EXTRACT
1.0.0
Extract เป็นเอ็นจิ้นการจดจำอักขระแบบออพติคอลสำหรับระบบปฏิบัติการต่างๆซึ่งแยกข้อความจากภาพและแปลงเป็นข้อความธรรมดา
โมเดลนี้เป็นรูปแบบดั้งเดิมของ Google Tesseract ดั้งเดิมซึ่งแยกข้อความ (เฉพาะตัวพิมพ์ใหญ่) จากภาพและแปลงเป็นข้อความธรรมดา
หมายเหตุ 1:- ไม่มีการให้แบบจำลองที่ผ่านการฝึกอบรม ดังนั้นเป็นครั้งแรกที่เรียกใช้สคริปต์ตามที่เป็นอยู่ เมื่อโมเดลได้รับการฝึกฝน: แสดงความคิดเห็น 'train_model' ในบรรทัด '65' แล้วเรียกใช้สคริปต์เพื่อใช้เพิ่มเติม
หมายเหตุ 2:- มีเพียงฟอนต์บางตัวเท่านั้นที่ถูกนำมาพิจารณาดังนั้นอย่าลืมใช้แบบอักษรเริ่มต้น (calibri) ในข้อความภาพที่มีขนาดตัวอักษร '72' เนื่องจากมีสมมติฐานที่จะแยกตัวอักษร
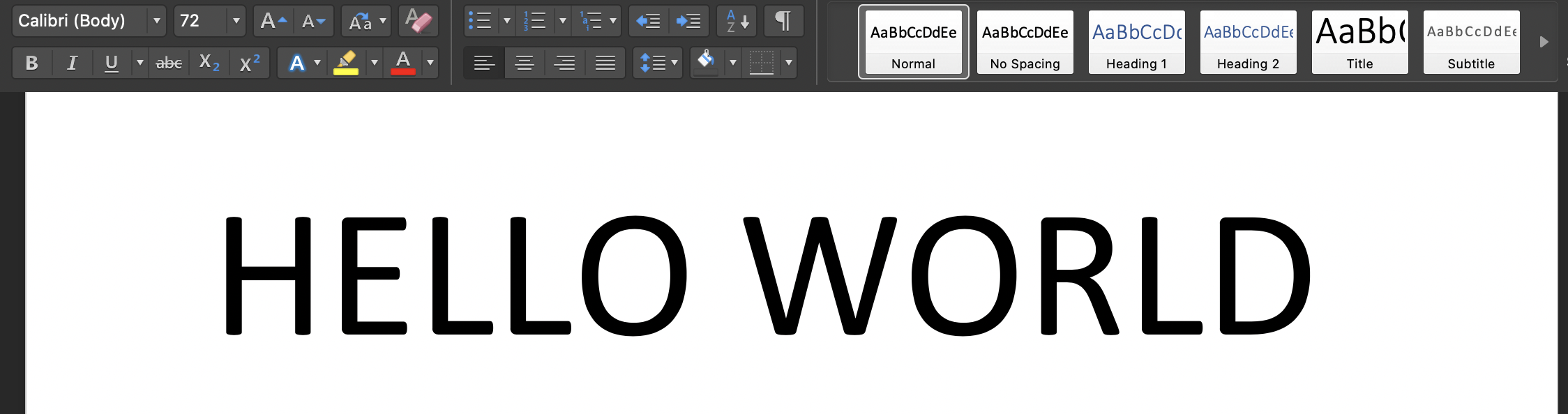
เรียกใช้สคริปต์บนเทอร์มินัลของคุณ: 'Python3 tesseract.py': ภาพอินพุตคือ: 
เอาต์พุตคือ (ผลลัพธ์ที่คาดการณ์อยู่ที่ด้านล่าง): 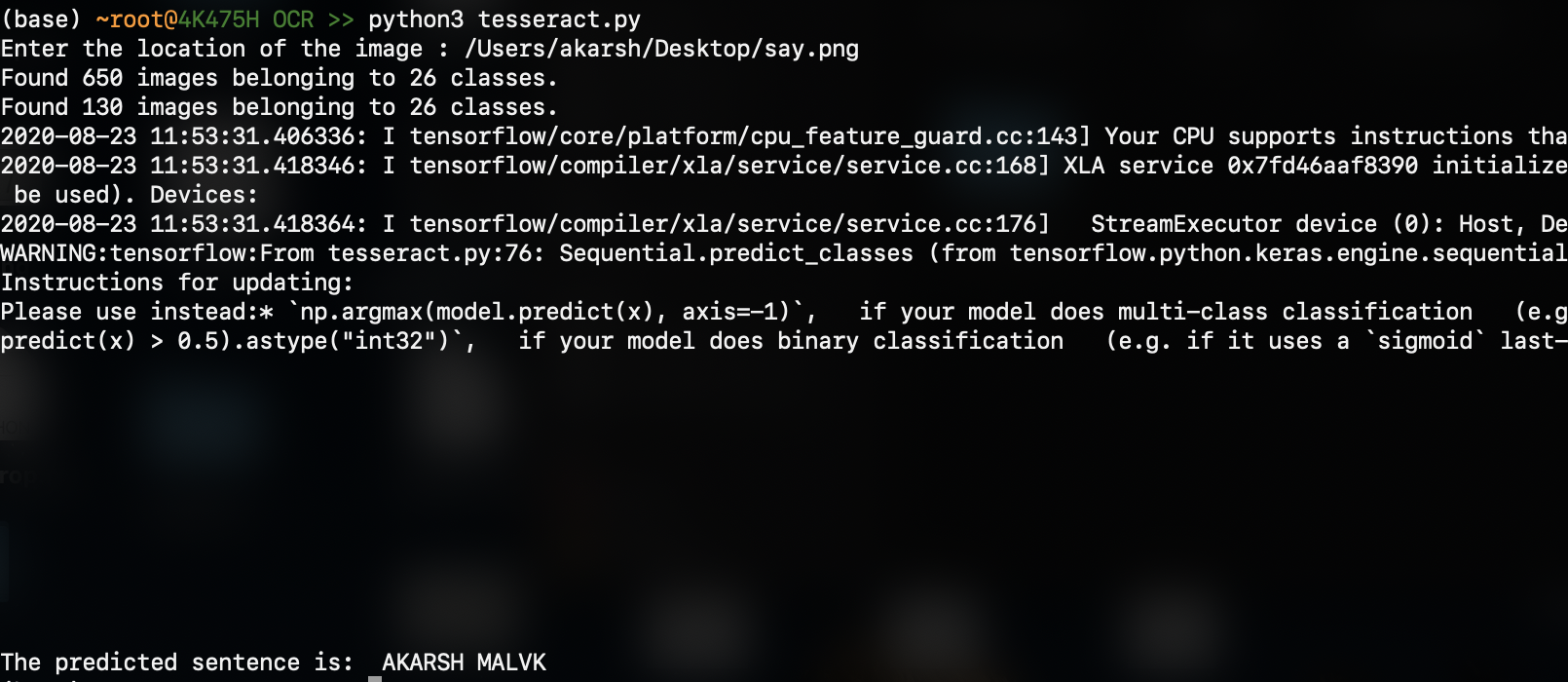
ภาพอินพุตสามารถเป็นจำนวนคำใดก็ได้: 
เอาต์พุตคือ:


