EXTRACT
1.0.0
提取物是各種操作系統的光學角色識別引擎,可從圖像中提取文本並將其轉換為純文本。
該模型是原始的Google Tesseract的一種非常原始的形式,它從圖像中提取文本(僅大寫字母)並將其轉換為純文本。
Note1: - 未提供訓練的模型。因此,這是第一次運行腳本。訓練模型後:註釋“ Train_model”在“ 65”上,然後運行腳本以進行進一步使用。
Note2: - 僅考慮了一些字體,因此請記住在圖像文本中使用默認字體(Calibri),字體大小為“ 72”,因為有假設可以提取字母。
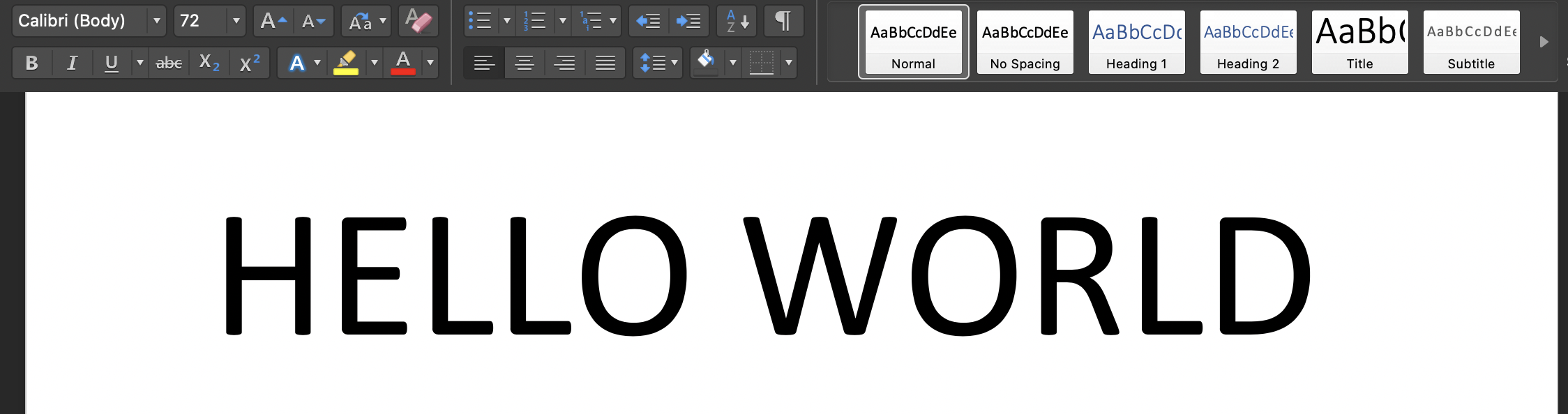
在您的終端上運行腳本:'Python3 tesseract.py':輸入圖像是: 
輸出為(預測的結果在底部): 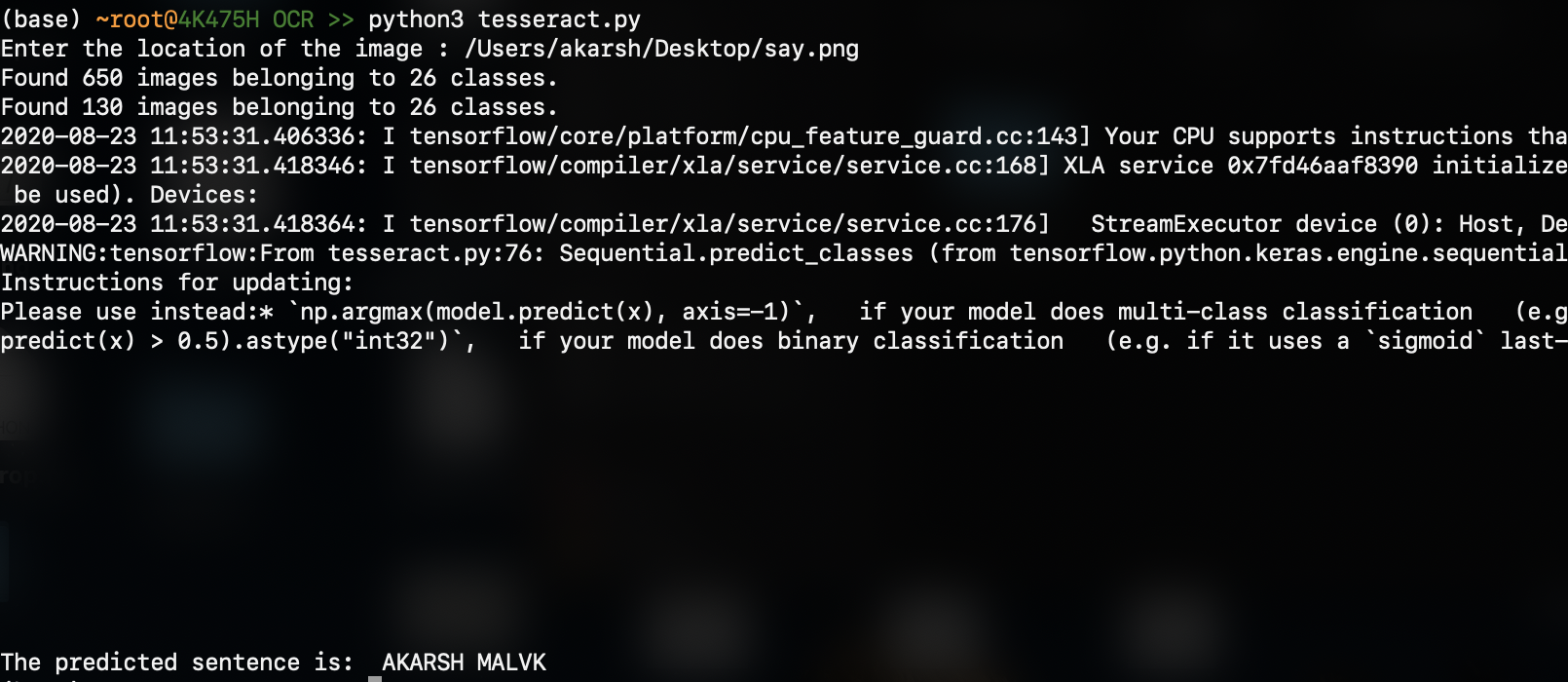
輸入圖像可以是許多單詞示例: 
輸出為:


