EXTRACT
1.0.0
El extracto es un motor de reconocimiento de caracteres ópticos para varios sistemas operativos que extrae textos de una imagen y los convierte en texto plano.
Este modelo es una forma muy primitiva de Google Tesseract original que extrae textos (solo letras mayúsculas) de una imagen y las convierte en texto plano.
Nota1:- No se proporciona el modelo capacitado. Entonces, por primera vez, ejecute el script tal como es. Una vez que el modelo está entrenado: comente 'Train_model' On Line '65' y luego ejecute el script para su uso adicional.
Nota 2:- Solo se tuvieron en cuenta algunas fuentes, así que recuerde usar la fuente predeterminada (Calibri) en textos de imagen con un tamaño de fuente de '72', ya que hay suposiciones para extraer letras.
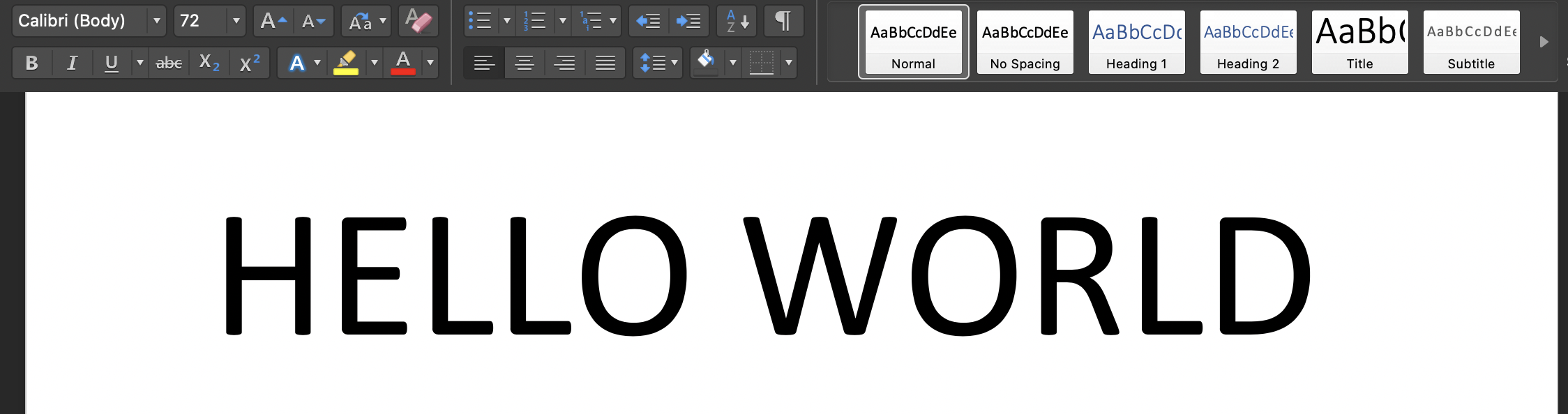
Ejecute el script en su terminal: 'python3 tesseract.py': la imagen de entrada es: 
La salida es (el resultado predicho está en la parte inferior): 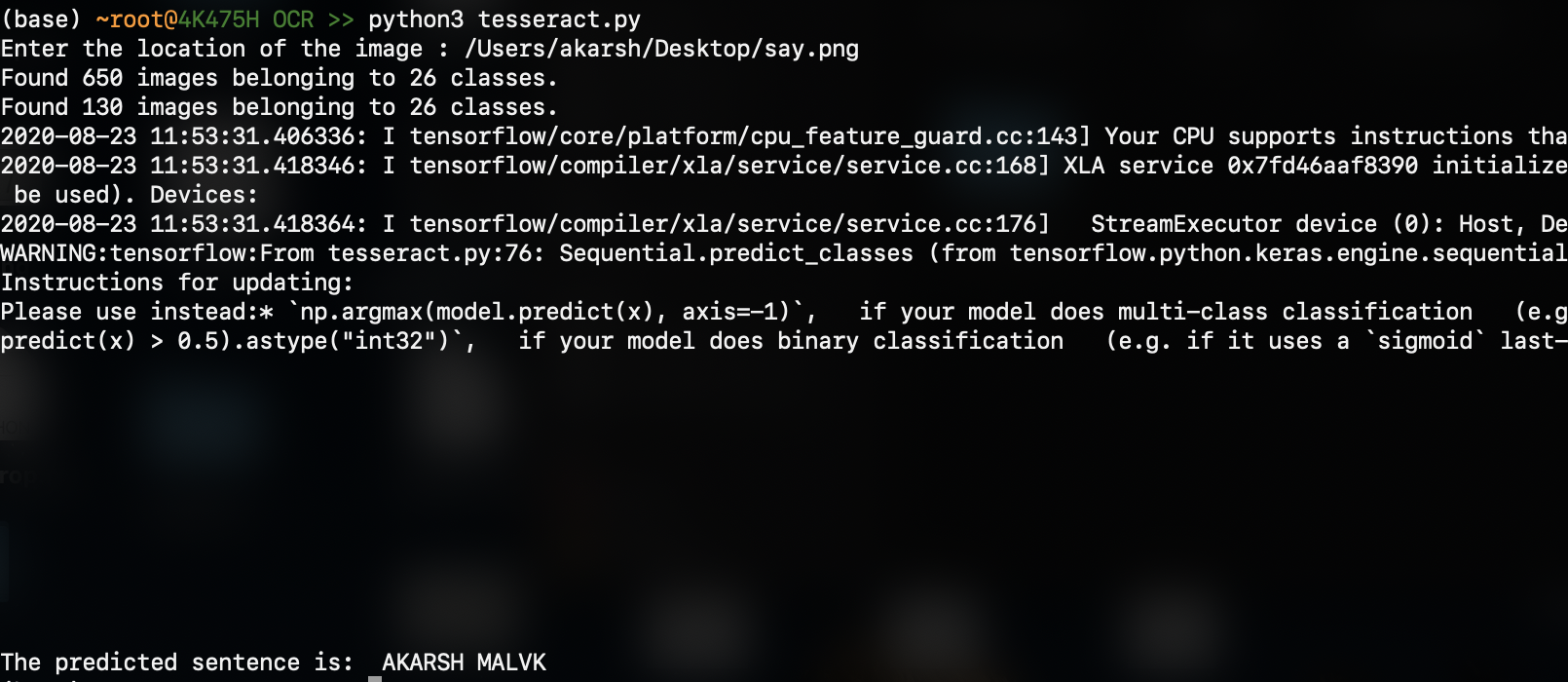
La imagen de entrada puede ser de cualquier número de palabras: 
La salida es:


