EXTRACT
1.0.0
O Extract é um mecanismo de reconhecimento óptico de caracteres para vários sistemas operacionais que extrai textos de uma imagem e os converte em texto sem formatação.
Este modelo é uma forma muito primitiva do Google Tesseract original que extrai textos (apenas letras maiúsculas) de uma imagem e as converte em texto simples.
Nota 1:- O modelo treinado não é fornecido. Então, pela primeira vez, execute o script como ele é. Depois que o modelo for treinado: comente 'Train_model' on -line '65' e depois execute o script para uso posterior.
Nota2:- Apenas algumas fontes foram levadas em consideração, lembre-se de usar a fonte padrão (calibri) nos textos da imagem com um tamanho de fonte de '72', pois existem suposições para extrair letras.
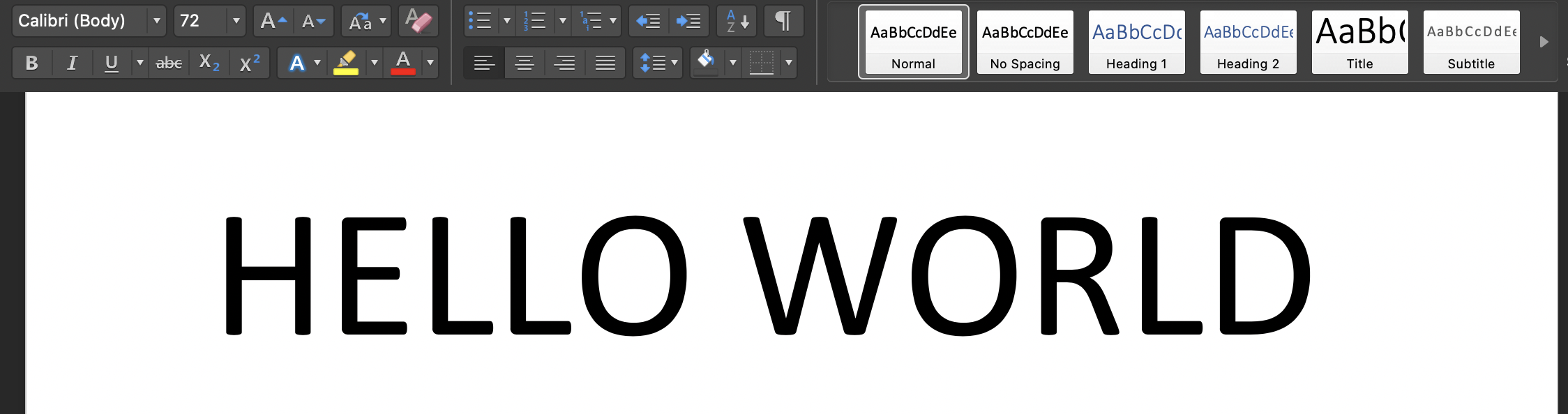
Execute o script no seu terminal: 'python3 tesseract.py': a imagem de entrada é: 
A saída é (o resultado previsto está na parte inferior): 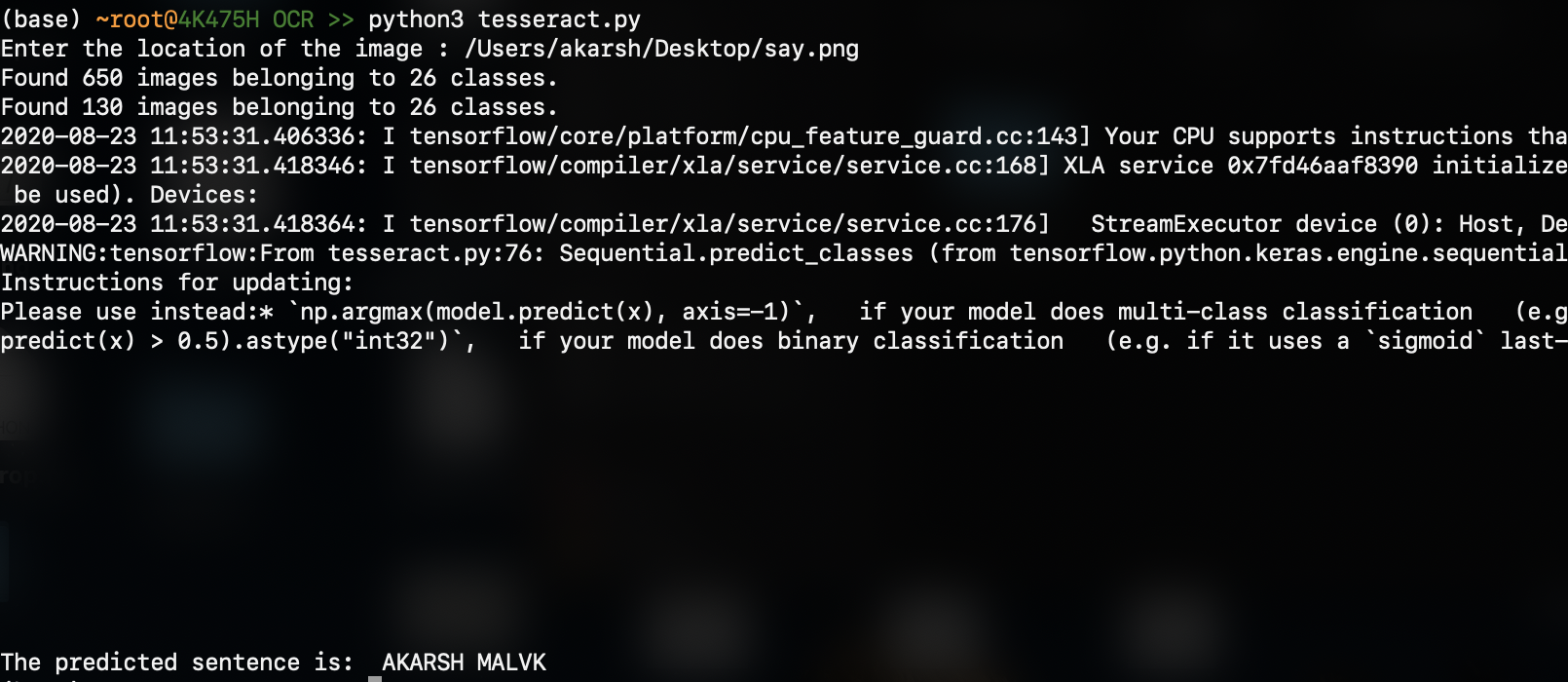
A imagem de entrada pode ser de qualquer número de palavras exemplo: 
A saída é:


