simplerecon
1.0.0
這是使用培訓和測試MVS深度估計模型的參考Pytorch實現。
SimplereCon:3D重建而無需3D卷積
Mohamed Sayed,John Gibson,Jamie Watson,Victor Adrian Prisacariu,Michael Firman和ClémentGodard
論文,ECCV 2022(ARXIV PDF),補充材料,項目頁面,視頻
此代碼用於非商業用途;請參閱許可證文件以獲取條款。如果您確實找到了本代碼庫的任何部分,請使用下面的bibtex引用我們的論文,然後鏈接此倉庫。謝謝!
25/05/2023:修復了llvm-openmp , clang和protobuf的固定包裝方面。如果您在運行代碼時遇到困難,請使用此新的環境文件,並且/或如果數據加載僅限於單個線程。
09/03/2023:將Kornia版本添加到環境文件中,以解決Kornia鍵入問題。 (謝謝@natesimon!)
26/01/2023:已修改了許可證,以使運行模型出於學術原因更容易。請提供確切詳細信息的許可證文件。
截至2022年3月31日,有一個更新可以修復稍微錯誤的內在插圖,成本量的翻轉增強以及投影中的數值精度錯誤。所有分數都在提高。您需要更新叉子並使用新的權重。請參閱錯誤修復。
在線默認幀的預定掃描在這裡:https://drive.google.com/drive/folders/1dsofi9gayyhqjsx4i_ng0-3ebcafwxjv?usp = share_link
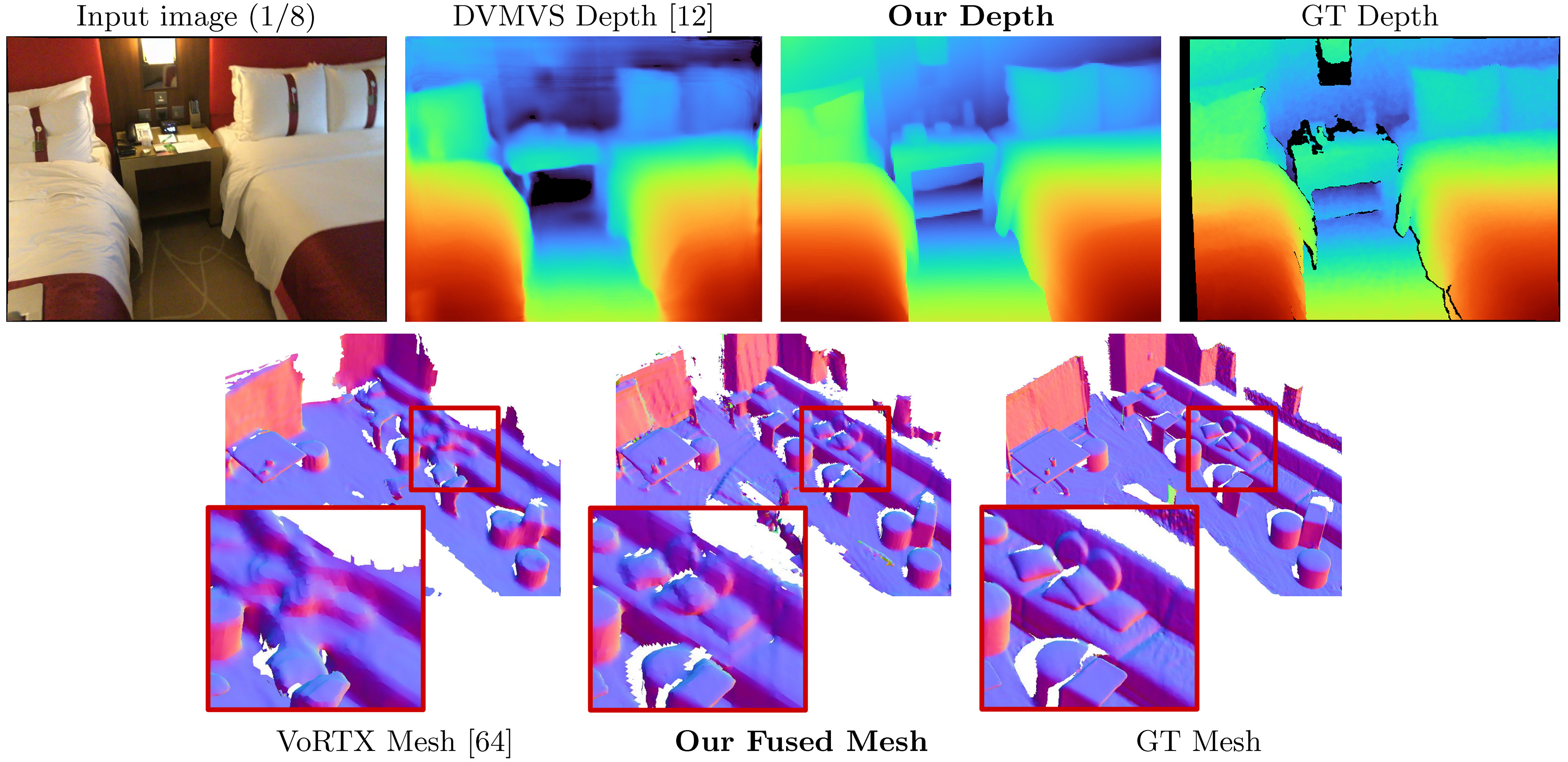
SimpleRecon作為輸入姿勢的RGB圖像,並為目標圖像輸出深度圖。
假設有新的Anaconda發行版,您可以使用以下方式安裝依賴項
conda env create -f simplerecon_env.yml我們使用Pytorch 1.10,Cuda 11.3,Python 3.9.7和Debian GNU/Linux 10進行實驗。
將驗證的型號下載到weights/文件夾中。
我們提供以下模型(分數與在線默認鍵框一起使用):
--config | 模型 | ABS差異↓ | SQ Rel↓ | delta <1.05↑ | 倒角↓ | F-SCORE↑ |
|---|---|---|---|---|---|---|
hero_model.yaml | 元數據 +重新連接匹配 | 0.0868 | 0.0127 | 74.26 | 5.69 | 0.680 |
dot_product_model.yaml | 點產品 +重新連接匹配 | 0.0910 | 0.0134 | 71.90 | 5.92 | 0.667 |
hero_model是我們在論文中使用的那個
--config | 模型 | 推理速度( --batch_size 1 ) | 推理GPU內存 | 近似訓練時間 |
|---|---|---|---|---|
hero_model | 英雄,元數據 +重新連接 | 130ms / 70ms(優化速度) | 2.6GB / 5.7GB(優化速度) | 36小時 |
dot_product_model | 點產品 +重新連接 | 80ms | 2.6GB | 36小時 |
隨著較大的批次,速度大大提高。在非速度優化模型上,批量尺寸為8,潛伏期下降到約40ms。
datasets/arkit_dataset.py上。更新:現在有一個快速讀取文件data_scripts/ios_logger_arkit_readme.md,用於使用data_scripts/ios_logger_preprocessing.py的腳本處理和運行iOS-Logger掃描。 現在,我們包括了兩次掃描供人們立即嘗試使用該代碼的掃描。您可以從這裡下載這些掃描。
步驟:
hero_model的權重下載到權重目錄中。configs/data/vdr_dense.yaml中選項dataset_path的值修改為未拉鍊VDR文件夾的基本路徑。CUDA_VISIBLE_DEVICES=0 python test.py --name HERO_MODEL
--output_base_path OUTPUT_PATH
--config_file configs/models/hero_model.yaml
--load_weights_from_checkpoint weights/hero_model.ckpt
--data_config configs/data/vdr_dense.yaml
--num_workers 8
--batch_size 2
--fast_cost_volume
--run_fusion
--depth_fuser open3d
--fuse_color
--dump_depth_visualization ;這將輸出網格,快速深度和SOCRES在OUTPUT_PATH下對LIDAR深度進行基準測試時。
此命令使用vdr_dense.yaml ,該命令將為每個幀生成深度並將其融合到網格中。在論文中,我們改用Fuse KeyFrames報告得分,您可以使用vdr_default.yaml運行那些。您也可以通過使用vdr_dense_offline.yaml來使用dense_offline元組。
請參閱下面的測試和評估部分。確保為數據集使用正確的配置標誌。
請在此處按照說明下載數據集。該數據集很大(> 2TB),因此請確保您有足夠的空間,尤其是用於提取文件。
下載後,使用此腳本將原始傳感器數據導出到圖像和深度文件。
我們已經編寫了一個快速教程,並包含了修改的腳本,以幫助您下載和提取ScannETV2。您可以在data_scripts/scannet_wrangling_scripts/可以找到它們
您應該更改configs/ data/ in configs/data/ config的數據dataset_path config參數,以匹配數據集所在的位置。
代碼庫希望ScannETV2處於以下格式:
dataset_path
scans_test (test scans)
scene0707
scene0707_00_vh_clean_2.ply (gt mesh)
sensor_data
frame-000261.pose.txt
frame-000261.color.jpg
frame-000261.color.512.png (optional, image at 512x384)
frame-000261.color.640.png (optional, image at 640x480)
frame-000261.depth.png (full res depth, stored scale *1000)
frame-000261.depth.256.png (optional, depth at 256x192 also
scaled)
scene0707.txt (scan metadata and image sizes)
intrinsic
intrinsic_depth.txt
intrinsic_color.txt
...
