EXTRACT
1.0.0
Extract هو محرك التعرف على الأحرف البصرية لمختلف أنظمة التشغيل التي تستخرج النصوص من صورة وتحولها إلى نص عادي.
هذا النموذج هو شكل بدائي للغاية من Google Tesseract الأصلي الذي يستخرج النصوص (الأحرف الرأسمالية فقط) من صورة وتحولها إلى نص عادي.
ملاحظة 1:- لا يتم توفير النموذج المدرب. لذلك لأول مرة قم بتشغيل البرنامج النصي كما هو. بمجرد أن يتم تدريب النموذج: التعليق على "Train_Model" على السطر "65" ثم قم بتشغيل البرنامج النصي لمزيد من الاستخدام.
ملاحظة 2:- تم أخذ بعض الخطوط فقط في الاعتبار ، لذا تذكر استخدام الخط الافتراضي (CALIBRI) في نصوص الصور بحجم خط "72" حيث توجد افتراضات لاستخراج الحروف.
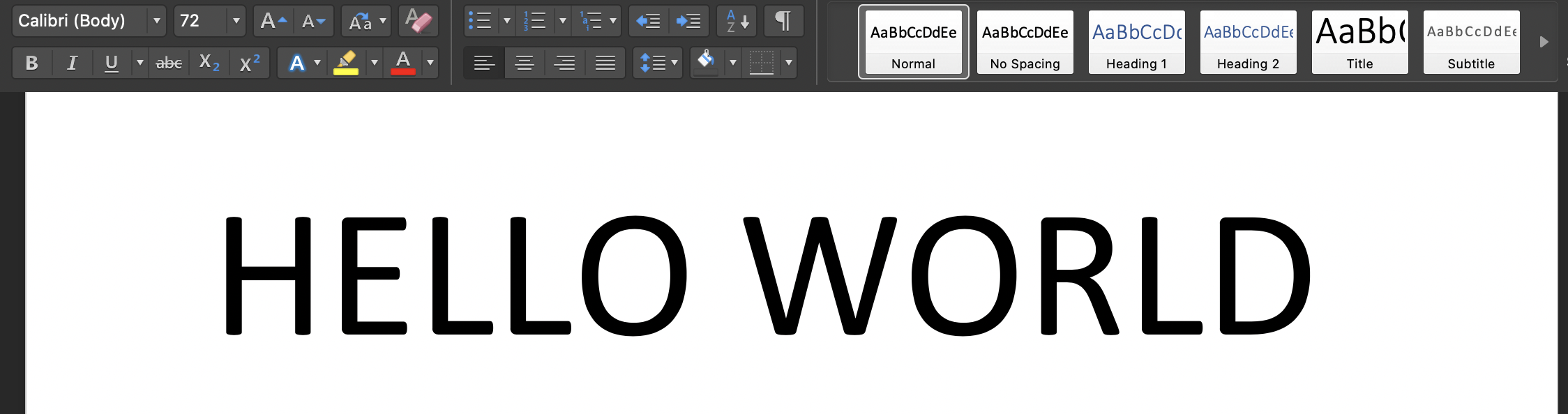
قم بتشغيل البرنامج النصي على المحطة الخاصة بك: "Python3 tesseract.py": صورة الإدخال هي: 
الإخراج هو (النتيجة المتوقعة في الأسفل): 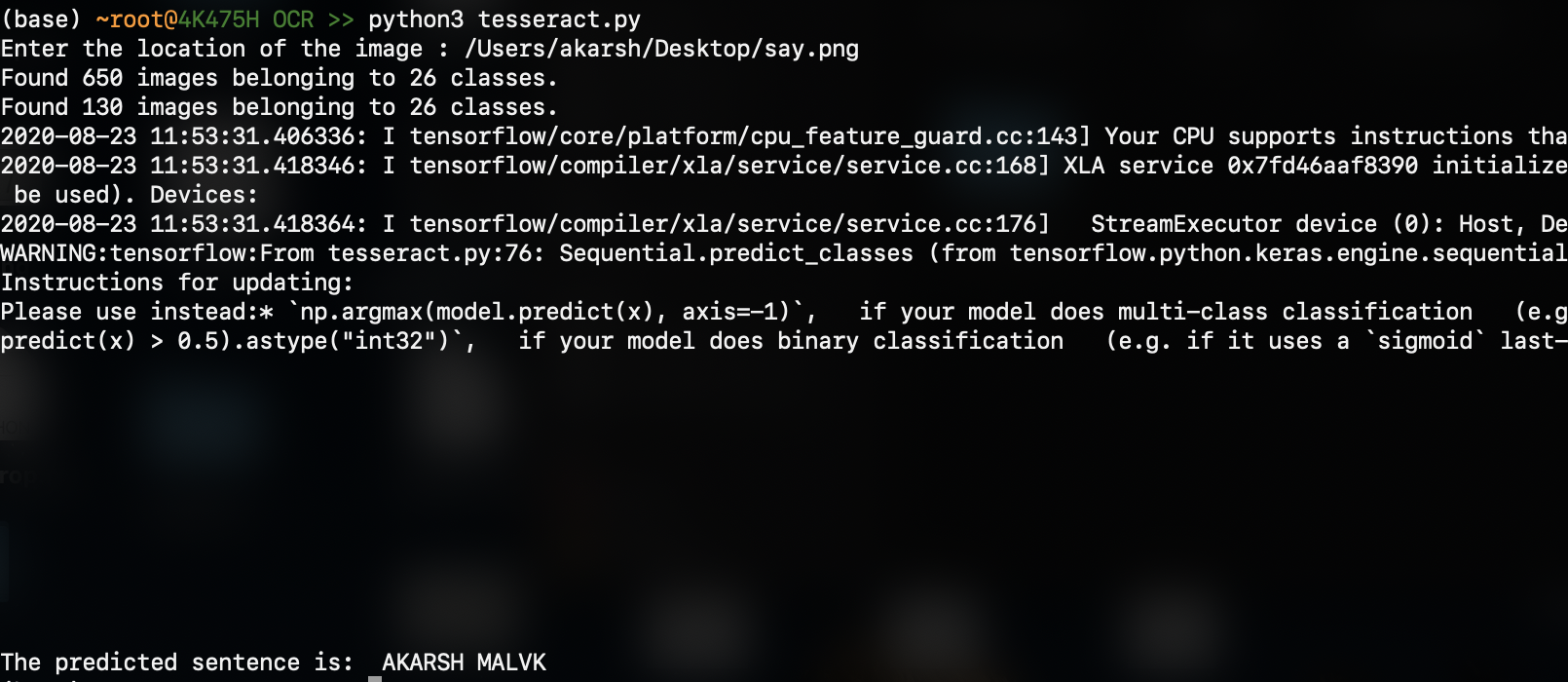
يمكن أن تكون صورة الإدخال من أي عدد من الكلمات مثال: 
الإخراج هو:


