esdi
v1.0.1
Используя моделирование для заданных входных значений, это блестящее применение R показывает, как диагностическая эффективность (как измеряется по скоростям правильного обнаружения или областей в соответствии с кривыми) изменяется в отношении стандартизированных средних различий ( SMD ) различий в величине между случаями отдельных кондиционеров (когда они напрямую сравниваются с отсутствием контролей).
Приложение доступно в Интернете (чтобы быть просто открытым в любом веб -браузере): https://gasparl.shinyapps.io/esdi/
Тем не менее, его также легко запустить с вашего ПК. Вам просто нужно запустить следующую команду в R :
shiny :: runGitHub( " esdi " , " gasparl " )` Для этой последней альтернативы, если у вас их еще нет, вам нужно установить R , а затем установить shiny пакет в R , например, введя install.packages("shiny") в консоль. Затем скопируйте строку shiny::runGitHub("esdi", "gasparl") например, в консоли и нажмите Enter. Необходимые компоненты будут автоматически загружены, а приложение откроется в новом окне.
Наконец, чтобы использовать приложение в любое время без доступа к Интернету, вы можете загрузить весь репозиторий (или просто app.r ) и запустить код в файле app.r. Для этого вам нужно будет установить все R -пакеты, используемые в коде (перечисленные в первых строках).
Чтобы быстро понять суть приложения, см. Примерный раздел ниже или см. Фон для общей мотивации. Далее следует подробное техническое объяснение.
Единственными настройками, которые влияют на ключевое соотношение SMD-диагностики, являются (соотношение) стандартных отклонений (SDS) значений предиктора для случаев и для контролей , которые представляют в целом предполагаемый SD для данных из положительных случаев и для данных из элементов управления соответственно (опять же, для более подробного объяснения, см. Фон и примеры разделов ниже). SDS следует оценивать на основе типичных SDS для случаев и контролей в данной области исследования. Тем не менее, различия в SD оказывают относительно небольшое влияние на результаты, и в большинстве случаев (где SD не известен или не может быть легко оценен), можно предположить, что оставление настроек по умолчанию ( 1 для обоих SD) все равно даст приблизительно правильные результаты (если случай SD / Control SD может быть очень большим или очень маленьким). Другими словами, настройки по умолчанию этого программного обеспечения, вероятно, применимы для большинства сценариев.
На основе заданного SDS, средние значения образцов автоматически рассчитываются для каждого из SMD, указанных в других настройках. ПРИМЕЧАНИЕ. Чтобы быть кратким и все же избегать аббревиатуры, SMD (стандартизированная средняя разница) указывается как «размер эффекта» для варианта и метки графиков на интерфейсе. Наборы данных генерируются для всех различных средств (с использованием двух постоянных SDS) с почти идеальным нормальным распределением. Спецификация SMDS довольно проста: начальное значение, конечное значение и шаг должен быть указан. Например, начало 0.2 , конец 0.6 и этап 0.1 будет определять следующие SMD: 0.2 , 0.3 , 0.4 , 0.5 , 0.6 . Меньший шаг (или более отдаленный запуск и конец) означает больше данных для расчета, и поэтому эти настройки могут существенно увеличить время расчета.
Важно помнить о разнице между (а) SMD между одиночными кондиционированиями («случай 1» против «случай 2») и (b) SMD между случаем и контролем одного условия («случай» против «контроля»). The first one (a) is indicative of differences in diagnostic efficiency between two diagnostic methods (eg an old method and a new improved method), while the second one (b) is merely an alternative measurement for diagnostic efficiency within a given method (eg the diagnostic efficiency of the old method), and this latter is always in direct positive correlation with the other diagnostic efficiency measures (so larger "case" vs. "control" SMD always means larger rate of Правильное обнаружение и большая площадь под кривой).
Первоначальный «случай 1» против «контроля» SMD представляет предполагаемую диагностическую эффективность метода, который будет улучшен (метод 1). (Примечание: это возможно, но на практике не имеет смысла включать в себя ноль для начальной стоимости, если только для демонстрационных целей, поскольку это будет означать, что метод 1 выполняется на уровне случайности, поэтому он в первую очередь бесполезен.) На участках изображена диагностика улучшенного метода (метод 2) ( точность: «Случай 2» по сравнению с «контролем» ) по отношению к «Случай 1». Случай 2 ». (Примечание: для ясности всегда полезно сохранить начальное значение «case 1» против «случая 2» SMD при нуле, что затем иллюстрирует отправную точку, в которой нет никакой разницы вообще между двумя методами.) Затем можно увидеть, как увеличение в SMD между «случай 1» и «случай 2» приводит к определенной степени повышения точности, для каждого указанного инициала точности, в качестве отдельного навеса).
Значения изображены двумя разными способами: как общая точность и как получена точность . Полученная точность рассчитывается просто как общая точность минус начальная (метод 1) Точность. Комбинированный график содержит оба типа, в то время как сюжеты изображают эти типы отдельно и могут быть изучены интерактивно путем падения над линиями с курсором, чтобы считать точные значения SMD и точности в заданных точках на графике (см. Пример ниже).
Поскольку размер выборки не является бесконечным, нормальное распределение никогда не может быть по -настоящему идеальным, и, следовательно, в расчетных результатах SMD будут возникнуть небольшие отклонения по сравнению с данными настройками SMD: например, один начальный SMD может быть назначен как 0.5 в настройках, но фактические результаты могут быть, например, 0.51 . Размер выборки (количество сгенерированных данных) может быть установлен под Sample size метки: большее число приводит к некоторому увеличению времени расчета, но более точными результатами. Размер выборки около 4000 обычно дает точность до двух дробной цифры, в то время как ок. 15000 может быть точным до трех дробных цифр. Важно отметить, что независимо от размера выборки (и соответствия настройках и результатам), отношение SMD и диагностики для данных результатов всегда является точным и правильным.
Настройки сюжета относятся к изображению данных и должны быть самостоятельными. Все значения для расчета участков доступны под вкладкой Table в интерактивной таблице данных.
Проспективный ( априори ) анализ мощности для определения требуемого размера выборки имеет решающее значение для поведенческих экспериментов (например, Perugini, 2018). Чтобы определить наименьший эффект интереса, необходимый для анализа мощности, идеальным способом является полагаться на объективное оправдание (Lakens, 2013; Lakens et al, 2018). Например, чтобы сравнить два различных метода диагностики, можно рассмотреть реальные последствия жизни данного увеличения скорости правильного обнаружения заболевания по сравнению с затратами размера выборки, необходимых для показа статистических данных для этого заданного увеличения. Исследователь может принять обоснованное и тщательное решение, которое стоит собрать, скажем, 120 участников, чтобы обнаружить повышение по меньшей мере на 8% в точности обнаружения: увеличение на 2% или даже на 0,1% также может иметь важные изменения в реальной жизни, но из -за ограниченных ресурсов не стоит собирать гораздо большие размеры выборки, необходимые для обнаружения таких меньших изменений.
Однако практическое значение не всегда так просты для оценки. В одном конкретном сценарии в экспериментальном дизайне два метода диагностики могут быть достоверно сравнить с использованием случаев однократных кондиционеров, пропуская контроль (она же «базовая линия» или «негативное состояние») с запасными ресурсами. Этот сценарий может произойти в любой из многих областей, применяющих бинарную классификацию, возможно, наиболее характерно в медицине. Гипотетическое заболевание может быть диагностировано с постоянной мерой x , которая обычно выше для людей с данным заболеванием (например, небольшой удар или покраснение в реакции на тест на укол кожи; положительные случаи), в то время как оно, как правило, одинаково для здоровых людей (например, нет или небольшая реакция на тест на укол кожи; отрицательные случаи). Таким образом, положительные случаи могут быть обнаружены с определенной точностью - но не идеально, потому что некоторые измерения в некоторой степени ошибочны и дают ошибочно низкие значения для положительных случаев. Если кто -то предложил улучшить процедуру для достижения более высоких значений в меру x , можно было бы напрямую сравнить два метода только в положительных случаях: поскольку мера всегда будет постоянной (низкой) в отрицательных случаях (здоровых людях), более высокие значения для положительных случаев означают, что процедура также будет иметь лучшую диагностическую эффективность.
Проблема здесь заключается в том, что величина эффекта для расчета потенциальной мощности находится между двумя положительными условиями, которые не имеют прямого последствия для практических последствий в диагностике. Настоящее программное обеспечение помогает, предоставляя оценки для диагностических значений эффективности (правильные показатели обнаружения и области в соответствии с кривыми) для заданных величин эффекта между только положительными условиями.
Это программное обеспечение было на самом деле вдохновлено исследованиями скрытого информационного теста (CIT): CIT может показать, что человек распознает соответствующий предмет зонда (например, конкретное оружие убийства, используемое в недавнем преступлении) среди других неактуальных предметов (например, другие правдоподобные оружия), основываясь на различных, например, более медленном реагировании на пробел по сравнению с небрежными предметами. Поскольку невинные люди не признают зонд как актуальный, их ответы в среднем не будут различаться между зондами и нерелевантными элементами. Следовательно, основываясь на более крупных различиях, не имеющих ярости ( PI ), виновных людей можно отличить от невинных. Важно отметить, что, поскольку PI всегда составляет около нуля для невинных, многие исследования сравнивают различные версии CIT, используя только группы виновных, с пониманием того, что более крупная группа PI означает для данной версии, что означает, что диагностическая эффективность также будет лучше, используя эту версию (то есть больше виновных людей может быть правильно отличается от невинных). Тем не менее, разница в среднем арифметическом среднем между двумя группами виновных (или связанным с этим SMD) на самом деле не имеет какого -либо разумного практического значения, и поэтому она не может быть использована для образованного решения по размеру выборки. Действительно, 13 из 24 исследований, собранных в недавнем метаанализе (Lukács & Specker, 2020), использовали сравнение с одним приготовлением, никто не сообщил о предварительном расчете мощности для размеров выборки, и даже интерпретация величин эффекта была основана на знаменитом коэне, но в конечном итоге, 2018).
Теперь этот мета-анализ также сообщил о среднем SDS (на основе 12 экспериментов) для случаев (группы виновных) и контролей (невинных групп), 33.6 и 23.5 соответственно-поэтому они могут использоваться в приложении ESDI в качестве входных значений для Case SD и Control SD . Тем не менее, использование значения по умолчанию 1 для обоих SDS фактически дает очень похожие результаты: в целом знание и предоставление точных оценок SD не являются жизненно важным (если случай SD / Control SD может быть очень большим или очень небольшим).
Предоставляя 33.6 и 23.5 для Case SD и Control SD , 4000 для размера выборки и оставляя все остальные настройки без изменений, основной комбинированный график будет выглядеть следующим образом:
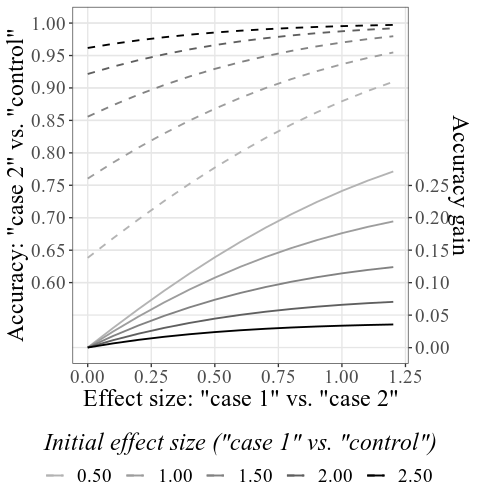
Обратите внимание, что - как подробно объяснено в разделе «Как использовать» выше - начальная точность рассчитывается на основе заданного начального SMD (см. Нижнюю метку; в разделе «Настройки графика» эта метка может быть изменена на точность отображения вместо SMD). Полученные SMD могут немного отличаться от SMD, приведенных в настройках, из -за процесса моделирования (опять же, см. Как использовать для технических деталей).
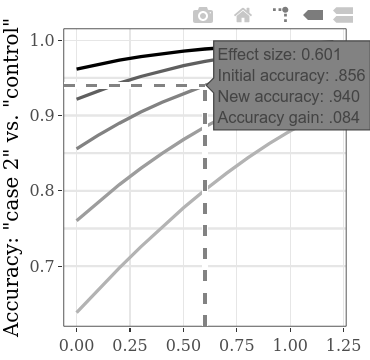
Повышение общей точности или аналогичной точности , в функции увеличения между кондиционированием (виновным 1 против виновного 2) SMD, может быть изучено отдельно на интерактивных сюжетах. Например, парящий над линией, как показано ниже, метка, которая появляется, показывает, что если мы обнаружим величину эффекта (SMD) 0,601 между результатами двух виновных групп, учитывая первоначальную точность 0,856 (скорость правильно обнаруженных лиц, как виновные, так и невинные), точность увеличивается на 0,084 (следовательно, давая новую точность .940). Если мы предположим, что начальная точность (то есть точность с использованием метода с низшей диагностической эффективностью) этого типа CIT действительно, как правило, около 0,856, мы можем использовать значения SMD на этой линии для расчета мощности. Например, с SMD 0,6 для мощности 0,9 требуемый размер выборки на группу составляет 60 (для непарного t-критерия с альфа = 0,05). Следовательно, чтобы статистически обнаружить увеличение, по крайней мере, на 0,084 по точности обнаружения, в общей сложности необходимо собрать 120 человек для двух условий вины.
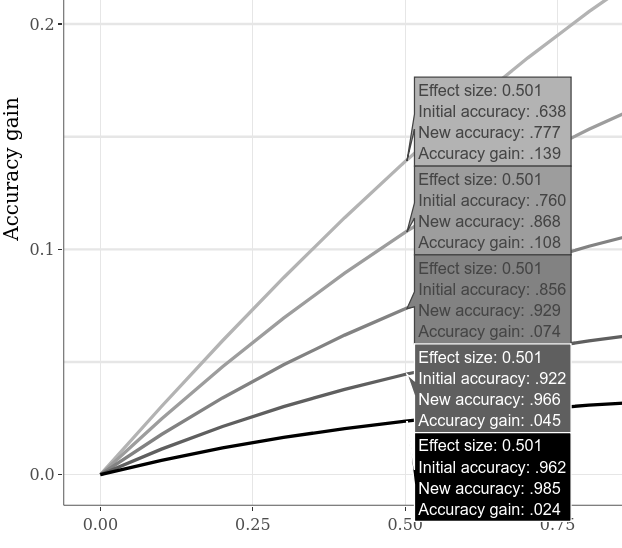
Альтернативная начальная точность можно сравнить, например, переключение на большую интерактивную вкладку Subsplots , щелкнув опцию «Сравните данные о падении» на нижнем графике и перемещая курсор горизонтально вдоль графика. В примере ниже показаны различные повышения точности, когда SMD «Case 1» против «Case 2» составляет 0,5. Как это было очевидно на предыдущих примерах, более низкая начальная точность всегда позволяет увеличить повышение точности.
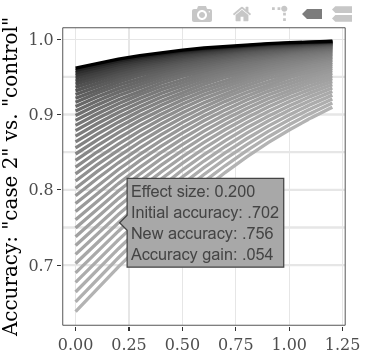
Чтобы исследовать более начальные стартовые значения одновременно, настройка шага для «Case 1» против «Control» SMD может быть снижена, что приводит к большему количеству линий на графике (и к некоторому увеличению времени расчета). (Шаг для «Случай 1» против «Случай 2» SMD аналогично приведет к большему горизонтальным данным.)
По умолчанию простые скорости правильного обнаружения (количество всех правильно классифицированных субъектов, разделенных по количеству всех субъектов) отображаются для измерения «точности», поскольку это, вероятно, является наиболее простым показателем диагностической эффективности. Его можно изменить на область под кривой под вкладкой «Сюжет» на левой панели. Под той же вкладкой также можно настроить метки сюжета.
Основная функциональность программного обеспечения может быть проверена с использованием пакета shinytest для запуска автоматизированного тестового костюма (например, после вклада). Просто запустите shinytest::recordTest("/path/to/directory/") - где "/path/to/directory/" должен быть заменен на путь к каталогу приложений, например "C:/apps/esdi/" .
Если у вас есть какие -либо вопросы или вы найдете какие -либо проблемы (ошибки, желаемые функции), напишите электронное письмо или откройте новую проблему.
Cohen, J. (1988). Статистический анализ мощности для поведенческих наук (2 -е изд.). Хиллсдейл, Нью -Джерси: Эрлбаум.
Лакенс Д. (2013). Расчеты и отчетность величины эффекта для облегчения кумулятивной науки: практическое праймер для T-тестов и ANOVA. Границы в психологии, 4. https://doi.org/10.3389/fpsyg.2013.00863
Lakens, D., Scheel, Am & Isager, PM (2018). Тестирование эквивалентности для психологических исследований: учебник. Достижения в методах и практике в области психологической науки, 1 (2), 259–269. https://doi.org/10.1177/2515245918770963
Perugini, M., Gallucci, M. & Costantini, G. (2018). Практический учебник для анализа мощности для простых экспериментальных дизайнов. Международный обзор социальной психологии, 31 (1), 20. https://doi.org/10.5334/irsp.181
Цитируйте это программное обеспечение как:
Lukács, G. & Specker, E. (2020). Размещение: диагностика и управление данными компьютерным моделированием в исследованиях скрытых тестирования информации. PLOS One, 15 (10), E0240259. https://doi.org/10.1371/journal.pone.0240259


