esdi
v1.0.1
使用給定輸入值的模擬,此閃亮的R應用顯示了與標準化平均差異( SMD )效應效果尺寸差異之間的診斷效率(通過正確檢測率或曲線下的區域衡量)如何在單條件案例之間(對於缺乏對照組進行直接比較)。
該應用程序可在線提供(僅在任何網絡瀏覽器中打開):https://gasparl.shinyapps.io/esdi/
但是,從PC運行它也很容易。您只需要在r中運行以下命令:
shiny :: runGitHub( " esdi " , " gasparl " )`對於後一種替代方案,如果您還沒有它們,則需要安裝R ,然後通過輸入install.packages("shiny")進入控制台,然後在R中安裝shiny軟件包。然後復制shiny::runGitHub("esdi", "gasparl")例如在控制台中,然後按Enter。必要的組件將自動下載,並且應用程序將在新窗口中打開。
最後,要隨時使用該應用程序,無需訪問Internet即可,您可以下載整個存儲庫(或僅app.r )並在app.r文件中運行代碼。為此,您需要安裝代碼中使用的所有R軟件包(在第一行列出)。
要快速掌握應用程序的本質,請參見下面的示例部分,或者請參見一般動機的背景。下面是詳細的技術解釋。
影響關鍵SMD診斷關係的唯一設置是案例和對照的預測指標值的標準偏差(SD)(SD)的(比率),這些差異代表了來自正案例和對照組的數據的普遍假定的SD(再次,有關對照組的數據)(再次,有關更多解釋,請參見下面的背景和示例部分)。應根據給定研究領域的病例和對照的典型SD估算SDS。但是,SD差異對結果的影響相對較小,並且在大多數情況下(如果SD尚不清楚或無法輕易估算),可以假設離開默認設置(兩個1 )仍然會給出近似正確的結果(除非Case SD / Control SD可能非常大或很小)。換句話說,該軟件的默認設置可能適用於大多數情況。
基於給定的SDS,針對其他設置下指定的每個SMD都會自動計算樣品的均值。注意:要簡要介紹,但要避免縮寫,SMD(標準化的平均差異)表示為選項的“效果大小”和界面上的繪圖標籤。為所有不同方式(使用兩個常規SDS)生成數據集,並具有接近完美的正態分佈。 SMD的規範相當簡單:必須給出一個起始值,最終值和步驟。 0.6 ,開始0.2 , 0.4為0.6和0.1 0.3步驟將0.5以下SMD: 0.2 。較小的步驟(或更遙遠的啟動和結束)意味著更多的數據點要計算,因此這些設置可以大大增加計算時間。
重要的是要牢記(a)單條件之間的SMD之間的差異(“案例1”與“案例2”)和(b)案例和單個條件控制之間的SMD(“ case”與“控制”)之間的差異。第一個(a)指示兩種診斷方法之間的診斷效率差異(例如一種舊方法和新的改進方法),而第二個方法(b)僅是在給定方法內的診斷效率的替代測量,例如,在舊方法的診斷效率上始終具有更大的診斷效率(始終是較大的診斷效率(始終),因此始終是較大的診斷效率(因此'正確檢測速率和曲線下的較大面積)。
初始“情況1”與“控制” SMD表示要改進的方法的診斷效率(方法1)。 (注意:實際上是可能的,但實際上毫無意義地包括零以進行起始價值,除非出於演示目的,因為這意味著該方法1在機會級別上執行,因此首先是無用的。)該地塊描繪了改進的方法(方法2的診斷效率(準確性)(準確性:“ case 2“ vs.“ vs.“ vs.“ vs.“ vs.“ vs.“ vs.“ vs.“ vs.“ vs.”),” (請注意,為了清楚起見,保持“情況1”與“案例2” SMD的起始價值總是很好,然後說明了兩種方法之間根本沒有差異的起點。
值以兩種不同的方式描述:作為總準確性,並獲得準確性。獲得的準確性簡單地計算為總準確性減去初始(方法1)精度。組合圖包含兩種類型,而子圖分別描繪了這些類型,並且可以通過與光標懸停在線路上以讀取繪圖上給定點的SMD和準確性的精確值來進行交互性探索(請參見下面的示例部分)。
由於樣本量不是無限的,因此與給定的SMD設置相比,計算出的SMD結果中的正態分佈永遠不會真正完美,因此,在設置中可以給出一個初始SMD為0.5 ,但是實際結果可能是0.51 。樣本量(生成數據點的數量)可以在標籤Sample size下設置:較大的數量導致計算時間有所增加,但更精確的結果。大約4000的樣本量通常會提供多達兩個分數的精度,而大約則具有精度。 15000可能是最多三個分數。重要的是,無論樣本量如何(以及設置和結果的對應關係),SMD和診斷與給定結果的關係始終是精確而正確的。
繪圖設置與數據的描述有關,應該是自稱的。該圖的計算的所有值均在交互式數據表中的“表”選項卡下可用。
確定所需樣本量的前瞻性(先驗)功率分析對於行為實驗至關重要(例如,Perugini,2018年)。為了確定功率分析所需的最小興趣效果,理想的方法是依靠客觀的理由(Lakens,2013; Lakens等,2018)。例如,要比較兩種不同的診斷方法,一個人可能會考慮對疾病正確檢測率提高的現實生活含義,這些疾病的率與顯示給定增加的統計證據所需的樣本量成本有關。研究人員可能會做出明智而謹慎的決定,例如,有120名參與者的檢測到至少8%的檢測準確性是值得的:增長2%甚至0.1%也可能具有重要的現實生活利益,但由於資源有限,因此不值得收集更大的樣本數量來檢測如此較小的更改所需的樣本量。
但是,實際含義並不總是那麼簡單地評估。在實驗設計的一種特定情況下,可以使用單條件案例進行有效比較兩種診斷方法,從而省略控件(又稱“基線”或“負條件”)以備用資源。這種情況可以發生在應用二元分類的許多領域中的任何一個,也許是醫學中最特徵的。假設疾病可能被診斷出具有連續測量X ,對於給定疾病的患者(例如對皮膚刺測的反應時,小凸起或發紅;陽性病例)通常較高,而健康的人通常是相同的(例如,對皮膚刺測試或對皮膚刺測的反應或少數反應;陰性病例;陰性病例)。因此,可以以一定的精度檢測到陽性案例 - 但不是完美的,因為某些測量值在某種程度上是錯誤的,並且對於陽性病例也錯誤的值也很低。如果某人提出了對度量X中更高值的程序進行改進,則可以直接將兩種方法在陽性案例上進行比較:由於措施在負面病例(健康人員)中始終是恆定的(低)(健康的人),因此較高的陽性病例值也意味著該過程也將具有更好的診斷效率。
這裡的問題在於,潛在功率計算的效果大小在兩個積極條件之間,這對診斷的實際後果沒有直接影響。目前的軟件通過為僅積極條件之間的給定效應大小提供診斷效率值(正確的檢測率和曲線下的區域)來提供幫助。
該軟件實際上是受隱藏信息測試(CIT)研究的啟發的:CIT可以揭示一個人認識到相關的探測項目(例如最近犯罪中使用的特定謀殺武器),以及其他無關的項目(例如其他可行的武器),例如,基於不同的探測器,與無關項目相比,對探測的響應較慢。由於無辜者不認為探針是相關的,因此他們的響應平均不會在探測器和無關的項目之間差異。因此,基於較大的探針 - 微級別( PI )差異,有罪的人可以與無辜者區分開。至關重要的是,由於無辜者的PI始終約為零,因此許多研究僅使用有罪的組比較了不同版本的CIT版本,並且了解到較大的PI組意味著給定版本的含義意味著使用該版本也可以更好地使用該版本(即更加有罪的人可以與無知的人脫穎而出)。但是,兩個有罪群體(或相關SMD)之間算術平均值的差異實際上並沒有任何明智的實際含義,因此不能用於對樣本量的有根據的決定。實際上,在最近的薈萃分析(Lukács&Specker,2020)中收集的24項研究中,有13項使用了單條件比較,沒有人報告樣本量的先前功率計算,即使效應量的解釋也基於Cohen的著名著名,但在內部任意基準中,但沒有直接的實用含義,沒有直接的實踐含義(Cohen,1988年; Lakens Al; Lakens Al,2018)。
現在,這項薈萃分析還報告了病例(有罪組)和對照組(無辜組), 33.6和23.5的平均SD(基於12個實驗),因此可以在ESDI應用中用作病例SD和控制SD的輸入值。但是,使用兩個SD的默認值1實際上都會給出非常相似的結果:通常,知道和給出精確的SD估計值並不重要(除非情況SD / Control SD比率可能非常大或很小)。
為案例SD和控制SD提供33.6和23.5 ,樣本量為4000 ,並且將所有其他設置保持不變,主要組合圖將看起來像這樣:
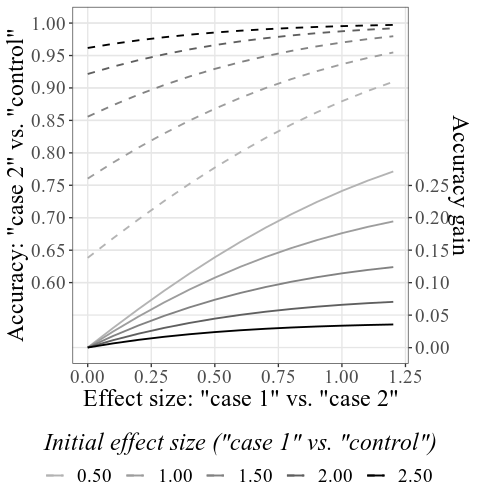
請注意,如上所述如何使用上面的部分中所述 - 基於給定的初始SMD(請參閱底部標籤;在繪圖設置下,可以更改此標籤以顯示精度而不是SMD)計算初始精度。由於模擬過程,所得的SMD可能與設置中給出的SMD略有不同(同樣,請參見如何使用技術細節)。
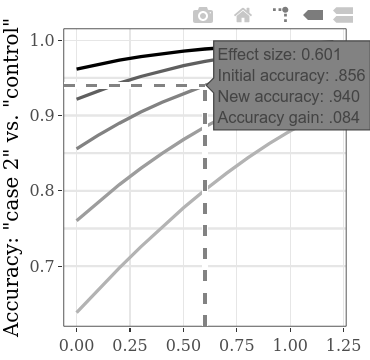
可以在相互作用的子圖上分別探索條件間(有罪1與有罪2)SMD的提高(有罪1與有罪2)的增加(有罪1與有罪2)的功能。例如,如下所示,懸停在線上,似乎表明,如果我們在兩個有罪組的結果之間發現效果大小(SMD)為0.601,則給定最初的準確性為.856(正確檢測到的人的命中率,有罪和無辜的人),準確度的準確性將增加0.084(從而提高了0.084的精度)。如果我們假設這種類型的CIT的初始準確性(即使用具有較低診斷效率的方法的精度)確實通常在.856左右,則可以在此行上使用SMD值進行冪計算。例如,對於SMD 0.6,對於0.9的功率,每組所需的樣本量為60(對於alpha = .05的未配對t檢驗)。因此,要從統計上檢測到至少0.084的檢測準確性的增加,在兩個有罪條件下總共需要收集120人。
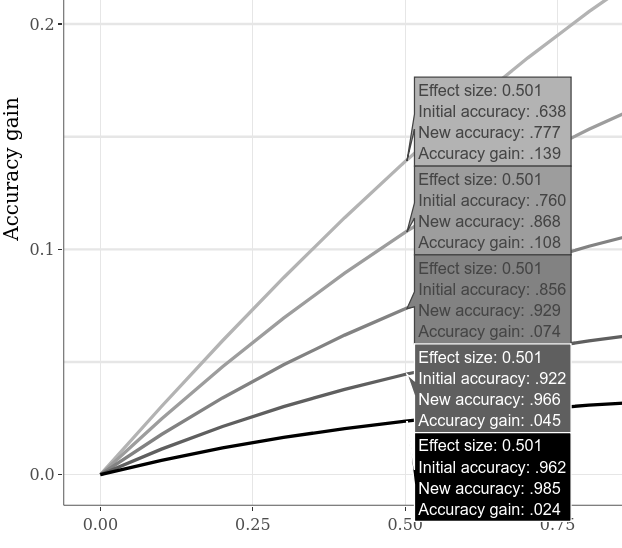
可以通過例如切換到“大型交互式子圖”選項卡,單擊較低圖上的“懸停數據”選項,然後沿圖水平移動光標。下面的示例顯示了“案例1”與“案例2” SMD為0.5時的各種準確性。由於在上一個示例圖上已經很明顯,因此較低的初始精度始終允許更大的準確性增益。
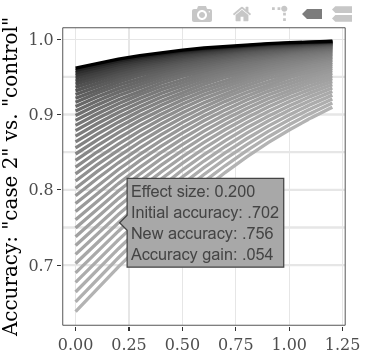
為了同時探索更多的初始啟動值,可以降低“情況1”與“控制” SMD的步驟設置,從而導致圖上有更多的線(並有所增加計算時間)。 (“情況1”與“情況2” SMD的步驟類似地導致更多的水平數據點。)
默認情況下,顯示正確檢測的簡單速率(所有正確分類的受試者的數量除以所有受試者的數量)以“準確性”測量,因為這可能是診斷效率的最直接指標。它可以更改為左圖中“繪圖”選項卡下曲線下方的區域。在同一選項卡下,也可以自定義繪圖標籤。
可以使用shinytest軟件包來驗證該軟件的基本功能以運行自動測試套裝(例如,在做出貢獻後)。只需運行shinytest::recordTest("/path/to/directory/") - 其中"/path/to/directory/"應該用應用程序目錄的路徑替換,例如"C:/apps/esdi/" 。
如果您有任何疑問或找到任何問題(錯誤,所需功能),請寫電子郵件或打開新問題。
Cohen,J。 (1988)。行為科學的統計能力分析(第二版)。新澤西州希爾斯代爾:埃爾鮑姆。
Lakens,D。 (2013)。計算和報告效果大小以促進累積科學:t檢驗和方差分析的實用底漆。心理學領域,4。 https://doi.org/10.3389/fpsyg.2013.00863
Lakens,D.,Scheel,AM和Isager,PM(2018)。心理學研究的等效測試:教程。心理科學方法和實踐的進步,1(2),259–269。 https://doi.org/10.1177/2515245918770963
Perugini,M.,Gallucci,M。和Costantini,G。 (2018)。用於簡單實驗設計的功率分析的實用入門。國際社會心理學評論,31(1),20。 https://doi.org/10.5334/irsp.181
將此軟件引用為:
Lukács,G。 ,&Specker,E。 (2020)。分散事項:隱藏信息測試研究中的診斷和控制數據計算機模擬。 PLOS ONE,15 (10),E0240259。 https://doi.org/10.1371/journal.pone.0240259