scans (val and train scans)
scene0000_00
(see above)
scene0000_01
....
在此示例中, scene0707.txt應包含掃描的元數據:
colorHeight = 968
colorToDepthExtrinsics = 0.999263 -0.010031 0.037048 ........
colorWidth = 1296
depthHeight = 480
depthWidth = 640
fx_color = 1170.187988
fx_depth = 570.924255
fy_color = 1170.187988
fy_depth = 570.924316
mx_color = 647.750000
mx_depth = 319.500000
my_color = 483.750000
my_depth = 239.500000
numColorFrames = 784
numDepthFrames = 784
numIMUmeasurements = 1632
frame-000261.pose.txt應包含形式的姿勢:
-0.384739 0.271466 -0.882203 4.98152
0.921157 0.0521417 -0.385682 1.46821
-0.0587002 -0.961035 -0.270124 1.51837
frame-000261.color.512.png和frame-000261.color.640.png是原始圖像的調整大小版本,以節省訓練和測試期間的負載和計算時間。 frame-000261.depth.256.png也是深度圖的縮小評估版本。
所有調整大小的刻板版本的深度和圖像都很不錯,但不是必需的。如果它們不存在,則將加載完整的分辨率版本,並隨時刪除。
默認情況下,我們估計掃描中每個密鑰幀的深度圖。我們使用DeepVideOMVS的啟發式式啟發式框架分開,並構建元素以匹配。我們在這些密鑰幀上使用深度圖進行深度融合。對於每個密鑰幀,我們將用於構建成本量的源框架列表關聯。我們還使用密集的元素,在其中預測數據中每個幀的深度圖,而不僅僅是在特定的密鑰幀中;這些主要用於可視化。
我們在所有充當數據集元素的掃描中生成和導出一個單元列表。我們已經預先計算了這些列表,並且可以在每個數據集拆分下的data_splits上找到。對於掃描儀的測試掃描,它們在data_splits/ScanNetv2/standard_split上。我們的核心深度編號是使用data_splits/ScanNetv2/standard_split/test_eight_view_deepvmvs.txt計算的。
這是用於測試類型的類型的快速分類群:
default :遵循所有源框架過去的DeepVideOmvs的每個密鑰幀的元組。除非另有說明,否則用於所有深度和網格評估。用於掃描,使用data_splits/ScanNetv2/standard_split/test_eight_view_deepvmvs.txt 。offline :掃描中的每個幀的元組,在過去和將來相對於當前幀都可以是源框架。當一個場景離線捕獲時,這些都是有用的,您希望能夠獲得最佳準確性。使用在線元組,隨著相機移開,所有源框架都落後時,成本量將包含空區域。但是,對於離線元組,兩端的成本量都已飽滿,從而實現了更好的規模(和度量)估計。dense :用於掃描中所有源框架的掃描中的每個幀的在線元組(如默認)。對於掃描,這將是data_splits/ScanNetv2/standard_split/test_eight_view_deepvmvs_dense.txt 。offline :用於掃描中每個密鑰幀的每個密鑰幀的離線元組。對於火車和驗證集,我們遵循與DeepVideOMV中相同的元組增強策略,並使用相同的核心生成腳本。
如果您想自己生成這些元組,則可以在data_scripts/generate_train_tuples.py上使用train元組和data_scripts/generate_test_tuples.py進行測試元組。這些遵循與test.py相同的配置格式,並將使用您構建的任何數據集類別讀取姿勢Informaiton。
測試示例:
# default tuples
python ./data_scripts/generate_test_tuples.py
--data_config configs/data/scannet_default_test.yaml
--num_workers 16
# dense tuples
python ./data_scripts/generate_test_tuples.py
--data_config configs/data/scannet_dense_test.yaml
--num_workers 16火車的示例:
# train
python ./data_scripts/generate_train_tuples.py
--data_config configs/data/scannet_default_train.yaml
--num_workers 16
# val
python ./data_scripts/generate_val_tuples.py
--data_config configs/data/scannet_default_val.yaml
--num_workers 16這些腳本將首先檢查數據集中的每個幀,以確保其具有現有的RGB幀,現有的深度幀(如果適用於數據集)以及現有和有效的姿勢文件。它將這些valid_frames保存在每個掃描文件夾中的文本文件中,但是如果僅讀取目錄,它將忽略保存valid_frames文件並生成元組。
您可以使用test.py來推斷和評估深度圖和融合網格。
所有結果將存儲在基本結果文件夾(Results_path):
opts.output_base_path/opts.name/opts.dataset/opts.frame_tuple_type/
opts是options類。例如,當opts.output_base_path是./results時, opts.name是HERO_MODEL , opts.dataset是scannet , opts.frame_tuple_type是default ,輸出目錄將為
./results/HERO_MODEL/scannet/default/
確保將--opts.output_base_path設置為適合您存儲結果的目錄。
--frame_tuple_type是用於MVS的圖像元組類型。您使用的data_config文件中應提供選擇。
默認情況下, test.py將嘗試計算每個幀的深度分數,並提供平均和場景平均指標。腳本將在results_path/scores下節省這些分數(每個場景和總數)。
我們已經盡最大努力確保通過匹配的編碼器進行火炬批處理錯誤,以通過(<10^-4)通過該編碼禁用圖像批處理進行(<10^-4)精確測試。運行--batch_size 4最多有疑問,如果您想獲得盡可能穩定的數字並避免使用pytorch gremlins,請使用--batch_size 1進行比較評估。
如果您想將其用於速度,請設置--fast_cost_volume為true。這將啟用通過匹配編碼器進行批處理,並啟用EINOPS優化的特徵量。
# Example command to just compute scores
CUDA_VISIBLE_DEVICES=0 python test.py --name HERO_MODEL
--output_base_path OUTPUT_PATH
--config_file configs/models/hero_model.yaml
--load_weights_from_checkpoint weights/hero_model.ckpt
--data_config configs/data/scannet_default_test.yaml
--num_workers 8
--batch_size 4 ;
# If you'd like to get a super fast version use:
CUDA_VISIBLE_DEVICES=0 python test.py --name HERO_MODEL
--output_base_path OUTPUT_PATH
--config_file configs/models/hero_model.yaml
--load_weights_from_checkpoint weights/hero_model.ckpt
--data_config configs/data/scannet_default_test.yaml
--num_workers 8
--fast_cost_volume
--batch_size 2 ;該腳本也可用於執行一些不同的輔助任務,包括:
TSDF融合
運行TSDF融合提供--run_fusion標誌。您有兩個選擇保險箱的選擇
--depth_fuser ours (默認值)將使用我們的定影器,其網格在大多數可視化和分數中都使用。該定影器不支持顏色。我們為Scikit-Image的自定義分支提供了measure.matching_cubes的自定義實現。 Matching_cubes,允許單個圍牆。我們使用單壁網格進行評估。如果這對您不重要,則可以將export_single_mesh設置為False in test.py中的export_mesh 。--depth_fuser open3d將使用Open3D深度定影。該定影器支持顏色,您可以使用--fuse_color標誌來啟用此功能。默認情況下,將使用深度圖剪輯至3M以進行融合,將使用0.04m 3的TSDF分辨率,但是您可以通過更改--max_fusion_depth and --fusion_resolution更改)。
您可以選擇使用--mask_pred_depths不存在VAIID MVS信息時,要求將用於融合的預測深度掩蓋。默認情況下不啟用這一點。
您還可以融合成本量編碼器的成本量的最佳猜測深度,該成本量編碼器引入了強大的圖像。您可以使用--fusion_use_raw_lowest_cost來執行此操作。
網格將存儲在results_path/meshes/下。
# Example command to fuse depths to get meshes
CUDA_VISIBLE_DEVICES=0 python test.py --name HERO_MODEL
--output_base_path OUTPUT_PATH
--config_file configs/models/hero_model.yaml
--load_weights_from_checkpoint weights/hero_model.ckpt
--data_config configs/data/scannet_default_test.yaml
--num_workers 8
--run_fusion
--batch_size 8 ;緩存深度
您可以選擇通過提供--cache_depths標誌來存儲深度。它們將存儲在results_path/depths中。
# Example command to compute scores and cache depths
CUDA_VISIBLE_DEVICES=0 python test.py --name HERO_MODEL
--output_base_path OUTPUT_PATH
--config_file configs/models/hero_model.yaml
--load_weights_from_checkpoint weights/hero_model.ckpt
--data_config configs/data/scannet_default_test.yaml
--num_workers 8
--cache_depths
--batch_size 8 ;
# Example command to fuse depths to get color meshes
CUDA_VISIBLE_DEVICES=0 python test.py --name HERO_MODEL
--output_base_path OUTPUT_PATH
--config_file configs/models/hero_model.yaml
--load_weights_from_checkpoint weights/hero_model.ckpt
--data_config configs/data/scannet_default_test.yaml
--num_workers 8
--run_fusion
--depth_fuser open3d
--fuse_color
--batch_size 4 ;快速
還有其他腳本可以更深入地可視化輸出深度和融合,但是為了快速導出深度圖可視化,您可以使用--dump_depth_visualization 。可視化將存儲在results_path/viz/quick_viz/ 。
# Example command to output quick depth visualizations
CUDA_VISIBLE_DEVICES=0 python test.py --name HERO_MODEL
--output_base_path OUTPUT_PATH
--config_file configs/models/hero_model.yaml
--load_weights_from_checkpoint weights/hero_model.ckpt
--data_config configs/data/scannet_default_test.yaml
--num_workers 8
--dump_depth_visualization
--batch_size 4 ; 我們還允許使用3DVNET存儲庫中的Fuser進行深度圖的點雲融合。
# Example command to fuse depths into point clouds.
CUDA_VISIBLE_DEVICES=0 python pc_fusion.py --name HERO_MODEL
--output_base_path OUTPUT_PATH
--config_file configs/models/hero_model.yaml
--load_weights_from_checkpoint weights/hero_model.ckpt
--data_config configs/data/scannet_dense_test.yaml
--num_workers 8
--batch_size 4 ;將configs/data/scannet_dense_test.yaml更改為configs/data/scannet_default_test.yaml僅在您不想等待太久的情況下才使用鍵框。
我們在主要結果表中使用TransformerFusion的網格評估,但在隨機採樣網格時將種子設置為固定值。我們還在補充材料中使用NeuralRecon的評估報告了網格指標。
為了進行點雲評估,我們使用TransformerFusion的代碼,但在點雲中加載代替對網格表面進行採樣。
默認情況下,將模型和張板事件文件保存到~/tmp/tensorboard/<model_name> 。可以使用--log_dir標誌更改。
我們在默認的ScannETV2 Split上以16位精度為16位精度進行訓練。
示例命令訓練兩個GPU:
CUDA_VISIBLE_DEVICES=0,1 python train.py --name HERO_MODEL
--log_dir logs
--config_file configs/models/hero_model.yaml
--data_config configs/data/scannet_default_train.yaml
--gpus 2
--batch_size 16 ;該代碼支持任何數量的GPU用於培訓。您可以指定在CUDA_VISIBLE_DEVICES環境中使用的GPU。
我們所有的訓練均在兩個NVIDIA A100上進行。
不同的數據集
您可以通過編寫新的數據加載程序類在自定義MVS數據集上進行訓練,該類別從datasets/generic_mvs_dataset.py繼承了從GenericMVSDataset繼承。有關示例,請參見datasets/scannet_dataset.py中的ScannetDataset類或datasets集中的任何其他類。
為了芬特,簡單加載一個檢查站(不簡歷!),然後從那裡訓練:
CUDA_VISIBLE_DEVICES=0 python train.py --config configs/models/hero_model.yaml
--data_config configs/data/scannet_default_train.yaml
--load_weights_from_checkpoint weights/hero_model.ckpt將數據配置更改為您要列出的任何數據集。
options.py其他培訓選項的範圍,例如學習率和消融設置以及測試選項。
除了test.py腳本中的快速深度可視化外,還有兩個可視化深度輸出的腳本。
第一個是visualization_scripts/visualize_scene_depth_output.py 。這將產生一個帶有參考和源框架的顏色圖像,深度預測,成本量估計,GT深度以及深度估計的正態的視頻。腳本假設您使用test.py緩存了深度輸出,並且接受與test.py相同的命令模板格式:
# Example command to get visualizations for dense frames
CUDA_VISIBLE_DEVICES=0 python ./visualization_scripts/visualize_scene_depth_output.py --name HERO_MODEL
--output_base_path OUTPUT_PATH
--data_config configs/data/scannet_dense_test.yaml
--num_workers 8 ;其中OUTPUT_PATH是SimpleRecon的基本結果目錄(您開始使用測試的內容)。您可以選擇運行.visualization_scripts/generate_gt_min_max_cache.py在此腳本之前,以獲取用於colormapping的最低和最大深度值的平均場景;如果這些不可用,則腳本將使用0m和5m用於Colomapping Min和Max。
第二個允許實時可視化網格鏈。該腳本將使用緩存的深度圖(如果有),否則它將使用該模型在融合之前預測它們。該腳本將在深度圖上迭代加載,融合它,在此步驟中保存網格文件,並將此網格與birdseye視頻的相機標記呈現,以及從相機的角度來看FPV視頻。
# Example command to get live visualizations for mesh reconstruction
CUDA_VISIBLE_DEVICES=0 python visualize_live_meshing.py --name HERO_MODEL
--output_base_path OUTPUT_PATH
--config_file configs/models/hero_model.yaml
--load_weights_from_checkpoint weights/hero_model.ckpt
--data_config configs/data/scannet_dense_test.yaml
--num_workers 8 ;默認情況下,腳本將將網格保存到中間位置,您可以選擇加載這些網段,以節省時間,通過傳遞--use_precomputed_partial_meshes再次可視化相同的網格。所有中間網格都必須在先前的運行中計算才能正常工作。
tl; dr: world_T_cam == world_from_cam
此存儲庫使用符號“ CAM_T_WORLD”表示從世界到相機點(外部)的轉換。目的是使坐標幀名稱在變量的任一側都匹配,而在乘以從右到左的乘法。
cam_points = cam_T_world @ world_points
world_T_cam表示相機姿勢(從凸輪到世界坐標)。 ref_T_src表示從源到參考視圖的轉換。
最後,該符號允許表示旋轉和翻譯,例如: world_R_cam和world_t_cam
此存儲庫適用於掃描儀,因此儘管其功能應允許任何坐標系(通過輸入標誌發出信號),但我們提供的模型權重假定掃描儀坐標系。這很重要,因為我們將光線信息作為元數據的一部分。這些權重的其他數據集應轉換為掃描儀系統。我們包括的數據集類將執行適當的轉換。
此更新中有一些錯誤,您將需要更新叉子,並在此讀數開頭附近使用桌子上的新權重。您還需要確保使用閱讀器提取了正確的內在文件。
感謝所有指出的內容,並在我們進行修復時耐心等待。
這些修復程序都可以提高所有分數,並且相關的權重在此處上傳。對於舊分數,代碼和權重,請檢查此提交哈希:7DE5B451E340F9A11C7FD67BD0C42204D0B009A9
帶有錯誤修復的模型的完整分數:
深度
--config | ABS差異↓ | ABS REL↓ | SQ Rel↓ | RMSE↓ | 日誌RMSE↓ | delta <1.05↑ | delta <1.10↑ |
|---|---|---|---|---|---|---|---|
hero_model.yaml ,元數據 +重新連接 | 0.0868 | 0.0428 | 0.0127 | 0.1472 | 0.0681 | 74.26 | 90.88 |
dot_product_model.yaml ,點產品 + resnet | 0.0910 | 0.0453 | 0.0134 | 0.1509 | 0.0704 | 71.90 | 89.75 |
網狀融合
--config | ACC↓ | Comp↓ | 倒角↓ | 回想↑ | 精度↑ | F-SCORE↑ |
|---|---|---|---|---|---|---|
hero_model.yaml ,元數據 +重新連接 | 5.41 | 5.98 | 5.69 | 0.695 | 0.668 | 0.680 |
dot_product_model.yaml ,點產品 + resnet | 5.66 | 6.18 | 5.92 | 0.682 | 0.655 | 0.667 |
比較:
--config | 模型 | ABS差異↓ | SQ Rel↓ | delta <1.05↑ | 倒角↓ | F-SCORE↑ |
|---|---|---|---|---|---|---|
hero_model.yaml | 元數據 +重新連接匹配 | 0.0868 | 0.0127 | 74.26 | 5.69 | 0.680 |
舊的hero_model.yaml | 元數據 +重新連接匹配 | 0.0885 | 0.0125 | 73.16 | 5.81 | 0.671 |
dot_product_model.yaml | 點產品 +重新連接匹配 | 0.0910 | 0.0134 | 71.90 | 5.92 | 0.667 |
舊dot_product_model.yaml | 點產品 +重新連接匹配 | 0.0941 | 0.0139 | 70.48 | 6.29 | 0.642 |
最初,此存儲庫吐出元組文件,用於默認的DVMVS樣式鍵框,用於ScannETV2測試集的9個額外的25599幀。現在有一個較小的錯誤,處理丟失的跟踪現在已經固定了。現在,此存儲庫應完全模仿DVMVS鍵幀緩衝區,並使用25590個密鑰幀進行測試。該錯誤的唯一影響是包含9個額外的框架,所有其他元組都與DVMV完全相同。有問題的框架在這些掃描中
scan previous count new count
--------------------------------------
scene0711_00 393 392
scene0727_00 209 208
scene0736_00 1023 1022
scene0737_00 408 407
scene0751_00 165 164
scene0775_00 220 219
scene0791_00 227 226
scene0794_00 141 140
scene0795_00 102 101
默認測試的元組文件已更新。由於這是額外評分的額外框架差異很小(〜3E-4),因此得分沒有變化。
TL; DR:縮放您的姿勢並裁剪圖像。
我們確實提供了一個數據加載器,用於從Colmap稀疏重建中加載圖像。為此,要與SimpleRecon一起使用,您需要裁剪圖像以匹配掃描儀的FOV(大致類似於視頻模式下的iPhone FOV),並使用已知的現實世界測量值來擴展姿勢的位置。如果未採取這些步驟,則無法正確構建成本量,並且網絡將無法正確估計深度。
我們感謝TransformerFusion的AljažBožič,Neural Recon的Jiaming Sun和DeepVideOmvs的ArdaDüzççeker迅速提供有用的信息來幫助基線並使其代碼庫隨時可用,尤其是在短時間內。
元組一代腳本大量使用了DeepVideOmvs的KeyFrame Buffer的修改版本(再次感謝Arda and Co!)。
torch_point_cloud_fusion CODE上的Pytorch點雲融合模塊是從3DVNET的存儲庫中藉用的。謝謝亞歷山大·里奇!
我們還要感謝Niantic的基礎設施團隊在需要時採取的快速行動。謝謝伙計們!
Mohamed由Microsoft Research PhD獎學金(MRL 2018-085)資助。
如果您發現我們的工作對您的研究有用,請考慮引用我們的論文:
@inproceedings{sayed2022simplerecon,
title={SimpleRecon: 3D Reconstruction Without 3D Convolutions},
author={Sayed, Mohamed and Gibson, John and Watson, Jamie and Prisacariu, Victor and Firman, Michael and Godard, Cl{'e}ment},
booktitle={Proceedings of the European Conference on Computer Vision (ECCV)},
year={2022},
}
版權所有©Niantic,Inc。 2022。申請專利。版權所有。請參閱許可證文件以獲取條款。


