EXTRACT
1.0.0
Extractは、画像からテキストを抽出し、それらをプレーンテキストに変換するさまざまなオペレーティングシステムの光学文字認識エンジンです。
このモデルは、画像からテキスト(大文字のみ)を抽出し、それらをプレーンテキストに変換するオリジナルのGoogle Tesseractの非常に原始的な形式です。
注1: - 訓練されたモデルは提供されていません。したがって、初めてスクリプトを実行します。モデルがトレーニングされたら:「Train_model」をライン「65」にコメントし、さらに使用するためにスクリプトを実行します。
注2: - いくつかのフォントのみが考慮されたので、文字を抽出する仮定があるため、「72」のフォントサイズの画像テキストでデフォルトフォント(Calibri)を使用することを忘れないでください。
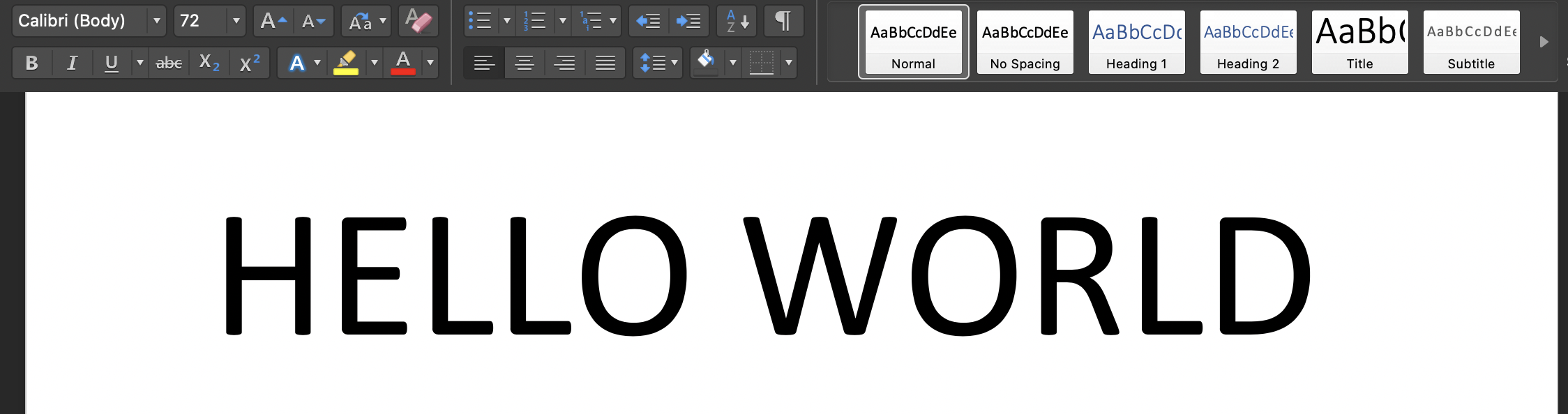
ターミナルでスクリプトを実行します: 'python3 tesseract.py':入力画像は次のとおりです。 
出力は(予測される結果は下部にあります): 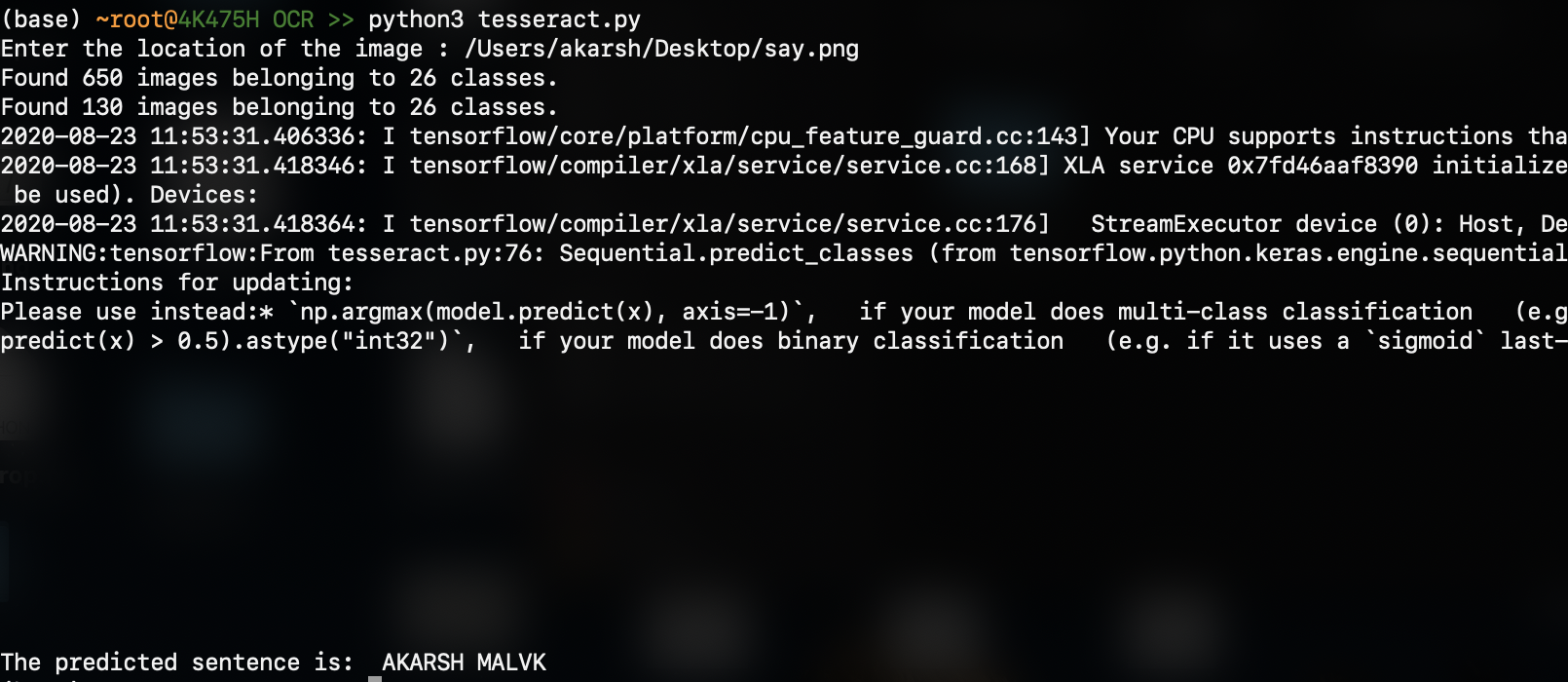
入力画像は、任意の数の単語の例を使用できます。 
出力は次のとおりです。


