2-EXT para as fontes GPT para teste.
- Isso resulta em um cálculo repetido e mais previsões
TTS
Código TTS originado de Bert-Vits2 v2.3 Release final [20 de dezembro de 2023]
- https://github.com/fishaudio/bert-vits2/commit/7ebc1aa28a055608f7e31da93928cf295fdffeba
Após o teste, pessoalmente sinto que o efeito de treinamento dos materiais chineses puros 2.1-2.3 é um pouco pior que o de 1,0. Você pode considerar reduzir a versão ou misturá -la com chinês puro.
O método de treinamento do próprio TTS é mostrado no texto original (cada versão é diferente)
- Versão recomendada 1.0 https://github.com/yyux-1145/bert-vits2-integration-package
Emoji de saída síncrona TTS
Idéias
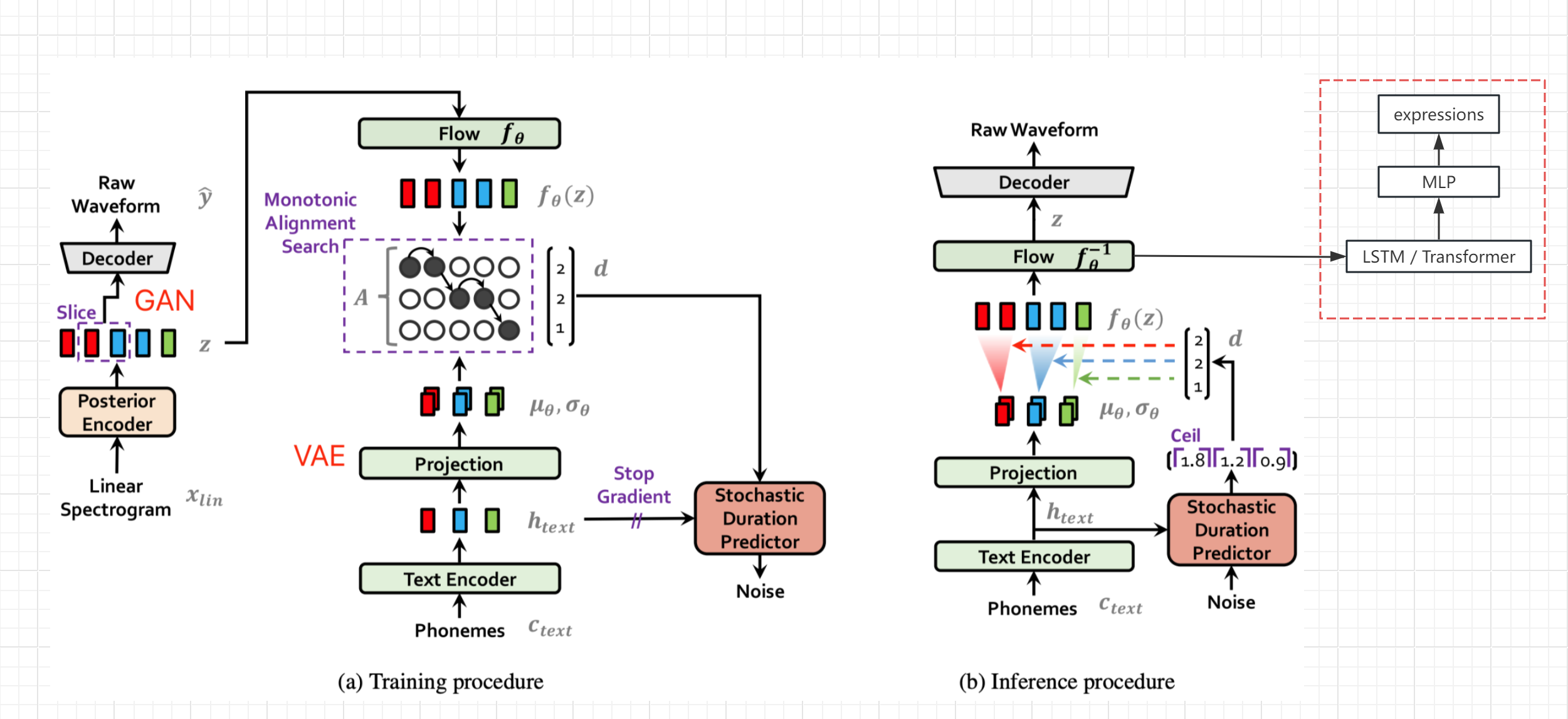
- Consulte o diagrama da estrutura da rede do papel Vits (não BERT-VITS2, mas a estrutura geral é a mesma), obtenha a variável oculta z após a codificação e transformação do texto e antes da decodificação e produza o valor da expressão do desvio (valor face do link vivo)
- Congele os parâmetros da rede original, adicione o processamento LSTM e MLP separadamente e complete a geração Seq2SEQ e o mapeamento de Z-to-Expression
- Obviamente, se houver dados de expressão de alta qualidade, a expressão também poderá ser adicionada ao treinamento original da rede TTS, o que deve melhorar a qualidade do áudio
Coleta de dados
- Defina os alvos do link ao vivo para o IP nativo, e a porta padrão para 11111
- Colete de maneira síncrona e os valores de expressão correspondentes em saída por link ao vivo e armazenam -os na pasta Records, respectivamente
- Execute a coleção de scripts por 20 segundos cada vez
- Padrões de áudio para 44100 Hz
- A coleção de áudio e expressão pode ser deslocada
- Comparação da perda do conjunto de verificação para encontrar a posição de deslocamento ideal para a mesma fonte de dados
python ./motion/record.py
python ./motion/tts2ue.py --bs_npy_file ./records/2023-12-23-17-19-54.npy --wav_file ./records/2023-12-23-17-19-54.wav --fps 60
Pré -processamento de dados
- Leia todos os arquivos de áudio nos registros, use o codificador posterior para armazenar a variável oculta z codificada pelo áudio em *.z.npy
- Escreva na lista de arquivos para treinamento e verificação
- Listas de arquivos/val_visemes.list
- Listas de arquivos/trens_visemes.list
python ./motion/prepare_visemes.py
trem
- Adicione --Visemes After Train_ms.py para distinguir entre o treinamento da Mainnet
python train_ms.py -m OUTPUT_MODEL --config ./configs/config.json --visemes
raciocínio
- Quando o webui.py é executado, o áudio de saída, as variáveis ocultas e os dados de animação são gravados no diretório atual. Você pode usar tts2ue.py para ver o efeito gerado
- O FPS padrão da animação gerada é a mesma que a variável oculta 86.1328125
- 44100/86.1328125 = 512, apenas divisível, isso é determinado pela frequência de amostragem de áudio bert-vits2, estrutura de rede e hidden_channels
python ./motion/tts2ue.py --bs_npy_file ./tmp.npy --wav_file ./tmp.wav --delay_ms 700
Voz para expressão
- Use o codificador posterior para converter o som em z e depois converta o z em uma expressão
- O áudio precisa ser convertido em um arquivo WAV de 44100Hz e apenas um canal é retido (FFMPEG)
# 音频截取转换
ffmpeg -i input_file -ss 00:00:00 -t 00:00:10 -ar 44100 -f wav test.wav
# 保留通道1
ffmpeg -i test.wav -map_channel 0.0.0 output.wav
python ./motion/wav_to_visemes.py output.wav
Animação corporal
MotionGPT
- Com voz e expressões, você também pode gerar uma descrição de ação correspondente no LLM Drive e, em seguida, usar o modelo de texto para gerar animações corporais que combinam com o conteúdo da fala e até interagem com a cena e outros.
- O projeto usado para testes de texto para movimento é MotionGPT
- Não foi feito superprocessamento de animação ainda. O movimento intermediário é suportado pelo modelo de introdução.
- A flan-t5-Base usada pelo MotionGPT não pode entender os chineses, por isso não pode gerar animações com alta sincronização com o texto de fala (a ordem das palavras muda um pouco após a tradução para o inglês)
- Se é possível usar o texto falado ou a variável oculta z para orientar a geração da ação ainda não é conhecida
- O MotionGPT produz a posição óssea, que não pode ser conectada diretamente à animação esqueleto do UE.
- Atualmente, métodos simplificados são usados para estimar o valor do movimento, e haverá consideráveis perdas de posição
- Calcule a quantidade de mudança de rotação do osso em relação ao nó pai (quaternion)
- Envie -o para o programa VMCTOMOP através do protocolo OSC e visualize a animação e execute a conversão de protocolos
- Map MOP Data para Metahuman com a ajuda do plug -in MOP
- A versão de teste é UE5.3
AUDIO2PHOTERAL
- Modificar com base no projeto original, exportar dados de animação para arquivos locais durante a inferência da interface da web
- Processo de exportação
- Código https://github.com/see2023/audio2photoreal
BERT-VITS2 Declaração original
Vits2 Backbone com Bert multilíngue
Para guia rápido, consulte webui_preprocess.py .
Para um tutorial simples, consulte webui_preprocess.py .
Observe que a idéia principal deste projeto vem de Anyvoiceai/Masstts, um projeto TTS muito bom
A demonstração da demonstração de Masstts para a versão Ai do Feng ge e recuperou sua cintura perdida no Triângulo Dourado
Blazers de viajante/trilha maduros/capitão/médico/sensei/wormurhunter/meowloon/v devem se referir ao código para aprender a se treinar.
É estritamente proibido usar este projeto para todos os propósitos que violam a Constituição da República Popular da China, a lei criminal da República Popular da China, a lei de punição da República Popular da China e o Código Civil da República Popular da China.
É estritamente proibido para qualquer propósito politicamente relacionado.
Vídeo: https: //www.bilibili.com/video/bv1hp4y1k78e
Demo: https://www.bilibili.com/video/bv1tf411k78w
Referências
- Anyvoiceii/Masstts
- JAYWALNUT310/VITS
- p0p4k/vits2_pytorch
- SVC-develop-Team/So-Vits-SVC
- Paddlepaddle/Paddlespeech
- Vits emocionais
- Fuls-fala
- BERT-VITS2-UI
Obrigado a todos os colaboradores por seus esforços


