EXTRACT
1.0.0
Extract - это оптический механизм распознавания символов для различных операционных систем, который извлекает тексты из изображения и преобразует их в простой текст.
Эта модель является очень примитивной формой оригинальной Tesseract Google, которая извлекает тексты (только заглавные буквы) из изображения и преобразует их в простой текст.
Примечание1:- Обученная модель не предоставлена. Так что впервые запустите сценарий таким, как он есть. Как только модель обучена: прокомментируйте «train_model» в строке 65 ', а затем запустите скрипт для дальнейшего использования.
Примечание2:- Были приняты во внимание только некоторые шрифты, поэтому не забудьте использовать шрифт по умолчанию (калибри) в текстах изображений с размером шрифта «72», так как есть предположения для извлечения букв.
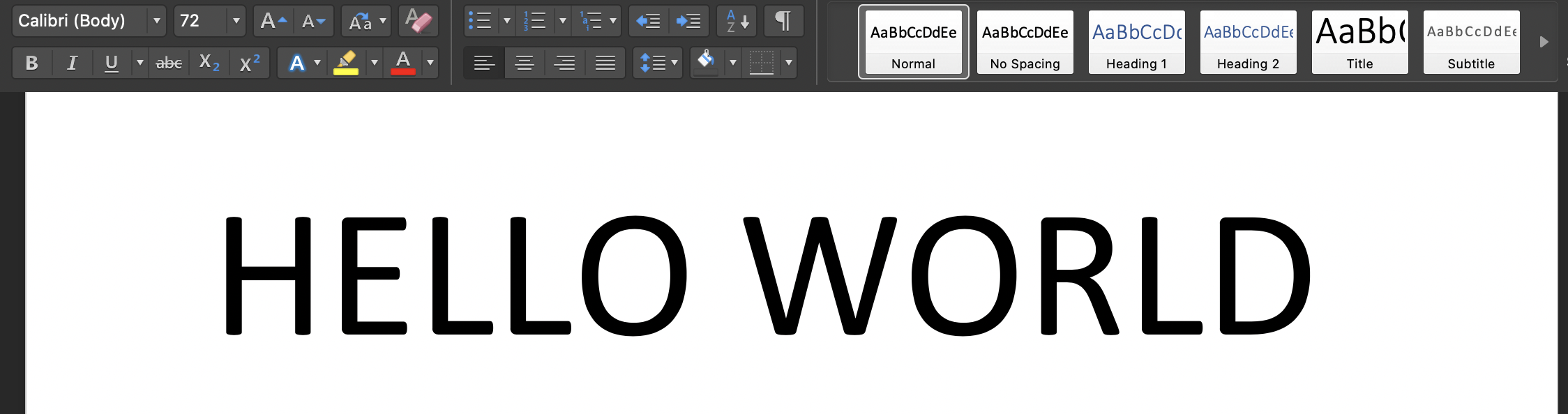
Запустите скрипт на вашем терминале: 'python3 tesseract.py': входное изображение - это: 
вывод (прогнозируемый результат внизу): 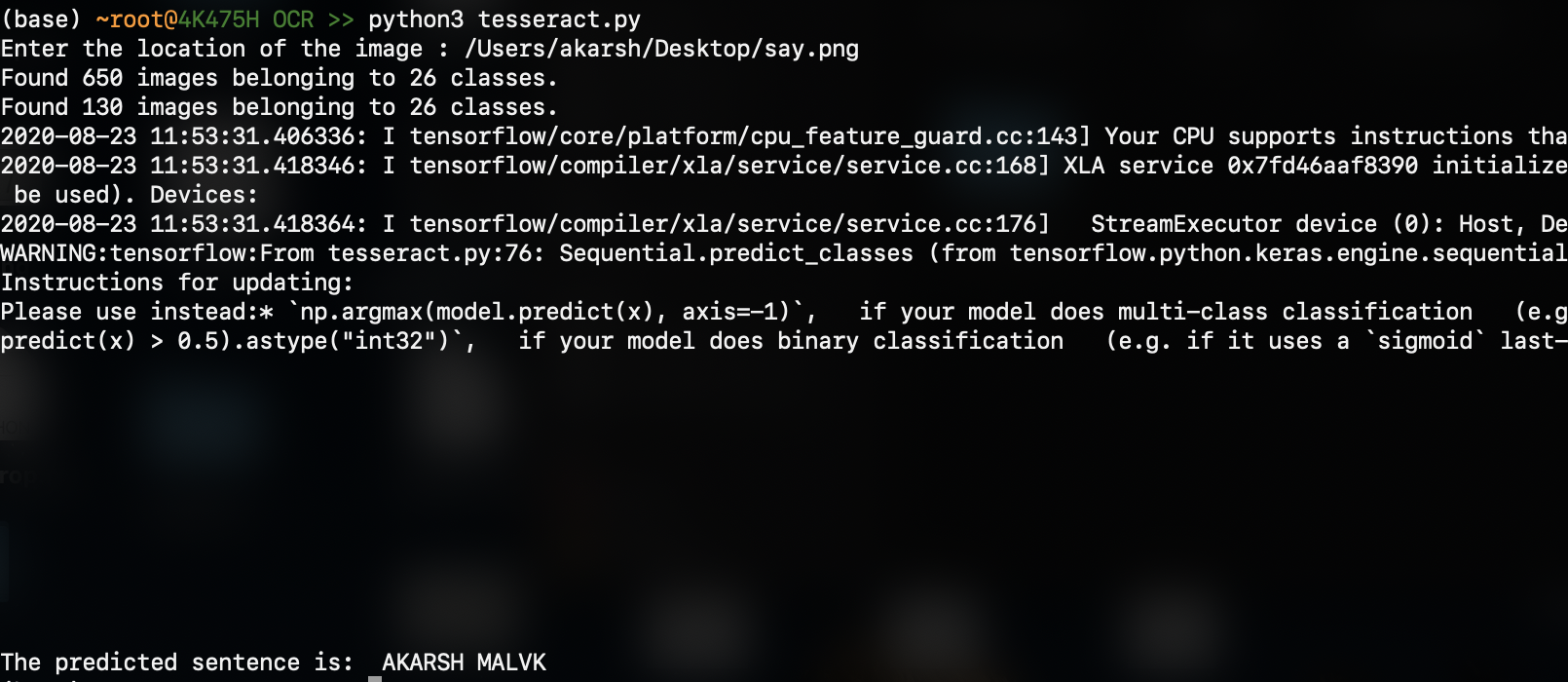
Входное изображение может быть примером любого количества слов: 
вывод:


