simplerecon
1.0.0
Это эталонная реализация Pytorch для обучения и тестирования моделей оценки глубины MVS с использованием метода, описанного в
SimpleereCon: 3D реконструкция без трехмерных свертков
Мохамед Сайед, Джон Гибсон, Джейми Уотсон, Виктор Адриан Присакариу, Майкл Фирман и Климент Годард
Paper, ECCV 2022 (ARXIV PDF), Дополнительный материал, страница проекта, видео
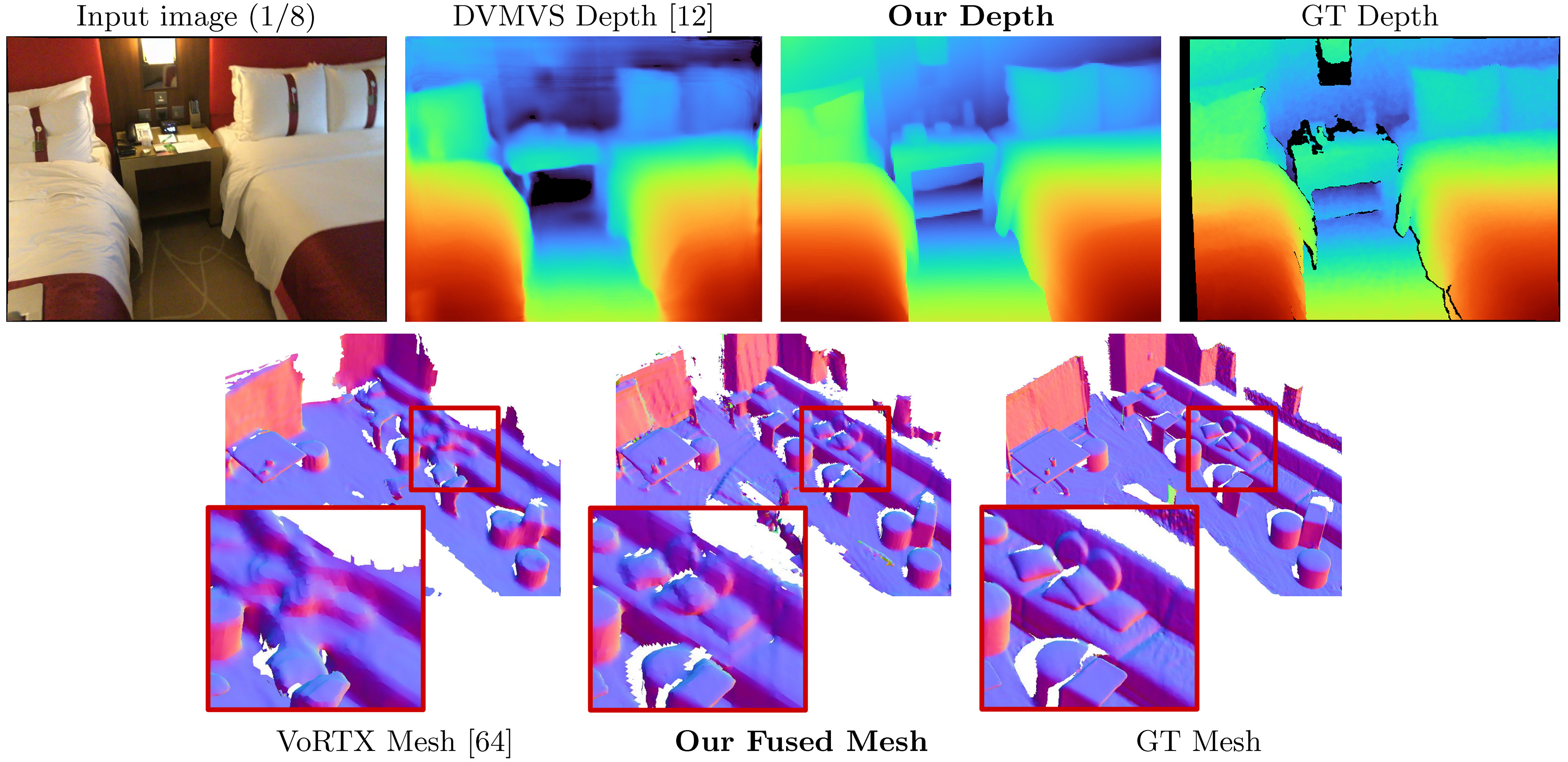
Этот код предназначен для некоммерческого использования; Пожалуйста, смотрите файл лицензии для условий. Если вы найдете какую -либо часть этой кодовой базы полезной, пожалуйста, процитируйте нашу статью, используя Bibtex ниже и свяжите это репо. Спасибо!
25/05/2023: фиксированные версии упаковки для llvm-openmp , clang и protobuf . Используйте этот новый файл среды, если у вас возникли проблемы с запуском кода и/или если DataLoading ограничивается одним потоком.
09/03/2023: добавлена версия Kornia в файл среды, чтобы решить проблему печати Kornia. (Спасибо @natesimon!)
26/01/2023: Лицензия была изменена для облегчения запуска модели по академическим причинам. Пожалуйста, файл лицензии для точных данных.
По состоянию на 31/12/2022 имеется обновление, которое исправляет немного неправильную внутреннюю часть, увеличение флиппа для объема стоимости и численная точная ошибка в проекции. Все результаты улучшаются. Вам нужно будет обновить вилки и использовать новые веса. Смотрите исправления ошибок.
Предварительное сканирование для онлайн-кадров по умолчанию здесь: https://drive.google.com/drive/folders/1desofi9gayyhqjsx4i_ng0-3ebcafwxjv?usp=share_link
SimpleerEcon принимает входные изображения RGB и выводит карту глубины для целевого изображения.
Предполагая свежее распределение Anaconda, вы можете установить зависимости с:
conda env create -f simplerecon_env.ymlМы провели наши эксперименты с Pytorch 1.10, CUDA 11.3, Python 3.9.7 и Debian GNU/Linux 10.
Загрузите предварительную модель в weights/ папку.
Мы предоставляем следующие модели (оценки с ключами онлайн -по умолчанию):
--config | Модель | ABS Diff ↓ | SQ Rel ↓ | Дельта <1,05 ↑ | Шапка ↓ | F-Score ↑ |
|---|---|---|---|---|---|---|
hero_model.yaml | Метаданные + Resnet Matching | 0,0868 | 0,0127 | 74,26 | 5.69 | 0,680 |
dot_product_model.yaml | Dot Product + Resnet Matching | 0,0910 | 0,0134 | 71.90 | 5.92 | 0,667 |
hero_model - это тот, который мы используем в газете как нашу
--config | Модель | Скорость вывода ( --batch_size 1 ) | ВЫНТУРЕНИЕ ГПУ память | Приблизительное время обучения |
|---|---|---|---|---|
hero_model | Герой, метаданные + resnet | 130 мс / 70 мс (скорость оптимизирована) | 2,6 ГБ / 5,7 ГБ (скорость оптимизирована) | 36 часов |
dot_product_model | Точечный продукт + resnet | 80 мс | 2,6 ГБ | 36 часов |
С большими партиями скорость значительно увеличивается. С размером партии 8 на не скоростной оптимизированной модели задержка падает до ~ 40 мс.
datasets/arkit_dataset.py . ОБНОВЛЕНИЕ: теперь существует быстрое чтение data_scripts/ios_logger_arkit_readme.md для того, как обрабатывать и запустить вывод IOS-logger, используя скрипт по адресу data_scripts/ios_logger_preprocessing.py . Теперь мы включили два сканирования, чтобы люди могли немедленно попробовать с кодом. Вы можете скачать эти сканирования отсюда.
Шаги:
hero_model в каталог веса.dataset_path в configs/data/vdr_dense.yaml на базовый путь рассеченной папки VDR.CUDA_VISIBLE_DEVICES=0 python test.py --name HERO_MODEL
--output_base_path OUTPUT_PATH
--config_file configs/models/hero_model.yaml
--load_weights_from_checkpoint weights/hero_model.ckpt
--data_config configs/data/vdr_dense.yaml
--num_workers 8
--batch_size 2
--fast_cost_volume
--run_fusion
--depth_fuser open3d
--fuse_color
--dump_depth_visualization ; Это будет выходить из сетки, быстрая глубина, и Socres, когда он будет сравнять на глубину лидара под OUTPUT_PATH .
Эта команда использует vdr_dense.yaml , которая будет генерировать глубины для каждого кадра и объединить их в сетку. В документе мы сообщаем о баллах с плавными ключами, и вы можете запустить их с помощью vdr_default.yaml . Вы также можете использовать кортежи dense_offline , вместо этого используя vdr_dense_offline.yaml .
См. Раздел ниже о тестировании и оценке. Обязательно используйте правильные флаги конфигурации для наборов данных.
Пожалуйста, следуйте инструкциям здесь, чтобы загрузить набор данных. Этот набор данных довольно большой (> 2 ТБ), поэтому убедитесь, что у вас достаточно места, особенно для извлечения файлов.
После загрузки используйте этот скрипт для экспорта необработанных данных датчика в изображения и файлы глубины.
Мы написали быстрое руководство и включили модифицированные сценарии, чтобы помочь вам с загрузкой и извлечением Scannetv2. Вы можете найти их по адресу data_scripts/scannet_wrangling_scripts/
Вы должны изменить аргумент конфигурации dataset_path для конфигураций данных scannetv2 AT configs/data/ чтобы соответствовать тому, где находится ваш набор данных.
Кодовая база ожидает, что scannetv2 будет в следующем формате:
dataset_path
scans_test (test scans)
scene0707
scene0707_00_vh_clean_2.ply (gt mesh)
sensor_data
frame-000261.pose.txt
frame-000261.color.jpg
frame-000261.color.512.png (optional, image at 512x384)
frame-000261.color.640.png (optional, image at 640x480)
frame-000261.depth.png (full res depth, stored scale *1000)
frame-000261.depth.256.png (optional, depth at 256x192 also
scaled)
scene0707.txt (scan metadata and image sizes)
intrinsic
intrinsic_depth.txt
intrinsic_color.txt
...
scans (val and train scans)
scene0000_00
(see above)
scene0000_01
....
В этом примере scene0707.txt должен содержать метаданные сканирования:
colorHeight = 968
colorToDepthExtrinsics = 0.999263 -0.010031 0.037048 ........
colorWidth = 1296
depthHeight = 480
depthWidth = 640
fx_color = 1170.187988
fx_depth = 570.924255
fy_color = 1170.187988
fy_depth = 570.924316
mx_color = 647.750000
mx_depth = 319.500000
my_color = 483.750000
my_depth = 239.500000
numColorFrames = 784
numDepthFrames = 784
numIMUmeasurements = 1632
frame-000261.pose.txt должен содержать позу в форме:
-0.384739 0.271466 -0.882203 4.98152
0.921157 0.0521417 -0.385682 1.46821
-0.0587002 -0.961035 -0.270124 1.51837
frame-000261.color.512.png и frame-000261.color.640.png -это предварительные версии исходного изображения, чтобы сохранить нагрузку и вычислять время во время обучения и тестирования. frame-000261.depth.256.png также является предварительной измененной версией карты глубины.
Все измененные в соответствующих версиях глубины и изображений приятно иметь, но не требуются. Если они не существуют, версии полного разрешения будут загружены, а на лету - на лету.
По умолчанию мы оцениваем карту глубины для каждого ключа в сканировании. Мы используем эвристику DeepVideomVS для разделения ключевых кафедров и строим кортежи, чтобы соответствовать. Мы используем карты глубины на этих ключевых кадрах для слияния глубины. Для каждого ключа мы связываем список исходных кадров, которые будут использоваться для составления объема стоимости. Мы также используем плотные кортежи, где мы предсказываем карту глубины для каждого кадра в данных, а не только на определенных ключевых кадрах; Они в основном используются для визуализации.
Мы генерируем и экспортируем список кортежей на всех сканированиях, которые действуют как элементы набора данных. Мы предварительно рассчитывали эти списки, и они доступны в data_splits под разделением каждого набора данных. Для тестовых сканирований Scannet они находятся в data_splits/ScanNetv2/standard_split . Наши цифры глубины ядра вычисляются с использованием data_splits/ScanNetv2/standard_split/test_eight_view_deepvmvs.txt .
Вот быстрое таксон типа кортежей для тестирования:
default : кортеж для каждого ключа после DeepVideomV, где все рамки исходных рам в прошлом. Используется для всей глубины и сетки, если не указано иное. Для SCANNET используйте data_splits/ScanNetv2/standard_split/test_eight_view_deepvmvs.txt .offline : кортеж на каждый кадр в сканировании, где рамы исходных источников могут быть как в прошлом, так и в будущем по сравнению с текущим кадром. Они полезны, когда сцена запечатлена в автономном режиме, и вам нужна лучшая точность. С помощью онлайн -кортежей объем стоимости будет содержать пустые регионы, когда камера уходит, и все рамы исходных рам отстают; Однако при автономных кортежах объем стоимости заполнен на обоих концах, что приводит к лучшей оценке масштаба (и метрической).dense : онлайн -кортеж (например, по умолчанию) для каждого кадра в сканировании, где все рамки исходных рам в прошлом. Для Scannet это будет data_splits/ScanNetv2/standard_split/test_eight_view_deepvmvs_dense.txt .offline : автономный кортеж для каждого ключа для каждого ключа в сканировании.Для наборов поезда и валидации мы следуем той же стратегии увеличения кортежей, что и в DeepVideomV, и используем один и тот же скрипт генерации основного поколения.
Если вы хотите создать эти кортежи самостоятельно, вы можете использовать сценарии по адресу data_scripts/generate_train_tuples.py для кортежей поезда и data_scripts/generate_test_tuples.py для тестовых кортежей. Они следуют тому же формату конфигурации, что и test.py , и будут использовать любой класс наборов данных, который вы создаете для чтения Pose Informaiton.
Пример для теста:
# default tuples
python ./data_scripts/generate_test_tuples.py
--data_config configs/data/scannet_default_test.yaml
--num_workers 16
# dense tuples
python ./data_scripts/generate_test_tuples.py
--data_config configs/data/scannet_dense_test.yaml
--num_workers 16Примеры для поезда:
# train
python ./data_scripts/generate_train_tuples.py
--data_config configs/data/scannet_default_train.yaml
--num_workers 16
# val
python ./data_scripts/generate_val_tuples.py
--data_config configs/data/scannet_default_val.yaml
--num_workers 16 Эти сценарии сначала будут проверять каждый кадр в наборе данных, чтобы убедиться, что он имеет существующий RGB -кадр, существующий кадр глубины (если это необходимо для набора данных), а также существующий и допустимый файл POSE. Он сохранит эти valid_frames в текстовом файле в папке каждого сканирования, но если каталог будет считан только, он будет игнорировать сохранение файла valid_frames и в любом случае генерировать кортежи.
Вы можете использовать test.py для определения и оценки карт глубины и сетки слияния.
Все результаты будут храниться в базовой папке результатов (Results_path) по адресу:
opts.output_base_path/opts.name/opts.dataset/opts.frame_tuple_type/
где выбор - класс options . HERO_MODEL opts.name opts.dataset opts.output_base_path ./results scannet opts.frame_tuple_type default
./results/HERO_MODEL/scannet/default/
Обязательно установите --opts.output_base_path в каталог, подходящий для вас, чтобы сохранить результаты.
--frame_tuple_type -это тип кортежа изображения, используемого для MVS. Выбор должен быть представлен в используемом вами файле data_config .
По умолчанию test.py попытается вычислить показатели глубины для каждого кадра и обеспечить как усредненные кадры, так и усредненные показатели сцены. Сценарий сохранит эти оценки (по сцене и итогов) в соответствии с results_path/scores .
Мы сделали все возможное, чтобы гарантировать, что ошибка с факелой через соответствующий энкодер был зафиксирован для (<10^-4) точного тестирования путем отключения отображения изображений через этот кодер. Run --batch_size 4 максимум, если вы сомневаетесь, и если вы хотите получить максимально стабильные числа и избежать Gremlins Pytorch, используйте --batch_size 1 для сравнения оценки.
Если вы хотите использовать это для скорости, установите --fast_cost_volume в true. Это позволит пройти через соответствующий энкодер и позволит оптимизированному объему функции Einops.
# Example command to just compute scores
CUDA_VISIBLE_DEVICES=0 python test.py --name HERO_MODEL
--output_base_path OUTPUT_PATH
--config_file configs/models/hero_model.yaml
--load_weights_from_checkpoint weights/hero_model.ckpt
--data_config configs/data/scannet_default_test.yaml
--num_workers 8
--batch_size 4 ;
# If you'd like to get a super fast version use:
CUDA_VISIBLE_DEVICES=0 python test.py --name HERO_MODEL
--output_base_path OUTPUT_PATH
--config_file configs/models/hero_model.yaml
--load_weights_from_checkpoint weights/hero_model.ckpt
--data_config configs/data/scannet_default_test.yaml
--num_workers 8
--fast_cost_volume
--batch_size 2 ;Этот сценарий также может быть использован для выполнения нескольких различных вспомогательных задач, включая:
TSDF Fusion
Чтобы запустить TSDF Fusion, предоставьте флаг --run_fusion . У вас есть два варианта для фьюзеров
--depth_fuser ours (по умолчанию) будет использовать наш Fuser, чьи сетки используются в большинстве визуализаций и для оценки. Этот фьюзер не поддерживает цвет. Мы предоставили пользовательскую филиал Scikit-Image с нашей пользовательской реализацией measure.matching_cubes , которая позволяет одностренную стену. Мы используем одностенные сетки для оценки. Если это не важно для вас, вы можете установить export_single_mesh на False для вызова export_mesh в test.py--depth_fuser open3d будет использовать Fuser Deby Deby Open3D. Этот фьюзер поддерживает цвет, и вы можете включить это, используя флаг --fuse_color . По умолчанию, карты глубины будут обрезаны до 3 м для слияния, и будет использоваться разрешение TSDF 0,04M 3 , но вы можете изменить это, изменив оба --max_fusion_depth и --fusion_resolution
Вы можете опционально попросить предсказанные глубины, используемые для маскировки, когда не существует информации о VAIID MVS с использованием --mask_pred_depths . Это не включено по умолчанию.
Вы также можете объединить лучшие глубины догадки от объема стоимости до того, как энкодер объема стоимости вносит сильное изображение предыдущим. Вы можете сделать это, используя --fusion_use_raw_lowest_cost .
Сетки будут храниться в рамках results_path/meshes/ .
# Example command to fuse depths to get meshes
CUDA_VISIBLE_DEVICES=0 python test.py --name HERO_MODEL
--output_base_path OUTPUT_PATH
--config_file configs/models/hero_model.yaml
--load_weights_from_checkpoint weights/hero_model.ckpt
--data_config configs/data/scannet_default_test.yaml
--num_workers 8
--run_fusion
--batch_size 8 ;Кэш глубины
Вы можете при условии, чтобы сохранить глубину, предоставив флаг --cache_depths . Они будут храниться в results_path/depths .
# Example command to compute scores and cache depths
CUDA_VISIBLE_DEVICES=0 python test.py --name HERO_MODEL
--output_base_path OUTPUT_PATH
--config_file configs/models/hero_model.yaml
--load_weights_from_checkpoint weights/hero_model.ckpt
--data_config configs/data/scannet_default_test.yaml
--num_workers 8
--cache_depths
--batch_size 8 ;
# Example command to fuse depths to get color meshes
CUDA_VISIBLE_DEVICES=0 python test.py --name HERO_MODEL
--output_base_path OUTPUT_PATH
--config_file configs/models/hero_model.yaml
--load_weights_from_checkpoint weights/hero_model.ckpt
--data_config configs/data/scannet_default_test.yaml
--num_workers 8
--run_fusion
--depth_fuser open3d
--fuse_color
--batch_size 4 ;Быстрый, а именно
Существуют другие сценарии для более глубоких визуализаций глубины выхода и слияния, но для быстрого экспорта визуализации глубины вы можете использовать --dump_depth_visualization . Визуализация будет сохранена в results_path/viz/quick_viz/ .
# Example command to output quick depth visualizations
CUDA_VISIBLE_DEVICES=0 python test.py --name HERO_MODEL
--output_base_path OUTPUT_PATH
--config_file configs/models/hero_model.yaml
--load_weights_from_checkpoint weights/hero_model.ckpt
--data_config configs/data/scannet_default_test.yaml
--num_workers 8
--dump_depth_visualization
--batch_size 4 ; Мы также разрешаем слияние карт глубины точечного облака, используя Fuser из 3DVNet's Repo.
# Example command to fuse depths into point clouds.
CUDA_VISIBLE_DEVICES=0 python pc_fusion.py --name HERO_MODEL
--output_base_path OUTPUT_PATH
--config_file configs/models/hero_model.yaml
--load_weights_from_checkpoint weights/hero_model.ckpt
--data_config configs/data/scannet_dense_test.yaml
--num_workers 8
--batch_size 4 ; Измените configs/data/scannet_dense_test.yaml на configs/data/scannet_default_test.yaml чтобы использовать ключевые кадры, только если вы не хотите ждать слишком долго.
Мы используем оценку сетки TransformerFusion для нашей основной таблицы результатов, но устанавливаем семена на фиксированное значение для согласованности, когда случайным образом отбирательными сетчаты. Мы также сообщаем о сетчатых показателях с использованием оценки NeuralRecon в дополнительном материале.
Для оценки облака точек мы используем код TransformerFusion, но загружаем в облаке точек вместо выборки поверхности сетки.
По умолчанию модели и файлы событий Tensorboard сохраняются в ~/tmp/tensorboard/<model_name> . Это можно изменить с помощью флага --log_dir .
Мы тренируемся с batch_size 16 с 16-битной точностью на двух A100 на расколе ScannetV2 по умолчанию.
Пример команды для тренировок с двумя графическими процессорами:
CUDA_VISIBLE_DEVICES=0,1 python train.py --name HERO_MODEL
--log_dir logs
--config_file configs/models/hero_model.yaml
--data_config configs/data/scannet_default_train.yaml
--gpus 2
--batch_size 16 ; Код поддерживает любое количество графических процессоров для обучения. Вы можете указать, какие графические процессоры использовать в среде CUDA_VISIBLE_DEVICES .
Все наши тренировочные пробежки были выполнены на двух NVIDIA A100.
Другой набор данных
Вы можете тренироваться на пользовательском наборе данных MVS, написав новый класс DataLoader, который наследует от GenericMVSDataset в datasets/generic_mvs_dataset.py . См. Класс ScannetDataset в datasets/scannet_dataset.py или действительно любой другой класс в datasets для примера.
Чтобы Finetune, просто загрузите контрольную точку (не возобновите!) И оттуда тренируйтесь:
CUDA_VISIBLE_DEVICES=0 python train.py --config configs/models/hero_model.yaml
--data_config configs/data/scannet_default_train.yaml
--load_weights_from_checkpoint weights/hero_model.ckptИзмените конфигурации данных на любой набор данных, в который вы хотите получить.
См options.py для диапазона других вариантов обучения, таких как ставки обучения и настройки абляции, а также варианты тестирования.
Помимо быстрой визуализации глубины в скрипте test.py , существует два сценария для визуализации вывода глубины.
Первым является visualization_scripts/visualize_scene_depth_output.py . Это создаст видео с цветными изображениями ссылок и исходных рам, прогнозированием глубины, оценкой объема затрат, глубиной GT и оценочными нормами от глубины. Скрипт предполагает, что у вас есть кэшированный выход с использованием test.py и принимает тот же формат шаблона команд, что и test.py :
# Example command to get visualizations for dense frames
CUDA_VISIBLE_DEVICES=0 python ./visualization_scripts/visualize_scene_depth_output.py --name HERO_MODEL
--output_base_path OUTPUT_PATH
--data_config configs/data/scannet_dense_test.yaml
--num_workers 8 ; где OUTPUT_PATH является базовым каталогом результатов для простых (то, что вы использовали для тестирования с самого начала). Вы можете запустить .visualization_scripts/generate_gt_min_max_cache.py до этого скрипта, чтобы получить среднее значение сцены для значений Min и максимальной глубины, используемых для долломирования; Если они недоступны, сценарий будет использовать 0M и 5M для Colomapping Min и Max.
Второе позволяет живой визуализации сетки. Этот скрипт будет использовать карты глубины кэширования, если он будет доступен, в противном случае он будет использовать модель для прогнозирования их до слияния. Сценарий итеративно загружается на глубинную карту, объединит его, сохраняет сетку на этом этапе и отобразит эту сетку вместе с маркером камеры для видео Birdseye и с точки зрения камеры для видео FPV.
# Example command to get live visualizations for mesh reconstruction
CUDA_VISIBLE_DEVICES=0 python visualize_live_meshing.py --name HERO_MODEL
--output_base_path OUTPUT_PATH
--config_file configs/models/hero_model.yaml
--load_weights_from_checkpoint weights/hero_model.ckpt
--data_config configs/data/scannet_dense_test.yaml
--num_workers 8 ; По умолчанию скрипт сохранит сетки в промежуточное местоположение, и вы можете при желании загрузить эти сетки, чтобы сэкономить время при снова визуализации одни и те же сетки, --use_precomputed_partial_meshes Все промежуточные сетки должны были быть рассчитаны по предыдущему пробегу для работы.
Tl; dr: world_T_cam == world_from_cam
В этом репо используется нотация "cam_t_world" для обозначения преобразования из точек мира в камеру (внешняя). Намерение состоит в том, чтобы сделать так, чтобы имена кадров координат соответствовали по обе стороны от переменной при использовании при умножении справа налево :
cam_points = cam_T_world @ world_points
world_T_cam обозначает позу камеры (от CAM к мировым координаторам). ref_T_src обозначает преобразование из источника в эталонный представление.
Наконец, эта нотация позволяет представлять как ротации, так и переводы, такие как: world_R_cam и world_t_cam
Этот репо ориентирован на сканет, поэтому, хотя его функциональность должна разрешать любую систему координат (сигнализированные через входные флаги), веса модели, которые мы предоставляем, предполагают систему координат сканета. Это важно, поскольку мы включаем информацию о лучах как часть метаданных. Другие наборы данных, используемые с этими весами, должны быть преобразованы в систему сканета. Классы набора данных, которые мы включаем, будут выполнять соответствующие преобразования.
В этом обновлении адресовано несколько ошибок, вам нужно будет обновить свои вилки и использовать новые веса из таблицы в начале этого чтения. Вам также необходимо убедиться, что у вас есть правильные файлы внутренней системы, извлеченные с помощью читателя.
Благодаря всем, кто указал на это и был терпелив, пока мы работали над исправлениями.
Все результаты улучшаются с этими исправлениями, и связанные веса загружаются здесь. Для старых результатов, кода и веса проверьте этот коммит hash: 7de5b451e340f9a11c7fd67bd0c42204d0b009a9
Полные результаты для моделей с исправлениями ошибок:
Глубина
--config | ABS Diff ↓ | ABS rel ↓ | SQ Rel ↓ | RMSE ↓ | log rmse ↓ | Дельта <1,05 ↑ | Дельта <1,10 ↑ |
|---|---|---|---|---|---|---|---|
hero_model.yaml , метаданные + resnet | 0,0868 | 0,0428 | 0,0127 | 0,1472 | 0,0681 | 74,26 | 90.88 |
dot_product_model.yaml , точечный продукт + resnet | 0,0910 | 0,0453 | 0,0134 | 0,1509 | 0,0704 | 71.90 | 89,75 |
Сетчатое слияние
--config | ACC ↓ | Comp ↓ | Шапка ↓ | Вспомните ↑ | Точность ↑ | F-Score ↑ |
|---|---|---|---|---|---|---|
hero_model.yaml , метаданные + resnet | 5.41 | 5.98 | 5.69 | 0,695 | 0,668 | 0,680 |
dot_product_model.yaml , точечный продукт + resnet | 5.66 | 6.18 | 5.92 | 0,682 | 0,655 | 0,667 |
Сравнение:
--config | Модель | ABS Diff ↓ | SQ Rel ↓ | Дельта <1,05 ↑ | Шапка ↓ | F-Score ↑ |
|---|---|---|---|---|---|---|
hero_model.yaml | Метаданные + Resnet Matching | 0,0868 | 0,0127 | 74,26 | 5.69 | 0,680 |
Old hero_model.yaml | Метаданные + Resnet Matching | 0,0885 | 0,0125 | 73.16 | 5.81 | 0,671 |
dot_product_model.yaml | Dot Product + Resnet Matching | 0,0910 | 0,0134 | 71.90 | 5.92 | 0,667 |
Old dot_product_model.yaml | Dot Product + Resnet Matching | 0,0941 | 0,0139 | 70.48 | 6.29 | 0,642 |
Первоначально этот репо распределяет файлы кортежей для ключевых кадров стиля DVMVS по умолчанию с 9 дополнительным кадром 25599 для тестового набора ScannetV2. Была незначительная ошибка с обработкой потерянного отслеживания, которая сейчас исправлена. Этот репо должен теперь имитировать буфер ключа ключа DVMVS, с 25590 ключами для тестирования. Единственный эффект, который имел у этой ошибки, было включение 9 дополнительных кадров, все остальные кортежи были точно такими же, как и у DVMV. Рамовые рамы в этих сканировании
scan previous count new count
--------------------------------------
scene0711_00 393 392
scene0727_00 209 208
scene0736_00 1023 1022
scene0737_00 408 407
scene0751_00 165 164
scene0775_00 220 219
scene0791_00 227 226
scene0794_00 141 140
scene0795_00 102 101
Файлы кортежа для теста по умолчанию были обновлены. Поскольку это небольшая (~ 3E-4) разница в дополнительных кадрах, оценки не изменились.
TL; DR: масштабируйте ваши позы и обновите ваши изображения.
Мы предоставляем DataLoader для загрузки изображений из разреженной реконструкции COLMAP. Чтобы это работало с SimpleerEcon, вам нужно будет обрезать ваши изображения, чтобы соответствовать FOV Scannet (примерно похожи на FOV iPhone в режиме видео) и масштабировать местоположение вашей позы с использованием известных измерений реального мира. Если эти шаги не будут предприняты, объем стоимости не будет построен правильно, и сеть не будет должным образом оценить глубину.
Мы благодарим Альжаж Божич из Transformerfusion, Jiaming Sun of Neural Recon и Arda Düzçeker из DeepVideomvs за быстрое предоставление полезной информации, чтобы помочь с базовыми показателями и за то, что они легко доступны, особенно в короткие сроки.
Сценарии генерации корзин используют модифицированную версию буфера ключа DeepVideomvs (еще раз спасибо Arda и Co!).
Модуль слияния Pytorch Point Cloud в коде torch_point_cloud_fusion заимствован из репо 3DVNET. Спасибо, Александр Рич!
Мы также хотели бы поблагодарить команду инфраструктуры Niantic за быстрые действия, когда мы нуждаемся в них. Спасибо, ребята!
Мохамед финансируется стипендией Microsoft Research PhD (MRL 2018-085).
Если вы найдете нашу работу полезной в своем исследовании, пожалуйста, рассмотрите возможность ссылаться на нашу статью:
@inproceedings{sayed2022simplerecon,
title={SimpleRecon: 3D Reconstruction Without 3D Convolutions},
author={Sayed, Mohamed and Gibson, John and Watson, Jamie and Prisacariu, Victor and Firman, Michael and Godard, Cl{'e}ment},
booktitle={Proceedings of the European Conference on Computer Vision (ECCV)},
year={2022},
}
Copyright © Niantic, Inc. 2022. Патент ожидает. Все права защищены. Пожалуйста, смотрите файл лицензии для условий.


