simplerecon
1.0.0
นี่คือการอ้างอิง Pytorch อ้างอิงสำหรับการฝึกอบรมและการทดสอบแบบจำลองการประมาณความลึก MVS โดยใช้วิธีการที่อธิบายไว้ใน
Simplerecon: การสร้าง 3D โดยไม่มี convolutions 3D
Mohamed Sayed, John Gibson, Jamie Watson, Victor Adrian Prisacariu, Michael Firman และClément Godard
กระดาษ, ECCV 2022 (ARXIV PDF), วัสดุเสริม, หน้าโครงการ, วิดีโอ
รหัสนี้มีไว้สำหรับการใช้งานที่ไม่ใช่เชิงพาณิชย์ โปรดดูไฟล์ใบอนุญาตสำหรับข้อกำหนด หากคุณพบว่าส่วนใดส่วนหนึ่งของ codebase นี้มีประโยชน์โปรดอ้างอิงกระดาษของเราโดยใช้ bibtex ด้านล่างและเชื่อมโยง repo นี้ ขอบคุณ!
25/05/2023: การแก้ไขแพ็คเกจคงที่สำหรับ llvm-openmp , clang และ protobuf ใช้ไฟล์สภาพแวดล้อมใหม่นี้หากคุณมีปัญหาในการเรียกใช้รหัสและ/หรือหาก DataLoading ถูก จำกัด ไว้ที่เธรดเดียว
09/03/2023: เพิ่มเวอร์ชัน Kornia ลงในไฟล์ Environments เพื่อแก้ไขปัญหาการพิมพ์ Kornia (ขอบคุณ @Natesimon!)
26/01/2023: ใบอนุญาตได้รับการแก้ไขเพื่อให้การใช้งานแบบจำลองด้วยเหตุผลทางวิชาการง่ายขึ้น กรุณาไฟล์ใบอนุญาตสำหรับรายละเอียดที่แน่นอน
มีการอัปเดต ณ วันที่ 31/12/2022 ที่แก้ไขความผิดพลาดเล็กน้อยการเพิ่มการพลิกสำหรับปริมาณต้นทุนและข้อผิดพลาดเชิงตัวเลขในการฉาย คะแนนทั้งหมดดีขึ้น คุณจะต้องอัปเดตส้อมและใช้น้ำหนักใหม่ ดูการแก้ไขข้อผิดพลาด
สแกนที่คำนวณล่วงหน้าสำหรับเฟรมเริ่มต้นออนไลน์อยู่ที่นี่: https://drive.google.com/drive/folders/1dsofi9gayyhqjsx4i_ng0-3ebcafwxjv?usp=share_link
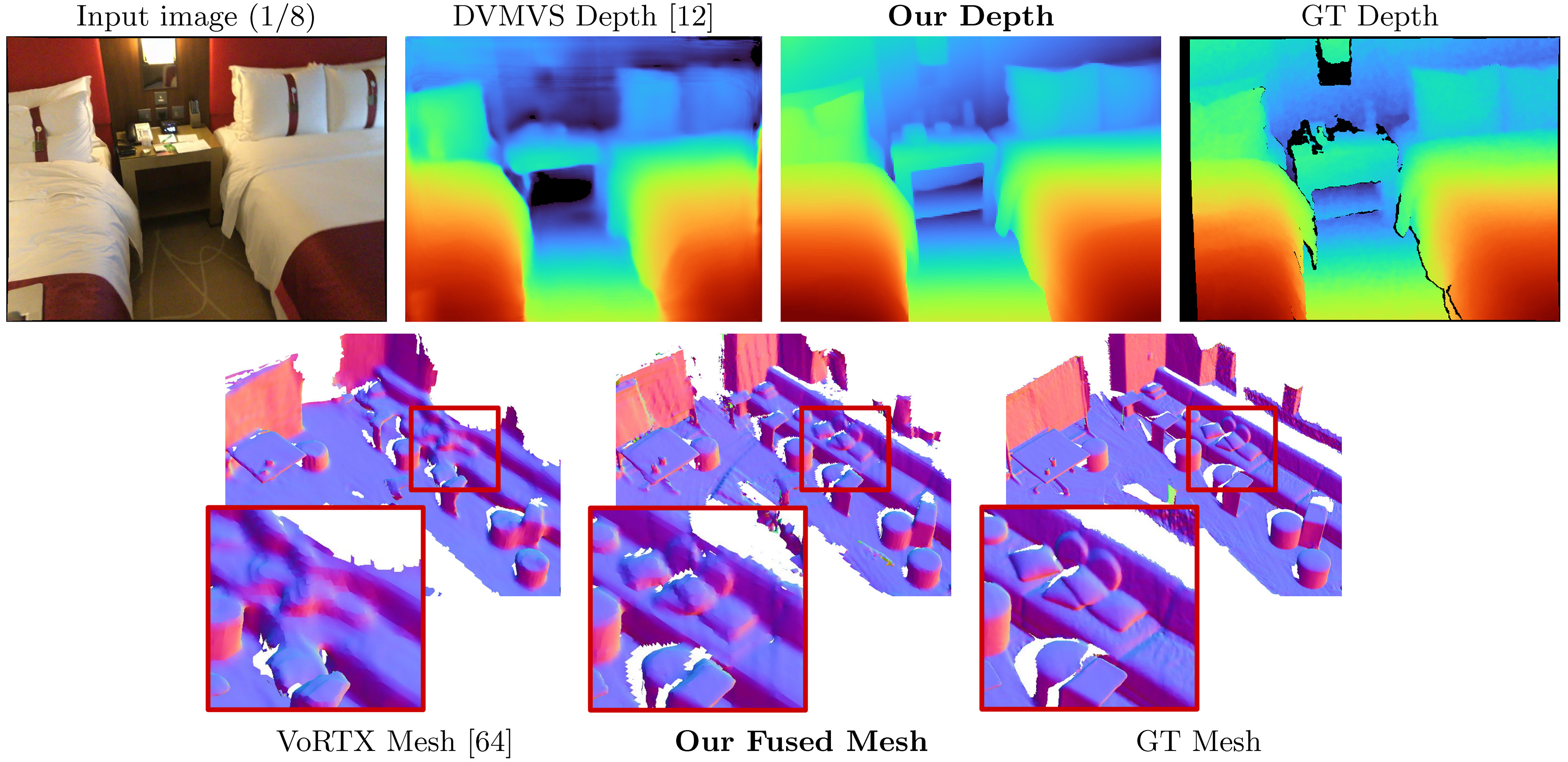
Simplerecon ใช้เป็นอินพุตที่วางรูปภาพ RGB และส่งออกแผนที่ความลึกสำหรับภาพเป้าหมาย
สมมติว่ามีการกระจาย Anaconda ใหม่คุณสามารถติดตั้งการพึ่งพาได้ด้วย:
conda env create -f simplerecon_env.ymlเราทำการทดลองของเราด้วย Pytorch 1.10, Cuda 11.3, Python 3.9.7 และ Debian GNU/Linux 10
ดาวน์โหลดโมเดลที่ผ่านการฝึกฝนไว้ใน weights/ โฟลเดอร์
