esdi
v1.0.1
指定された入力値のシミュレーションを使用して、この光沢のあるRアプリケーションは、診断効率(正しい検出のレートまたは曲線下の領域で測定されるように)を示しています)は、標準化された平均差( SMD )効果サイズの違い(これらがコントロールの欠如のために直接比較される場合)に関連してどのように変化するかを示します。
アプリケーションはオンラインで利用できます(任意のWebブラウザで単純に開くには):https://gasparl.shinyapps.io/esdi/
ただし、PCから簡単に実行することもできます。次のコマンドをRで実行する必要があります。
shiny :: runGitHub( " esdi " , " gasparl " )`この後者の代替案については、まだそれらを持っていない場合は、 rをインストールしてから、 install.packages("shiny")コンソールに入力して、 r eg内にshinyパッケージをインストールする必要があります。次に、 shiny::runGitHub("esdi", "gasparl")コンソールにコピーして、Enterを押します。必要なコンポーネントが自動的にダウンロードされ、アプリケーションが新しいウィンドウで開きます。
最後に、インターネットアクセスなしでいつでもアプリケーションを使用するには、リポジトリ全体(またはAPP.R )全体をダウンロードして、 APP.Rファイルでコードを実行できます。このためには、コードで使用されるすべてのRパッケージ(最初の行にリストされている)をインストールする必要があります。
アプリケーションの本質をすばやく把握するには、以下の例を参照するか、一般的な動機付けの背景を参照してください。ここに続くのは、詳細な技術的な説明です。
主要なSMD診断関係に影響を与える唯一の設定は、症例およびコントロールの予測値の(SDSの比率)(SDS)とコントロールからの一般的に想定されるSDを表します。これは、それぞれコントロールからのデータのSDを表します(再び、詳細については、以下の背景と例のセクションを参照)。 SDSは、特定の研究領域の症例とコントロールの典型的なSDSに基づいて推定する必要があります。ただし、SDの違いは結果に比較的影響が少なく、ほとんどの場合(SDが不明または容易に推定できない場合)、デフォルト設定(両方のSDの1 )を離れると、 SD /コントロールSDが非常に大きい場合または非常に小さい場合がない限り)。言い換えれば、このソフトウェアのデフォルト設定は、おそらくほとんどのシナリオに適用可能です。
指定されたSDSに基づいて、サンプルの平均は、他の設定で指定された各SMDについて自動的に計算されます。注:短時間でありながら略語を避けるために、SMD(標準化された平均差)は、オプションの「効果サイズ」とインターフェイス上のラベルをプロットするものとして示されます。データセットは、ほぼ完璧な正規分布を持つすべての異なる平均(2つの定数SDを使用)に対して生成されます。 SMDの仕様はかなり簡単です。開始値、最終値、およびステップを指定する必要があります。たとえば、 0.2の開始、 0.6の終了、および0.1のステップは、次のSMD 0.4 0.5 0.6ます: 0.2 0.3より小さなステップ(またはより遠い開始および終了)は、計算するためのより多くのデータポイントを意味するため、これらの設定は計算時間を大幅に増やすことができます。
(a)単一条件( "ケース1"対 "ケース2")の間のSMDと(b)ケースと単一条件の制御の間のSMD( "ケース"対コントロール ")の違いに留意することが重要です。最初のもの(a)は、2つの診断方法(例:古い方法と新しい改善された方法)間の診断効率の違いを示していますが、2番目(b)は、特定の方法内の診断効率のための代替測定(古い方法の診断効率など)にすぎません。曲線の下の広い領域)。
最初の「ケース1」対「コントロール」SMDは、改善する方法の想定される診断効率を表します(方法1)。 (注:可能ですが、実際には、デモンストレーションの目的でゼロを含めることはほとんど意味がありません。それは、方法1がチャンスレベルで実行されることを意味するため、最初の場所では役に立たないことを意味するためです。)プロットは、改良された方法(精度: "ケース2"対control " )を描写します。 (注:明確にするために、「ケース1」対「ケース2」SMDのゼロの開始値を維持することは常に良いことです。これは、2つの方法の間にまだ違いがない出発点を示しています。
値は、2つの異なる方法で描かれています。全体の精度と精度が得られるように。獲得した精度は、単に初期(方法1)精度を差し引いた合計精度を差し引いて計算されます。結合されたプロットには両方のタイプが含まれていますが、サブプロットはこれらのタイプを個別に描写し、カーソルとライン上でホバリングして、プロットの指定されたポイントでSMDの正確な値と精度を読み取ることでインタラクティブに調査できます(下のセクションを参照)。
サンプルサイズは無限ではないため、正規分布は真に完全になることはありません。したがって、指定されたSMD設定と比較して計算されたSMDの結果に小さな偏差があります。たとえば、設定では0.5として1つのSMDが与えられる場合がありますが、実際の結果は0.51です。サンプルサイズ(生成されたデータポイントの数)は、ラベルのSample sizeの下で設定できます。数が多いと計算時間がいくらか増加しますが、より正確な結果が得られます。約4000のサンプルサイズは通常、最大2つの分数桁まで精度を与えますが、CA。 15000 、最大3つの分数桁までの正確な場合があります。重要なことに、サンプルサイズ(および設定と結果の対応)に関係なく、与えられた結果のSMDと診断の関係は常に正確かつ正しいことです。
プロット設定は、データの描写に関連しており、自明である必要があります。プロットの計算のすべての値は、インタラクティブなデータテーブルのテーブルタブで使用できます。
必要なサンプルサイズを決定するための前向き(先験的)電力分析は、行動実験に重要です(例:Perugini、2018)。電力分析に必要な関心の最小効果を決定するために、理想的な方法は客観的正当化に依存することです(Lakens、2013; Lakens et al、2018)。たとえば、2つの異なる診断方法を比較するために、与えられた増加の統計的証拠を示すために必要なサンプルサイズのコストに関連して、疾患の正しい検出率の与えられた増加の実生活の影響を考慮することができます。研究者は、たとえば120人の参加者が検出精度で少なくとも8%の増加を検出することを収集する価値があるという情報に基づいた慎重な決定を下すことができます。2%または0.1%の増加も重要な現実の利益をもたらす可能性がありますが、リソースが限られているため、このような小さな変化を検出するために必要なはるかに大きなサンプルサイズを収集する価値はありません。
ただし、実際の意味は、評価がそれほど簡単ではありません。実験設計の1つの特定のシナリオでは、単一条件のケースを使用して2つの診断方法を有効に比較し、コントロール(「ベースライン」または「負」)を省略してリソースを省くことができます。このシナリオは、バイナリ分類を適用している多くの分野のいずれかで発生する可能性があります。おそらく最も特徴的には医学です。仮想疾患は、継続的な測定Xと診断される可能性があります。これは、通常、特定の疾患のある人(皮膚刺しテストに反応する小さな隆起や発赤など)でより高く、一般的に健康な人(皮膚の刺し傷に対する反応はないか、ネガティブケースなど)が同じです。これにより、肯定的なケースは一定の精度で検出できますが、完全には検出できませんが、一部の測定値はある程度欠陥があり、肯定的なケースの値も誤って低いためです。測定Xでより高い値を達成するための手順の改善を提案した場合、2つの方法を正のケースでのみ直接比較することが可能です。測定値は常に一定(健康な人)であるため、陽性の場合の値が高いと、手順がより良い診断効率を持つことを意味します。
ここでの問題は、潜在的な電力計算の効果サイズが2つの正の条件の間であり、診断における実際的な結果に直接的な意味を持たないことです。現在のソフトウェアは、正の条件だけで与えられた効果サイズの診断効率値(正しい検出率と曲線の下の領域)の推定を提供することで役立ちます。
このソフトウェアは、実際には隠された情報テスト(CIT)の研究に触発されました。CITは、人が関連するプローブ項目(最近の犯罪で使用されている特定の殺人兵器)を認識していることを明らかにすることができます。罪のない人はプローブを関連性があると認識していないため、彼らの応答は平均してプローブと無関係なアイテムの間で違いはありません。したがって、より大きなプローブ - マイナス傍観( PI )の違いに基づいて、有罪者は罪のない人と区別することができます。重要なことは、PIは常に罪のない人の場合はゼロであるため、多くの研究は有罪グループのみを使用してCITの異なるバージョンを比較し、特定のバージョンのPIグループが大きいと平均することは、診断効率がそのバージョンを使用してもより良いことを意味することを理解しています(すなわち、より有罪者は無実の人と正しく区別できます)。ただし、2つの有罪グループ(または関連するSMD)間の算術平均の違いは、実際には賢明な実用的な意味を持たないため、サンプルサイズに関する教育を受けた決定に使用することはできません。実際、最近のメタ分析(Lukács&Specker、2020)で収集された24の研究のうち13研究は単一条件の比較を使用しましたが、サンプルサイズの以前の電力計算を報告したものはなく、効果サイズの解釈でさえ、Cohenの有名であるが、最終的な任意のベンチマークに基づいていました。
現在、このメタ分析では、症例(有罪グループ)およびコントロール(無実のグループ)、 33.6および23.5の平均SDS(12の実験に基づく)も報告されています。そのため、ESDIアプリケーションではケースSDおよびコントロールSDの入力値として使用できます。ただし、両方のSDにデフォルト値1を使用すると、実際には非常に類似した結果が得られます。一般に、正確なSD推定を知ることと提供することは不可欠ではありません( SD /コントロールSD比が非常に大きい場合または非常に小さい場合を除きます)。
ケースSDおよびコントロールSDで33.6と23.5提供し、サンプルサイズには4000コントロールし、他のすべての設定を変更せずに、メインの組み合わせプロットは次のようになります。
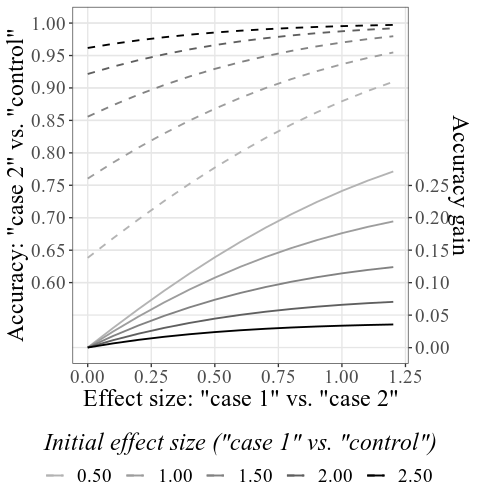
上記のセクションの使用方法の下で詳細に説明されているように、初期精度は指定された初期SMDに基づいて計算されます(下のラベルを参照してください。プロット設定では、このラベルをSMDの代わりに精度を表示するように変更できます)。結果のSMDは、シミュレーションプロセスのために、設定で与えられたSMDとわずかに異なる場合があります(繰り返しますが、技術的な詳細の使用方法を参照)。
総合精度の増加または類似の獲得精度は、条件間の増加(有罪1対有罪2)の増加の機能で、インタラクティブなサブプロットで個別に調査できます。たとえば、以下に示すようにライン上にホバリングすると、表示されるラベルは、2つの有罪グループの結果の間で0.601の効果サイズ(SMD)を見つけた場合、初期精度が.856(有罪と無罪の両方で正しく検出された人のレート)を示していることを示しています。このタイプのCITの初期精度(すなわち、診断効率が劣る方法を使用した精度)が実際には一般に約.856であると仮定すると、このラインのSMD値を電力計算に使用できます。たとえば、SMD 0.6の場合、.9のパワーの場合、グループあたりの必要なサンプルサイズは60です(Alpha = .05の対応のないt検定の場合)。したがって、検出精度で少なくとも.084の増加を統計的に検出するには、2つの有罪条件で合計120人を収集する必要があります。
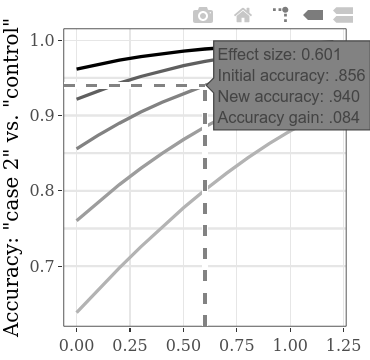
代替の初期精度は、たとえば、大きなインタラクティブサブプロットタブに切り替え、下部プロットの「ホバーのデータを比較する」オプションをクリックし、プロットに沿ってカーソルを水平に移動することで比較できます。以下の例は、「ケース1」対「ケース2」SMDが0.5の場合、さまざまな精度の向上を示しています。前の例ではすでに明らかであったため、初期精度を低くすると、常に精度が大きくなります。
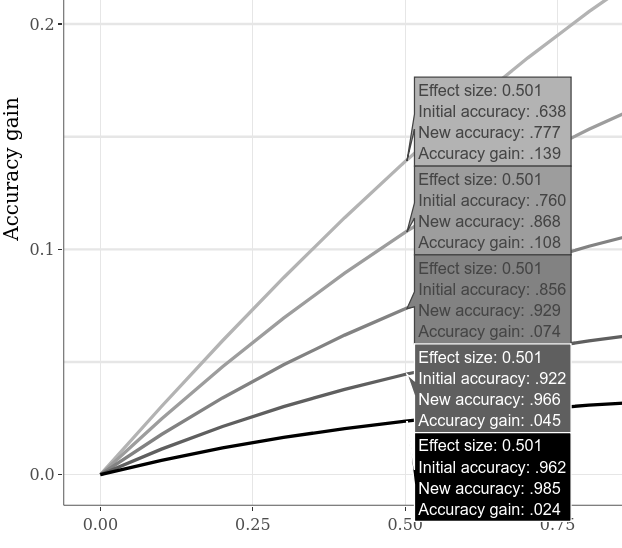
より多くの初期開始値を同時に調査するために、「ケース1」対コントロール」SMDのステップ設定を下げることができ、プロット上のより多くのライン(およびやや計算時間の増加)につながる可能性があります。 (「ケース1」対「ケース2」SMDのステップは、より水平なデータポイントを類似してもたらします。)
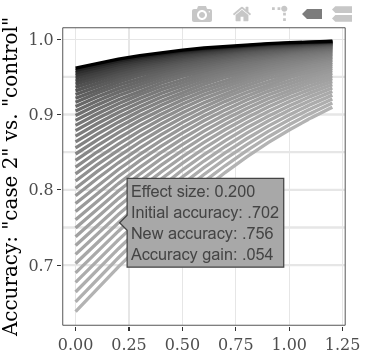
デフォルトでは、正しい検出の単純なレート(すべての被験者の数で割ったすべての正確に分類された被験者の数)が「精度」測定のために表示されます。これは、おそらく診断効率の最も簡単な指標であるためです。左パネルの[プロット]タブの下の曲線の下の面積に変更できます。同じタブで、プロットラベルもカスタマイズできます。
ソフトウェアの基本的な機能は、 shinytestパッケージを使用して自動化されたテストスーツを実行して検証できます(たとえば、寄付後)。 shinytest::recordTest("/path/to/directory/")実行するだけです。ここで、 "/path/to/directory/"は、 "C:/apps/esdi/"などのアプリケーションディレクトリへのパスに置き換える必要があります。
質問がある場合、または問題が見つかった場合(バグ、希望の機能)、メールを書き、新しい問題を開きます。
コーエン、J。(1988)。行動科学の統計パワー分析(第2版)。ニュージャージー州ヒルズデール:エルバウム。
Lakens、D。(2013)。累積科学を促進するための計算と報告効果のサイズ:t検定とANOVAの実用的なプライマー。心理学のフロンティア、4。https://doi.org/10.3389/fpsyg.2013.00863
Lakens、D.、Scheel、Am、&Isager、PM(2018)。心理研究の同等性テスト:チュートリアル。心理科学における方法と実践の進歩、1(2)、259–269。 https://doi.org/10.1177/2515245918770963
Perugini、M.、Gallucci、M。、&Costantini、G。(2018)。単純な実験設計のための電力分析への実用的な入門機。社会心理学の国際レビュー、31(1)、20。https://doi.org/10.5334/irsp.181
このソフトウェアを次のように引用してください。
Lukács、G。、&Specker、E。(2020)。分散の問題:隠された情報テスト研究における診断および制御データコンピューターシミュレーション。 PLOS ONE、15 (10)、E0240259。 https://doi.org/10.1371/journal.pone.0240259


