esdi
v1.0.1
使用给定输入值的模拟,此闪亮的R应用显示了与标准化平均差异( SMD )效应效果尺寸差异之间的诊断效率(通过正确检测率或曲线下的区域衡量)如何在单条件案例之间(对于缺乏对照组进行直接比较)。
该应用程序可在线提供(仅在任何网络浏览器中打开):https://gasparl.shinyapps.io/esdi/
但是,从PC运行它也很容易。您只需要在r中运行以下命令:
shiny :: runGitHub( " esdi " , " gasparl " )`对于后一种替代方案,如果您还没有它们,则需要安装R ,然后通过输入install.packages("shiny")进入控制台,然后在R中安装shiny软件包。然后复制shiny::runGitHub("esdi", "gasparl")例如在控制台中,然后按Enter。必要的组件将自动下载,并且应用程序将在新窗口中打开。
最后,要随时使用该应用程序,无需访问Internet即可,您可以下载整个存储库(或仅app.r )并在app.r文件中运行代码。为此,您需要安装代码中使用的所有R软件包(在第一行列出)。
要快速掌握应用程序的本质,请参见下面的示例部分,或者请参见一般动机的背景。下面是详细的技术解释。
影响关键SMD诊断关系的唯一设置是案例和对照的预测指标值的标准偏差(SD)(SD)的(比率),这些差异代表了来自正案例和对照组的数据的普遍假定的SD(再次,有关对照组的数据)(再次,有关更多解释,请参见下面的背景和示例部分)。应根据给定研究领域的病例和对照的典型SD估算SDS。但是,SD差异对结果的影响相对较小,并且在大多数情况下(如果SD尚不清楚或无法轻易估算),可以假设离开默认设置(两个1 )仍然会给出近似正确的结果(除非Case SD / Control SD可能非常大或很小)。换句话说,该软件的默认设置可能适用于大多数情况。
基于给定的SDS,针对其他设置下指定的每个SMD都会自动计算样品的均值。注意:要简要介绍,但要避免缩写,SMD(标准化的平均差异)表示为选项的“效果大小”和界面上的绘图标签。为所有不同方式(使用两个常规SDS)生成数据集,并具有接近完美的正态分布。 SMD的规范相当简单:必须给出一个起始值,最终值和步骤。 0.6 ,开始0.2 , 0.4为0.6和0.1 0.3步骤将0.5以下SMD: 0.2 。较小的步骤(或更遥远的启动和结束)意味着更多的数据点要计算,因此这些设置可以大大增加计算时间。
重要的是要牢记(a)单条件之间的SMD之间的差异(“案例1”与“案例2”)和(b)案例和单个条件控制之间的SMD(“ case”与“控制”)之间的差异。第一个(a)指示两种诊断方法之间的诊断效率差异(例如一种旧方法和新的改进方法),而第二个方法(b)仅是在给定方法内的诊断效率的替代测量,例如,在旧方法的诊断效率上始终具有更大的诊断效率(始终是较大的诊断效率(始终),因此始终是较大的诊断效率(因此'正确检测速率和曲线下的较大面积)。
初始“情况1”与“控制” SMD表示要改进的方法的诊断效率(方法1)。 (注意:实际上是可能的,但实际上毫无意义地包括零以进行起始价值,除非出于演示目的,因为这意味着该方法1在机会级别上执行,因此首先是无用的。)该地块描绘了改进的方法(方法2的诊断效率(准确性)(准确性:“ case 2“ vs.“ vs.“ vs.“ vs.“ vs.“ vs.“ vs.“ vs.“ vs.“ vs.”),” (请注意,为了清楚起见,保持“情况1”与“案例2” SMD的起始价值总是很好,然后说明了两种方法之间根本没有差异的起点。
值以两种不同的方式描述:作为总准确性,并获得准确性。获得的准确性简单地计算为总准确性减去初始(方法1)精度。组合图包含两种类型,而子图分别描绘了这些类型,并且可以通过与光标悬停在线路上以读取绘图上给定点的SMD和准确性的精确值来进行交互性探索(请参见下面的示例部分)。
由于样本量不是无限的,因此与给定的SMD设置相比,计算出的SMD结果中的正态分布永远不会真正完美,因此,在设置中可以给出一个初始SMD为0.5 ,但是实际结果可能是0.51 。样本量(生成数据点的数量)可以在标签Sample size下设置:较大的数量导致计算时间有所增加,但更精确的结果。大约4000的样本量通常会提供多达两个分数的精度,而大约则具有精度。 15000可能是最多三个分数。重要的是,无论样本量如何(以及设置和结果的对应关系),SMD和诊断与给定结果的关系始终是精确而正确的。
绘图设置与数据的描述有关,应该是自称的。该图的计算的所有值均在交互式数据表中的“表”选项卡下可用。
确定所需样本量的前瞻性(先验)功率分析对于行为实验至关重要(例如,Perugini,2018年)。为了确定功率分析所需的最小兴趣效果,理想的方法是依靠客观的理由(Lakens,2013; Lakens等,2018)。例如,要比较两种不同的诊断方法,一个人可能会考虑对疾病正确检测率提高的现实生活含义,这些疾病的率与显示给定增加的统计证据所需的样本量成本有关。研究人员可能会做出明智而谨慎的决定,例如,有120名参与者的检测到至少8%的检测准确性是值得的:增长2%甚至0.1%也可能具有重要的现实生活利益,但由于资源有限,因此不值得收集更大的样本数量来检测如此较小的更改所需的样本量。
但是,实际含义并不总是那么简单地评估。在实验设计的一种特定情况下,可以使用单条件案例进行有效比较两种诊断方法,从而省略控件(又称“基线”或“负条件”)以备用资源。这种情况可以发生在应用二元分类的许多领域中的任何一个,也许是医学中最特征的。假设疾病可能被诊断出具有连续测量X ,对于给定疾病的患者(例如对皮肤刺测的反应时,小凸起或发红;阳性病例)通常较高,而健康的人通常是相同的(例如,对皮肤刺测试或对皮肤刺测的反应或少数反应;阴性病例;阴性病例)。因此,可以以一定的精度检测到阳性案例 - 但不是完美的,因为某些测量值在某种程度上是错误的,并且对于阳性病例也错误的值也很低。如果某人提出了对度量X中更高值的程序进行改进,则可以直接将两种方法在阳性案例上进行比较:由于措施在负面病例(健康人员)中始终是恒定的(低)(健康的人),因此较高的阳性病例值也意味着该过程也将具有更好的诊断效率。
这里的问题在于,潜在功率计算的效果大小在两个积极条件之间,这对诊断的实际后果没有直接影响。目前的软件通过为仅积极条件之间的给定效应大小提供诊断效率值(正确的检测率和曲线下的区域)来提供帮助。
该软件实际上是受隐藏信息测试(CIT)研究的启发的:CIT可以揭示一个人认识到相关的探测项目(例如最近犯罪中使用的特定谋杀武器),以及其他无关的项目(例如其他可行的武器),例如,基于不同的探测器,与无关项目相比,对探测的响应较慢。由于无辜者不认为探针是相关的,因此他们的响应平均不会在探测器和无关的项目之间差异。因此,基于较大的探针 - 微级别( PI )差异,有罪的人可以与无辜者区分开。至关重要的是,由于无辜者的PI始终约为零,因此许多研究仅使用有罪的组比较了不同版本的CIT版本,并且了解到较大的PI组意味着给定版本的含义意味着使用该版本也可以更好地使用该版本(即更加有罪的人可以与无知的人脱颖而出)。但是,两个有罪群体(或相关SMD)之间算术平均值的差异实际上并没有任何明智的实际含义,因此不能用于对样本量的有根据的决定。实际上,在最近的荟萃分析(Lukács&Specker,2020)中收集的24项研究中,有13项使用了单条件比较,没有人报告样本量的先前功率计算,即使效应量的解释也基于Cohen的著名著名,但在内部任意基准中,但没有直接的实用含义,没有直接的实践含义(Cohen,1988年; Lakens Al; Lakens Al,2018)。
现在,这项荟萃分析还报告了病例(有罪组)和对照组(无辜组), 33.6和23.5的平均SD(基于12个实验),因此可以在ESDI应用中用作病例SD和控制SD的输入值。但是,使用两个SD的默认值1实际上都会给出非常相似的结果:通常,知道和给出精确的SD估计值并不重要(除非情况SD / Control SD比率可能非常大或很小)。
为案例SD和控制SD提供33.6和23.5 ,样本量为4000 ,并且将所有其他设置保持不变,主要组合图将看起来像这样:
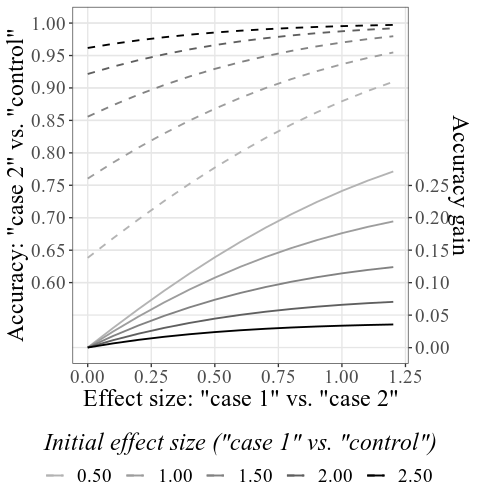
请注意,如上所述如何使用上面的部分中所述 - 基于给定的初始SMD(请参阅底部标签;在绘图设置下,可以更改此标签以显示精度而不是SMD)计算初始精度。由于模拟过程,所得的SMD可能与设置中给出的SMD略有不同(同样,请参见如何使用技术细节)。
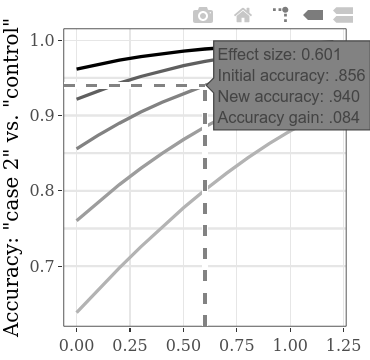
可以在相互作用的子图上分别探索条件间(有罪1与有罪2)SMD的提高(有罪1与有罪2)的增加(有罪1与有罪2)的功能。例如,如下所示,悬停在线上,似乎表明,如果我们在两个有罪组的结果之间发现效果大小(SMD)为0.601,则给定最初的准确性为.856(正确检测到的人的命中率,有罪和无辜的人),准确度的准确性将增加0.084(从而提高了0.084的精度)。如果我们假设这种类型的CIT的初始准确性(即使用具有较低诊断效率的方法的精度)确实通常在.856左右,则可以在此行上使用SMD值进行幂计算。例如,对于SMD 0.6,对于0.9的功率,每组所需的样本量为60(对于alpha = .05的未配对t检验)。因此,要从统计上检测到至少0.084的检测准确性的增加,在两个有罪条件下总共需要收集120人。
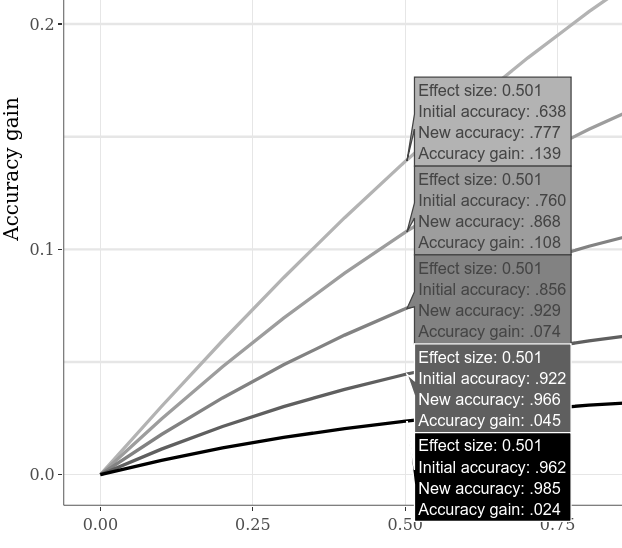
可以通过例如切换到“大型交互式子图”选项卡,单击较低图上的“悬停数据”选项,然后沿图水平移动光标。下面的示例显示了“案例1”与“案例2” SMD为0.5时的各种准确性。由于在上一个示例图上已经很明显,因此较低的初始精度始终允许更大的准确性增益。
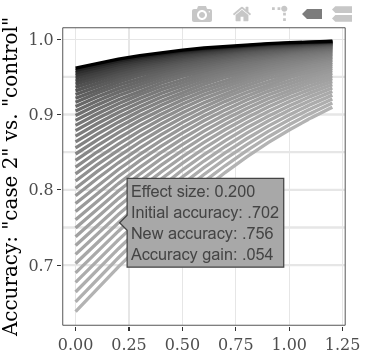
为了同时探索更多的初始启动值,可以降低“情况1”与“控制” SMD的步骤设置,从而导致图上有更多的线(并有所增加计算时间)。 (“情况1”与“情况2” SMD的步骤类似地导致更多的水平数据点。)
默认情况下,显示正确检测的简单速率(所有正确分类的受试者的数量除以所有受试者的数量)以“准确性”测量,因为这可能是诊断效率的最直接指标。它可以更改为左图中“绘图”选项卡下曲线下方的区域。在同一选项卡下,也可以自定义绘图标签。
可以使用shinytest软件包来验证该软件的基本功能以运行自动测试套装(例如,在做出贡献后)。只需运行shinytest::recordTest("/path/to/directory/") - 其中"/path/to/directory/"应该用应用程序目录的路径替换,例如"C:/apps/esdi/" 。
如果您有任何疑问或找到任何问题(错误,所需功能),请写电子邮件或打开新问题。
Cohen,J。(1988)。行为科学的统计能力分析(第二版)。新泽西州希尔斯代尔:埃尔鲍姆。
Lakens,D。(2013)。计算和报告效果大小以促进累积科学:t检验和方差分析的实用底漆。心理学领域,4。https://doi.org/10.3389/fpsyg.2013.00863
Lakens,D.,Scheel,AM和Isager,PM(2018)。心理学研究的等效测试:教程。心理科学方法和实践的进步,1(2),259–269。 https://doi.org/10.1177/2515245918770963
Perugini,M.,Gallucci,M。和Costantini,G。(2018)。用于简单实验设计的功率分析的实用入门。国际社会心理学评论,31(1),20。https://doi.org/10.5334/irsp.181
将此软件引用为:
Lukács,G。,&Specker,E。(2020)。分散事项:隐藏信息测试研究中的诊断和控制数据计算机模拟。 PLOS ONE,15 (10),E0240259。 https://doi.org/10.1371/journal.pone.0240259