เรามีรุ่นต่อไปนี้ (คะแนนอยู่กับคีย์เฟรมเริ่มต้นออนไลน์):
--config | แบบอย่าง | abs diff ↓ | sq rel ↓ | เดลต้า <1.05 ↑ | ลบล้าง↓ | F-score ↑ |
|---|---|---|---|---|---|---|
hero_model.yaml | การจับคู่ข้อมูลเมตา + resnet | 0.0868 | 0.0127 | 74.26 | 5.69 | 0.680 |
dot_product_model.yaml | การจับคู่ผลิตภัณฑ์ DOT + resnet | 0.0910 | 0.0134 | 71.90 | 5.92 | 0.667 |
hero_model เป็นสิ่งที่เราใช้ในกระดาษเป็น ของเรา
--config | แบบอย่าง | ความเร็วการอนุมาน ( --batch_size 1 ) | การอนุมาน GPU หน่วยความจำ | เวลาฝึกอบรมโดยประมาณ |
|---|---|---|---|---|
hero_model | ฮีโร่, ข้อมูลเมตา + resnet | 130ms / 70ms (เพิ่มความเร็ว) | 2.6GB / 5.7GB (เพิ่มประสิทธิภาพความเร็ว) | 36 ชั่วโมง |
dot_product_model | dot product + resnet | 80ms | 2.6GB | 36 ชั่วโมง |
ด้วยความเร็วแบทช์ที่ใหญ่ขึ้นจะเพิ่มขึ้นอย่างมาก ด้วยขนาดแบทช์ 8 ในโมเดลที่ไม่ได้รับการปรับปรุงความเร็วเวลาแฝงจะลดลงเหลือ ~ 40ms
datasets/arkit_dataset.py อัปเดต: ขณะนี้มี readme data_scripts/ios_logger_arkit_readme.md อย่างรวดเร็วสำหรับวิธีการประมวลผลและเรียกใช้การสแกน iOS-logger โดยใช้สคริปต์ที่ data_scripts/ios_logger_preprocessing.py ตอนนี้เราได้รวมการสแกนสองครั้งเพื่อให้ผู้คนลองใช้รหัสทันที คุณสามารถดาวน์โหลดการสแกนเหล่านี้ได้จากที่นี่
ขั้นตอน:
hero_model ลงในไดเรกทอรีน้ำหนักdataset_path ใน configs/data/vdr_dense.yaml ไปยังเส้นทางพื้นฐานของโฟลเดอร์ VDR ที่คลายซิปCUDA_VISIBLE_DEVICES=0 python test.py --name HERO_MODEL
--output_base_path OUTPUT_PATH
--config_file configs/models/hero_model.yaml
--load_weights_from_checkpoint weights/hero_model.ckpt
--data_config configs/data/vdr_dense.yaml
--num_workers 8
--batch_size 2
--fast_cost_volume
--run_fusion
--depth_fuser open3d
--fuse_color
--dump_depth_visualization ; สิ่งนี้จะส่งออกตาข่ายความลึกอย่างรวดเร็วและ Socres เมื่อเปรียบเทียบกับความลึกของ LIDAR ภายใต้ OUTPUT_PATH
คำสั่งนี้ใช้ vdr_dense.yaml ซึ่งจะสร้างความลึกสำหรับทุกเฟรมและหลอมรวมลงในตาข่าย ในกระดาษเรารายงานคะแนนด้วย keyframes ที่หลอมรวมแทนและคุณสามารถเรียกใช้งานโดยใช้ vdr_default.yaml คุณยังสามารถใช้ tuples dense_offline โดยใช้ vdr_dense_offline.yaml แทน
ดูส่วนด้านล่างเกี่ยวกับการทดสอบและการประเมินผล ตรวจสอบให้แน่ใจว่าใช้ธงกำหนดค่าที่ถูกต้องสำหรับชุดข้อมูล
โปรดทำตามคำแนะนำที่นี่เพื่อดาวน์โหลดชุดข้อมูล ชุดข้อมูลนี้ค่อนข้างใหญ่ (> 2TB) ดังนั้นให้แน่ใจว่าคุณมีพื้นที่เพียงพอโดยเฉพาะอย่างยิ่งสำหรับการแยกไฟล์
เมื่อดาวน์โหลดแล้วให้ใช้สคริปต์นี้เพื่อส่งออกข้อมูลเซ็นเซอร์ดิบไปยังรูปภาพและไฟล์ความลึก
เราได้เขียนบทแนะนำอย่างรวดเร็วและรวมสคริปต์ที่ได้รับการแก้ไขเพื่อช่วยคุณในการดาวน์โหลดและแยก Scannetv2 คุณสามารถค้นหาได้ที่ data_scripts/scannet_wrangling_scripts/
คุณควรเปลี่ยนอาร์กิวเมนต์ dataset_path config สำหรับ scannetv2 data configs ที่ configs/data/ เพื่อให้ตรงกับตำแหน่งที่ชุดข้อมูลของคุณอยู่
Codebase คาดว่า Scannetv2 จะอยู่ในรูปแบบต่อไปนี้:
dataset_path
scans_test (test scans)
scene0707
scene0707_00_vh_clean_2.ply (gt mesh)
sensor_data
frame-000261.pose.txt
frame-000261.color.jpg
frame-000261.color.512.png (optional, image at 512x384)
frame-000261.color.640.png (optional, image at 640x480)
frame-000261.depth.png (full res depth, stored scale *1000)
frame-000261.depth.256.png (optional, depth at 256x192 also
scaled)
scene0707.txt (scan metadata and image sizes)
intrinsic
intrinsic_depth.txt
intrinsic_color.txt
...
scans (val and train scans)
scene0000_00
(see above)
scene0000_01
....
ในตัวอย่างนี้ scene0707.txt ควรมีข้อมูลเมตาของการสแกน:
colorHeight = 968
colorToDepthExtrinsics = 0.999263 -0.010031 0.037048 ........
colorWidth = 1296
depthHeight = 480
depthWidth = 640
fx_color = 1170.187988
fx_depth = 570.924255
fy_color = 1170.187988
fy_depth = 570.924316
mx_color = 647.750000
mx_depth = 319.500000
my_color = 483.750000
my_depth = 239.500000
numColorFrames = 784
numDepthFrames = 784
numIMUmeasurements = 1632
frame-000261.pose.txt ควรมีท่าทางในรูปแบบ:
-0.384739 0.271466 -0.882203 4.98152
0.921157 0.0521417 -0.385682 1.46821
-0.0587002 -0.961035 -0.270124 1.51837
frame-000261.color.512.png และ frame-000261.color.640.png เป็นเวอร์ชันที่มีขนาดเล็กของภาพต้นฉบับเพื่อประหยัดโหลดและคำนวณเวลาในระหว่างการฝึกอบรมและการทดสอบ frame-000261.depth.256.png ยังเป็นรุ่นที่มีขนาดขนาดปรับขนาดของแผนที่ความลึก
ความลึกและรูปภาพที่ปรับขนาดได้ทั้งหมดและรูปภาพนั้นดี แต่ไม่จำเป็น หากไม่มีอยู่จริงเวอร์ชันความละเอียดเต็มจะถูกโหลดและลดลงทันที
โดยค่าเริ่มต้นเราประเมินแผนที่ความลึกสำหรับแต่ละเฟรมในการสแกน เราใช้ฮิวริสติกของ DeepVideomvs สำหรับการแยกคีย์เฟรมและสร้าง tuples ให้เข้ากัน เราใช้แผนที่ความลึกที่คีย์เฟรมเหล่านี้เพื่อการหลอมรวมความลึก สำหรับแต่ละคีย์เฟรมเราเชื่อมโยงรายการเฟรมต้นทางที่จะใช้ในการสร้างปริมาณต้นทุน นอกจากนี้เรายังใช้ tuples หนาแน่นซึ่งเราทำนายแผนที่ความลึกสำหรับแต่ละเฟรมในข้อมูลและไม่เพียงแค่ที่คีย์เฟรมเฉพาะ สิ่งเหล่านี้ส่วนใหญ่ใช้สำหรับการสร้างภาพข้อมูล
เราสร้างและส่งออกรายการ tuples ในการสแกนทั้งหมดที่ทำหน้าที่เป็นองค์ประกอบของชุดข้อมูล เราได้คำนวณรายการเหล่านี้ล่วงหน้าและมีอยู่ที่ data_splits ภายใต้การแยกของแต่ละชุด สำหรับการสแกนทดสอบของ Scannet พวกเขาอยู่ที่ data_splits/ScanNetv2/standard_split ตัวเลขความลึกหลักของเราถูกคำนวณโดยใช้ data_splits/ScanNetv2/standard_split/test_eight_view_deepvmvs.txt
นี่คือ taxonamy อย่างรวดเร็วของประเภทของ tuples สำหรับการทดสอบ:
default : tuple สำหรับ keyframe ทุกตัวต่อไปนี้ DeepVideomvs ที่เฟรมต้นทางทั้งหมดอยู่ในอดีต ใช้สำหรับการประเมินความลึกและตาข่ายทั้งหมดเว้นแต่จะระบุไว้เป็นอย่างอื่น สำหรับ Scannet ใช้ data_splits/ScanNetv2/standard_split/test_eight_view_deepvmvs.txtoffline : tuple สำหรับทุกเฟรมในการสแกนที่เฟรมต้นทางสามารถเป็นได้ทั้งในอดีตและอนาคตเมื่อเทียบกับเฟรมปัจจุบัน สิ่งเหล่านี้มีประโยชน์เมื่อฉากถูกจับแบบออฟไลน์และคุณต้องการความแม่นยำที่ดีที่สุดเท่าที่จะเป็นไปได้ ด้วย tuples ออนไลน์ปริมาณค่าใช้จ่ายจะมีภูมิภาคที่ว่างเปล่าเมื่อกล้องเคลื่อนตัวออกไปและเฟรมต้นทางทั้งหมดล่าช้า อย่างไรก็ตามด้วย tuples ออฟไลน์ปริมาณค่าใช้จ่ายเต็มทั้งสองด้านนำไปสู่การประมาณการที่ดีขึ้น (และเมตริก)dense : tuple ออนไลน์ (เช่นค่าเริ่มต้น) สำหรับทุกเฟรมในการสแกนที่เฟรมแหล่งที่มาทั้งหมดอยู่ในอดีต สำหรับ Scannet นี่จะเป็น data_splits/ScanNetv2/standard_split/test_eight_view_deepvmvs_dense.txtoffline : tuple ออฟไลน์สำหรับ Keyframe สำหรับทุก ๆ คีย์เฟรมในการสแกนสำหรับชุดรถไฟและการตรวจสอบความถูกต้องเราทำตามกลยุทธ์การเพิ่ม tuple เช่นเดียวกับใน DeepVideomvs และใช้สคริปต์การสร้างหลักเดียวกัน
หากคุณต้องการสร้างสิ่งเหล่านี้ด้วยตัวคุณเองคุณสามารถใช้สคริปต์ที่ data_scripts/generate_train_tuples.py สำหรับ tuples รถไฟและ data_scripts/generate_test_tuples.py สำหรับการทดสอบ tuples สิ่งเหล่านี้เป็นไปตามรูปแบบการกำหนดค่าเดียวกันกับ test.py และจะใช้คลาสชุดข้อมูลที่คุณสร้างเพื่ออ่าน Pose Informaiton
ตัวอย่างสำหรับการทดสอบ:
# default tuples
python ./data_scripts/generate_test_tuples.py
--data_config configs/data/scannet_default_test.yaml
--num_workers 16
# dense tuples
python ./data_scripts/generate_test_tuples.py
--data_config configs/data/scannet_dense_test.yaml
--num_workers 16ตัวอย่างสำหรับรถไฟ:
# train
python ./data_scripts/generate_train_tuples.py
--data_config configs/data/scannet_default_train.yaml
--num_workers 16
# val
python ./data_scripts/generate_val_tuples.py
--data_config configs/data/scannet_default_val.yaml
--num_workers 16 สคริปต์เหล่านี้จะตรวจสอบแต่ละเฟรมก่อนในชุดข้อมูลเพื่อให้แน่ใจว่ามีเฟรม RGB ที่มีอยู่เฟรมความลึกที่มีอยู่ (หากเหมาะสมสำหรับชุดข้อมูล) และไฟล์โพสท่าที่มีอยู่และถูกต้อง มันจะบันทึก valid_frames เหล่านี้ในไฟล์ข้อความในโฟลเดอร์ของสแกนแต่ละโฟลเดอร์ แต่ถ้าไดเรกทอรีถูกอ่านเท่านั้นมันจะไม่สนใจการบันทึกไฟล์ valid_frames และสร้าง tuples ต่อไป
คุณสามารถใช้ test.py สำหรับการอนุมานและประเมินแผนที่ความลึกและการหลอมรวมตาข่าย
ผลลัพธ์ทั้งหมดจะถูกเก็บไว้ที่โฟลเดอร์ผลลัพธ์พื้นฐาน (Results_Path) ที่:
opts.output_base_path/opts.name/opts.dataset/opts.frame_tuple_type/
โดยที่ OPTS คือคลาส options ตัวอย่างเช่นเมื่อ opts.output_base_path คือ ./results , opts.name คือ HERO_MODEL , opts.dataset คือ scannet และ opts.frame_tuple_type เป็น default ไดเรกทอรีเอาต์พุตจะเป็น
./results/HERO_MODEL/scannet/default/
ตรวจสอบให้แน่ใจว่าได้ตั้งค่า --opts.output_base_path ไปยังไดเรกทอรีที่เหมาะสมสำหรับคุณในการจัดเก็บผลลัพธ์
--frame_tuple_type เป็นประเภทของภาพที่ใช้สำหรับ MVS ควรให้การเลือกในไฟล์ data_config ที่คุณใช้
โดยเริ่มต้น test.py จะพยายามคำนวณคะแนนความลึกสำหรับแต่ละเฟรมและให้ทั้งค่าเฉลี่ยเฟรมและตัวชี้วัดเฉลี่ยของฉาก สคริปต์จะบันทึกคะแนนเหล่านี้ (ต่อฉากและผลรวม) ภายใต้ results_path/scores
เราได้ทำอย่างดีที่สุดเพื่อให้แน่ใจว่าข้อผิดพลาดในการคบเพลิงผ่านตัวเข้ารหัสที่ตรงกันได้รับการแก้ไขสำหรับการทดสอบที่แม่นยำ (<10^-4) โดยการปิดใช้งานการแบตช์ภาพผ่านตัวเข้ารหัสนั้น Run --batch_size 4 มากที่สุดหากมีข้อสงสัยและ --batch_size 1 คุณต้องการให้มีความเสถียรมากที่สุดเท่าที่จะเป็นไปได้
หากคุณต้องการใช้สิ่งนี้เพื่อความเร็วให้ตั้งค่า --fast_cost_volume เป็น TRUE สิ่งนี้จะช่วยให้การแบตช์ผ่านตัวเข้ารหัสที่ตรงกันและจะเปิดใช้งานปริมาณคุณสมบัติที่เหมาะสมของ EINOPS
# Example command to just compute scores
CUDA_VISIBLE_DEVICES=0 python test.py --name HERO_MODEL
--output_base_path OUTPUT_PATH
--config_file configs/models/hero_model.yaml
--load_weights_from_checkpoint weights/hero_model.ckpt
--data_config configs/data/scannet_default_test.yaml
--num_workers 8
--batch_size 4 ;
# If you'd like to get a super fast version use:
CUDA_VISIBLE_DEVICES=0 python test.py --name HERO_MODEL
--output_base_path OUTPUT_PATH
--config_file configs/models/hero_model.yaml
--load_weights_from_checkpoint weights/hero_model.ckpt
--data_config configs/data/scannet_default_test.yaml
--num_workers 8
--fast_cost_volume
--batch_size 2 ;สคริปต์นี้ยังสามารถใช้ในการทำงานเสริมที่แตกต่างกันสองสามอย่างรวมถึง:
TSDF ฟิวชั่น
ในการเรียกใช้ Fusion TSDF ให้ --run_fusion FLAG คุณมีสองตัวเลือกสำหรับ Fusers
--depth_fuser ours (ค่าเริ่มต้น) จะใช้ FUSER ของเราซึ่งมีการใช้ตาข่ายในการสร้างภาพข้อมูลส่วนใหญ่และสำหรับคะแนน ฟิวเซอร์นี้ไม่รองรับสี เราได้จัดทำสาขา Scikit-Image ที่กำหนดเองพร้อมกับการใช้งานที่กำหนดเองของเรา measure.matching_cubes ที่อนุญาตให้มีผนังเดี่ยว เราใช้ตาข่ายที่มีผนังเดี่ยวสำหรับการประเมินผล หากสิ่งนี้ไม่สำคัญสำหรับคุณคุณสามารถตั้งค่า export_single_mesh เป็น False สำหรับการโทรไปยัง export_mesh ใน test.py--depth_fuser open3d จะใช้ FUSER เชิงลึก Open3D Fuser นี้รองรับสีและคุณสามารถเปิดใช้งานสิ่งนี้ได้โดยใช้ --fuse_color FLAG โดยค่าเริ่มต้นแผนที่เชิงลึกจะถูกตัดเป็น 3M สำหรับฟิวชั่นและความละเอียด TSDF ที่ 0.04m 3 จะถูกนำมาใช้ แต่คุณสามารถเปลี่ยนได้โดยการเปลี่ยนทั้งสอง --max_fusion_depth และ --fusion_resolution
คุณสามารถเลือกที่จะขอความลึกที่คาดการณ์ไว้ที่ใช้สำหรับฟิวชั่นที่จะสวมหน้ากากเมื่อไม่มีข้อมูล MVS VAIID ที่ใช้ --mask_pred_depths สิ่งนี้ไม่ได้เปิดใช้งานตามค่าเริ่มต้น
นอกจากนี้คุณยังสามารถหลอมรวมความลึกที่คาดเดาได้ดีที่สุดจากปริมาณต้นทุนก่อนที่จะมีการกำหนดค่าตัวเข้ารหัสปริมาณต้นทุนที่แนะนำภาพที่แข็งแกร่งก่อน คุณสามารถทำได้โดยใช้ --fusion_use_raw_lowest_cost
ตาข่ายจะถูกเก็บไว้ภายใต้ results_path/meshes/
# Example command to fuse depths to get meshes
CUDA_VISIBLE_DEVICES=0 python test.py --name HERO_MODEL
--output_base_path OUTPUT_PATH
--config_file configs/models/hero_model.yaml
--load_weights_from_checkpoint weights/hero_model.ckpt
--data_config configs/data/scannet_default_test.yaml
--num_workers 8
--run_fusion
--batch_size 8 ;ความลึกแคช
คุณสามารถเลือกเก็บความลึกได้โดยการให้ธง --cache_depths พวกเขาจะถูกเก็บไว้ที่ results_path/depths
# Example command to compute scores and cache depths
CUDA_VISIBLE_DEVICES=0 python test.py --name HERO_MODEL
--output_base_path OUTPUT_PATH
--config_file configs/models/hero_model.yaml
--load_weights_from_checkpoint weights/hero_model.ckpt
--data_config configs/data/scannet_default_test.yaml
--num_workers 8
--cache_depths
--batch_size 8 ;
# Example command to fuse depths to get color meshes
CUDA_VISIBLE_DEVICES=0 python test.py --name HERO_MODEL
--output_base_path OUTPUT_PATH
--config_file configs/models/hero_model.yaml
--load_weights_from_checkpoint weights/hero_model.ckpt
--data_config configs/data/scannet_default_test.yaml
--num_workers 8
--run_fusion
--depth_fuser open3d
--fuse_color
--batch_size 4 ;ได้แก่ อย่างรวดเร็ว
มีสคริปต์อื่น ๆ สำหรับการสร้างภาพข้อมูลที่ลึกซึ้งยิ่งขึ้นของความลึกและฟิวชั่น แต่สำหรับการส่งออกแผนที่ความลึกอย่างรวดเร็วคุณสามารถใช้ --dump_depth_visualization การสร้างภาพข้อมูลจะถูกเก็บไว้ที่ results_path/viz/quick_viz/
# Example command to output quick depth visualizations
CUDA_VISIBLE_DEVICES=0 python test.py --name HERO_MODEL
--output_base_path OUTPUT_PATH
--config_file configs/models/hero_model.yaml
--load_weights_from_checkpoint weights/hero_model.ckpt
--data_config configs/data/scannet_default_test.yaml
--num_workers 8
--dump_depth_visualization
--batch_size 4 ; นอกจากนี้เรายังอนุญาตให้มีการหลอมรวมเมฆจุดของแผนที่ความลึกโดยใช้ฟิวเซอร์จาก repo ของ 3DVNet
# Example command to fuse depths into point clouds.
CUDA_VISIBLE_DEVICES=0 python pc_fusion.py --name HERO_MODEL
--output_base_path OUTPUT_PATH
--config_file configs/models/hero_model.yaml
--load_weights_from_checkpoint weights/hero_model.ckpt
--data_config configs/data/scannet_dense_test.yaml
--num_workers 8
--batch_size 4 ; เปลี่ยน configs/data/scannet_dense_test.yaml เป็น configs/data/scannet_default_test.yaml เพื่อใช้ keyframes เฉพาะในกรณีที่คุณไม่ต้องการรอนานเกินไป
เราใช้การประเมินตาข่ายของ Transformerfusion สำหรับตารางผลลัพธ์หลักของเรา แต่ตั้งค่าเมล็ดเป็นค่าคงที่เพื่อความสอดคล้องเมื่อสุ่มตัวอย่างตาข่าย นอกจากนี้เรายังรายงานตัวชี้วัดตาข่ายโดยใช้การประเมินของ NeuralRecon ในวัสดุเสริม
สำหรับการประเมินผลของคลาวด์จุดเราใช้รหัสของ TransformerFusion แต่โหลดในจุดคลาวด์แทนการสุ่มตัวอย่างพื้นผิวของตาข่าย
โดยรุ่นเริ่มต้นและไฟล์เหตุการณ์ Tensorboard จะถูกบันทึกไว้ที่ ~/tmp/tensorboard/<model_name> สิ่งนี้สามารถเปลี่ยนแปลงได้ด้วยธง --log_dir
เราฝึกอบรมด้วย batch_size 16 ด้วยความแม่นยำ 16 บิตในสอง A100s ในการแยก Scannetv2 เริ่มต้น
คำสั่งตัวอย่างเพื่อฝึกด้วย GPU สองตัว:
CUDA_VISIBLE_DEVICES=0,1 python train.py --name HERO_MODEL
--log_dir logs
--config_file configs/models/hero_model.yaml
--data_config configs/data/scannet_default_train.yaml
--gpus 2
--batch_size 16 ; รหัสรองรับ GPU จำนวนเท่าใดก็ได้สำหรับการฝึกอบรม คุณสามารถระบุ GPU ที่จะใช้กับสภาพแวดล้อม CUDA_VISIBLE_DEVICES
การฝึกอบรมทั้งหมดของเราดำเนินการกับสอง Nvidia A100s
ชุดข้อมูลที่แตกต่างกัน
คุณสามารถฝึกอบรมในชุดข้อมูล MVS ที่กำหนดเองได้โดยการเขียนคลาส Dataloader ใหม่ซึ่งสืบทอดมาจาก GenericMVSDataset ที่ datasets/generic_mvs_dataset.py ดูคลาส ScannetDataset ใน datasets/scannet_dataset.py หรือคลาสอื่น ๆ ใน datasets สำหรับตัวอย่าง
หากต้องการ finetune ให้โหลดจุดตรวจสอบอย่างง่าย (ไม่กลับมาทำงาน!) และฝึกอบรมจากที่นั่น:
CUDA_VISIBLE_DEVICES=0 python train.py --config configs/models/hero_model.yaml
--data_config configs/data/scannet_default_train.yaml
--load_weights_from_checkpoint weights/hero_model.ckptเปลี่ยนการกำหนดค่าข้อมูลเป็นชุดข้อมูลใด ๆ ที่คุณต้องการ finetune
ดู options.py สำหรับช่วงของตัวเลือกการฝึกอบรมอื่น ๆ เช่นอัตราการเรียนรู้และการตั้งค่าการระเหยและตัวเลือกการทดสอบ
นอกเหนือจากการสร้างภาพข้อมูลเชิงลึกอย่างรวดเร็วในสคริปต์ test.py มีสคริปต์สองสคริปต์สำหรับการแสดงภาพความลึก
