EXTRACT
1.0.0
提取物是各种操作系统的光学角色识别引擎,可从图像中提取文本并将其转换为纯文本。
该模型是原始的Google Tesseract的一种非常原始的形式,它从图像中提取文本(仅大写字母)并将其转换为纯文本。
Note1: - 未提供训练的模型。因此,这是第一次运行脚本。训练模型后:注释“ Train_model”在“ 65”上,然后运行脚本以进行进一步使用。
Note2: - 仅考虑了一些字体,因此请记住在图像文本中使用默认字体(Calibri),字体大小为“ 72”,因为有假设可以提取字母。
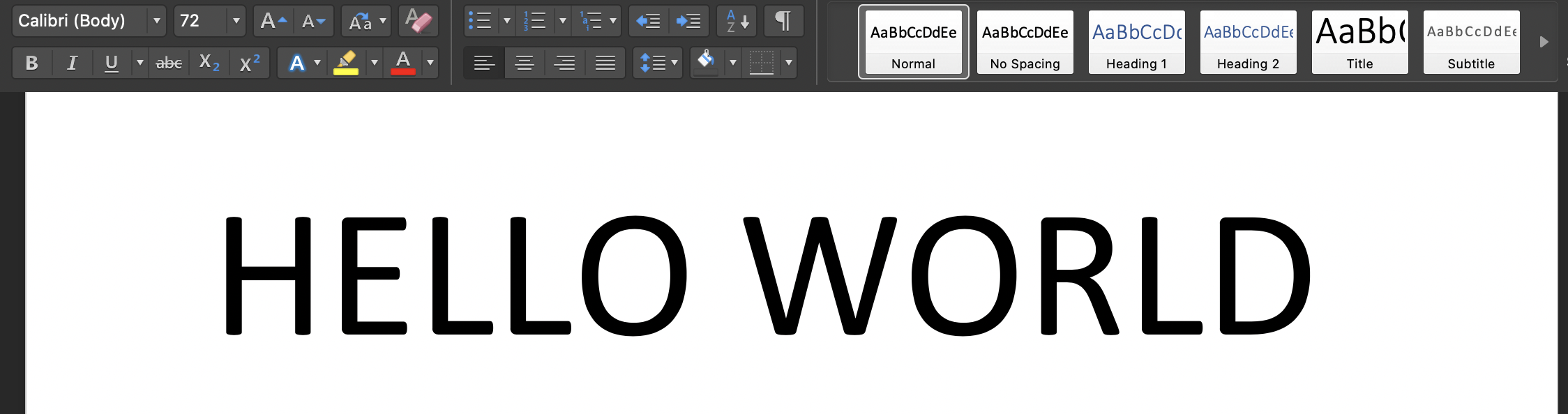
在您的终端上运行脚本:'Python3 tesseract.py':输入图像是: 
输出为(预测的结果在底部): 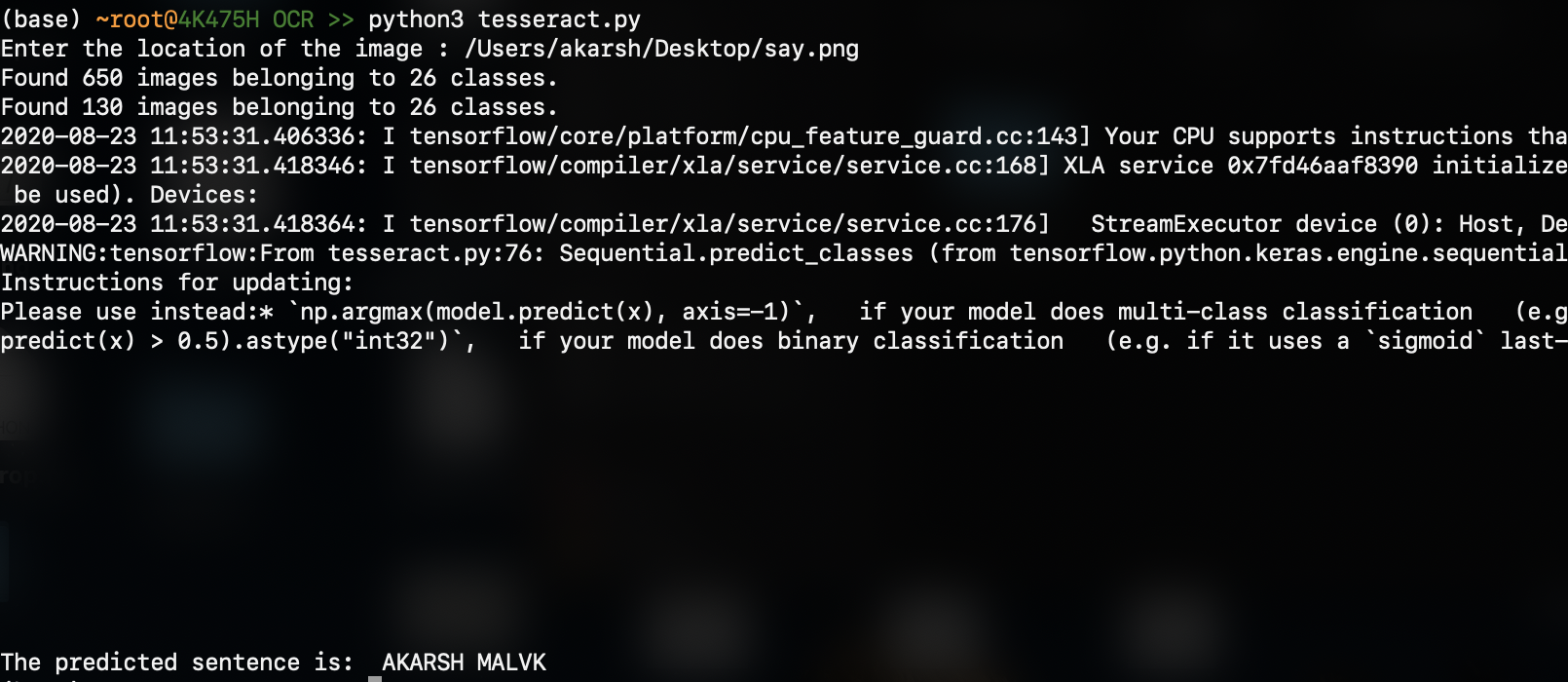
输入图像可以是许多单词示例: 
输出为:


