EXTRACT
1.0.0
L'extrait est un moteur de reconnaissance de caractères optiques pour divers systèmes d'exploitation qui extrait des textes d'une image et les convertit en texte brut.
Ce modèle est une forme très primitive du Google Tesseract d'origine qui extrait des textes (seulement des lettres majuscules) d'une image et les convertit en texte brut.
Remarque1: - Le modèle formé n'est pas fourni. Donc, pour la toute première fois, exécutez le script tel qu'il est. Une fois le modèle formé: commentez «Train_Model» en ligne «65», puis exécutez le script pour une utilisation ultérieure.
Remarque2: - Seules certaines polices ont été prises en compte, alors n'oubliez pas d'utiliser la police par défaut (calibri) dans des textes d'image avec une taille de police de «72» car il existe des hypothèses pour extraire des lettres.
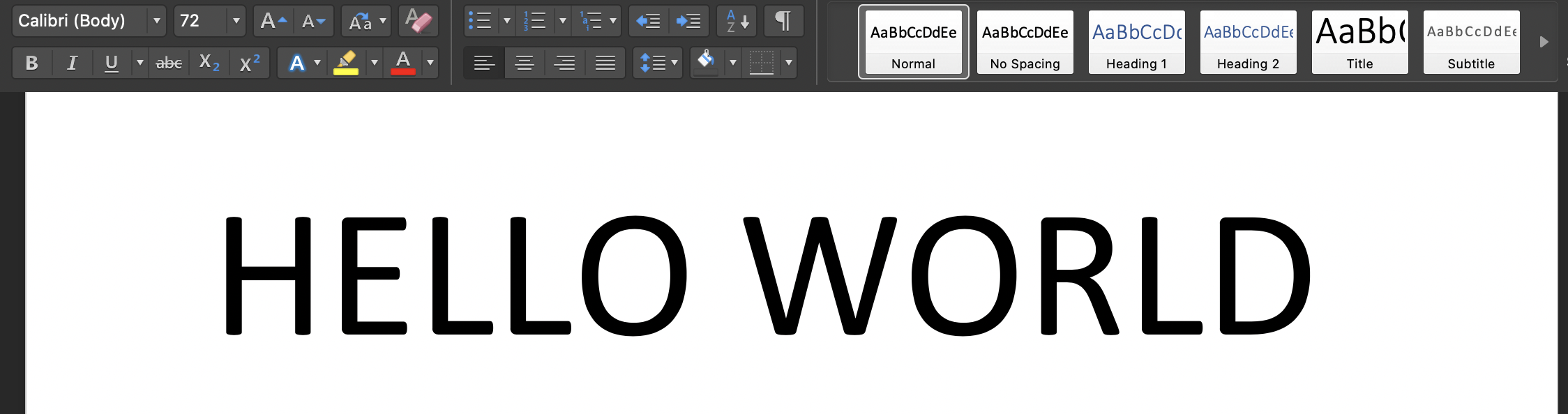
Exécutez le script sur votre terminal: 'Python3 Tesseract.py': l'image d'entrée est: 
La sortie est (le résultat prévu est en bas): 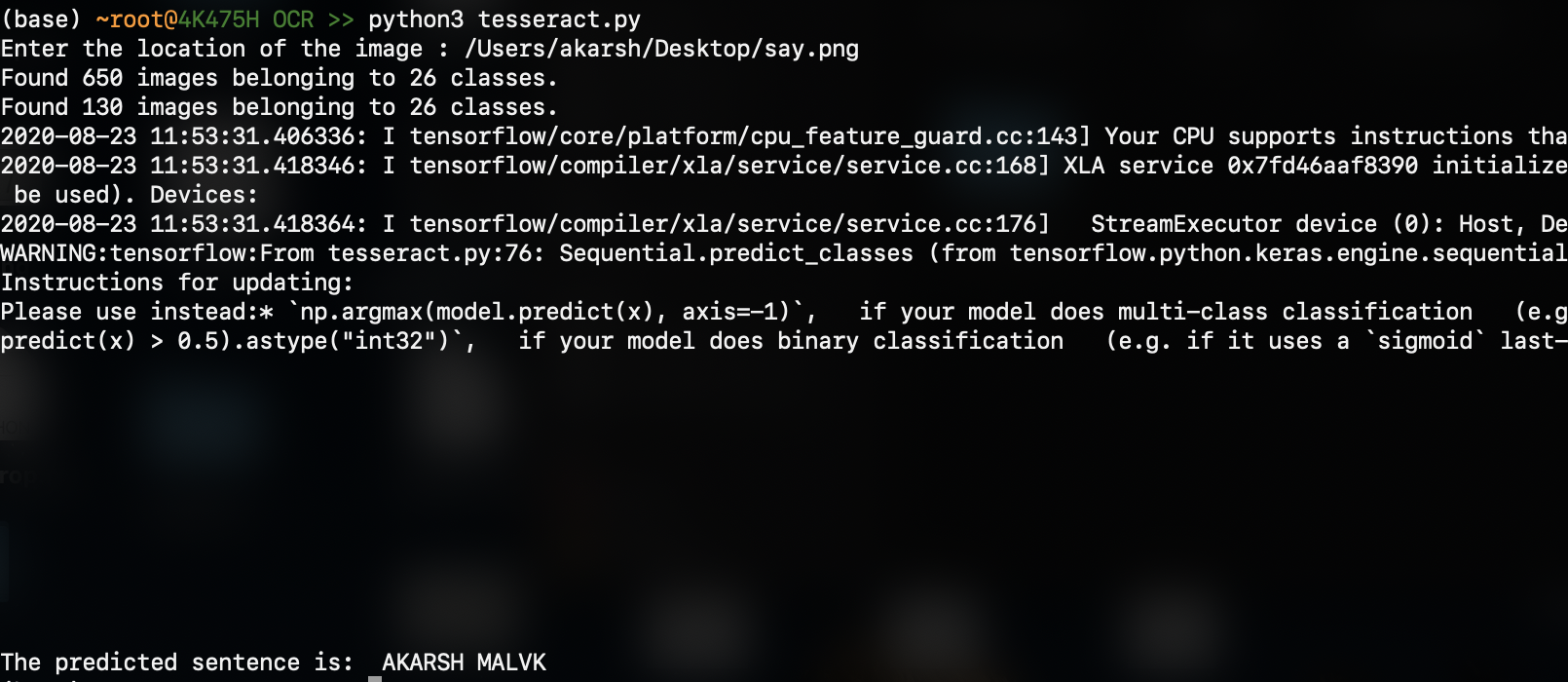
L'image d'entrée peut être de n'importe quel nombre de mots Exemple: 
La sortie est:


