EXTRACT
1.0.0
Extract는 이미지에서 텍스트를 추출하여 일반 텍스트로 변환하는 다양한 운영 체제를위한 광학 문자 인식 엔진입니다.
이 모델은 이미지에서 텍스트 (대문자 만)를 추출하여 일반 텍스트로 변환하는 원래 Google Tesseract의 매우 원시적 인 형태입니다.
주 1 :- 훈련 된 모델은 제공되지 않습니다. 그래서 처음으로 스크립트를 그대로 실행하십시오. 모델이 훈련되면 : '65'라인에서 'Train_Model'을 주석으로 한 다음 스크립트를 실행하여 추가 사용을 실행하십시오.
참고 2 :- 글자를 추출 할 가정이 있기 때문에 일부 글꼴 만 고려되었으므로 글꼴 크기가 '72'인 이미지 텍스트에서 기본 글꼴 (Calibri)을 사용해야합니다.
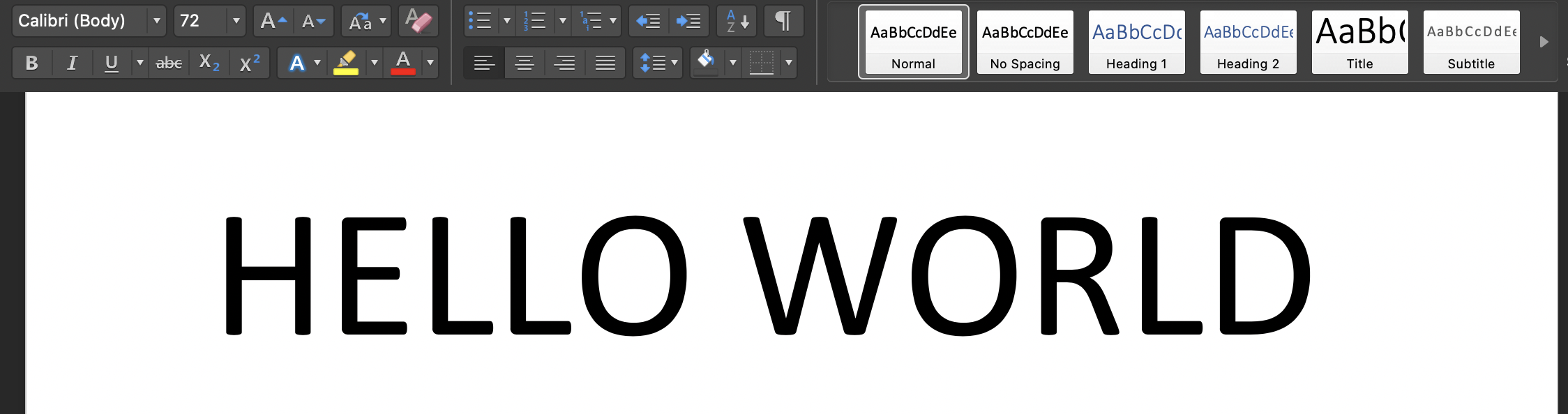
터미널에서 스크립트를 실행하십시오 : 'Python3 Tesseract.py': 입력 이미지는 다음과 같습니다. 
출력은 (예측 된 결과는 맨 아래에 있습니다) : 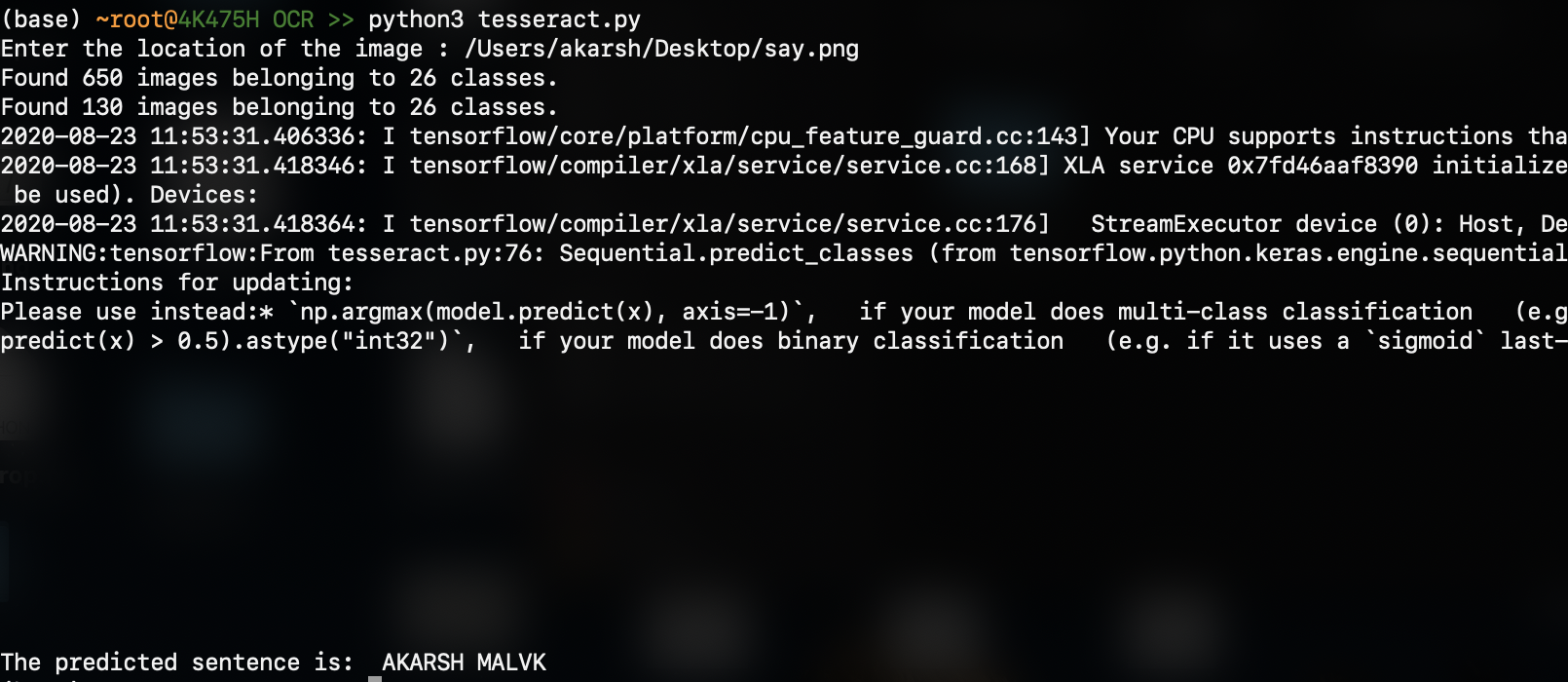
입력 이미지는 여러 단어의 예제 일 수 있습니다. 
출력은 다음과 같습니다.