อย่างแรกคือ visualization_scripts/visualize_scene_depth_output.py สิ่งนี้จะสร้างวิดีโอที่มีภาพสีของเฟรมอ้างอิงและเฟรมแหล่งที่มาการทำนายความลึกประมาณการปริมาณต้นทุนความลึกของ GT และบรรทัดฐานโดยประมาณจากความลึก สคริปต์จะถือว่าคุณมีเอาต์พุตเชิงลึกโดยใช้ test.py และยอมรับรูปแบบเทมเพลตคำสั่งเดียวกันกับ test.py :
# Example command to get visualizations for dense frames
CUDA_VISIBLE_DEVICES=0 python ./visualization_scripts/visualize_scene_depth_output.py --name HERO_MODEL
--output_base_path OUTPUT_PATH
--data_config configs/data/scannet_dense_test.yaml
--num_workers 8 ; โดยที่ OUTPUT_PATH เป็นไดเรกทอรีผลลัพธ์พื้นฐานสำหรับ Simplerecon (สิ่งที่คุณใช้สำหรับการทดสอบเพื่อเริ่มต้นด้วย) คุณสามารถเลือกเรียกใช้ .visualization_scripts/generate_gt_min_max_cache.py ก่อนสคริปต์นี้เพื่อรับฉากเฉลี่ยสำหรับค่าความลึกขั้นต่ำและสูงสุดที่ใช้สำหรับ colormapping; หากไม่สามารถใช้งานได้สคริปต์จะใช้ 0m และ 5m สำหรับ colomapping min และ max
ครั้งที่สองอนุญาตให้มีการสร้างภาพสดของ meshing สคริปต์นี้จะใช้แผนที่ความลึกแคชถ้ามีมิฉะนั้นจะใช้แบบจำลองเพื่อทำนายก่อนการหลอมรวม สคริปต์จะโหลดซ้ำ ๆ ในแผนที่ความลึกหลอมรวมไฟล์ตาข่ายในขั้นตอนนี้และแสดงตาข่ายนี้พร้อมกับเครื่องหมายกล้องสำหรับวิดีโอ Birdseye และจากมุมมองของกล้องสำหรับวิดีโอ FPV
# Example command to get live visualizations for mesh reconstruction
CUDA_VISIBLE_DEVICES=0 python visualize_live_meshing.py --name HERO_MODEL
--output_base_path OUTPUT_PATH
--config_file configs/models/hero_model.yaml
--load_weights_from_checkpoint weights/hero_model.ckpt
--data_config configs/data/scannet_dense_test.yaml
--num_workers 8 ; โดยค่าเริ่มต้นสคริปต์จะบันทึกตาข่ายไปยังตำแหน่งกลางและคุณสามารถเลือกโหลดตาข่ายเหล่านั้นเพื่อประหยัดเวลาเมื่อเห็นภาพตาข่ายเดียวกันอีกครั้งโดยผ่าน --use_precomputed_partial_meshes ตาข่ายกลางทั้งหมดจะต้องคำนวณในการทำงานก่อนหน้านี้เพื่อให้การทำงานนี้ทำงานได้
tl; dr: world_T_cam == world_from_cam
repo นี้ใช้สัญกรณ์ "CAM_T_WORLD" เพื่อแสดงถึงการเปลี่ยนแปลงจากโลกสู่จุดกล้อง (extrinsics) ความตั้งใจคือการทำให้มันเพื่อให้ชื่อเฟรมพิกัดจะตรงกับทั้งสองด้านของตัวแปรเมื่อใช้ในการคูณจาก ขวาไปซ้าย :
cam_points = cam_T_world @ world_points
world_T_cam หมายถึงท่าทางของกล้อง (จาก Cam ไปจนถึง Coords World) ref_T_src หมายถึงการแปลงจากแหล่งที่มาเป็นมุมมองอ้างอิง
ในที่สุดสัญกรณ์นี้ช่วยให้เป็นตัวแทนของการหมุนและการแปลเช่น: world_R_cam และ world_t_cam
repo นี้มุ่งเน้นไปที่ Scannet ดังนั้นในขณะที่การทำงานของมันควรอนุญาตให้ระบบพิกัดใด ๆ (ส่งสัญญาณผ่านการตั้งค่าสถานะอินพุต) น้ำหนักของรุ่นที่เราให้ไว้ถือว่าระบบพิกัดสแกนเน็ต นี่เป็นสิ่งสำคัญเนื่องจากเรารวมข้อมูลเรย์เป็นส่วนหนึ่งของข้อมูลเมตา ชุดข้อมูลอื่น ๆ ที่ใช้กับน้ำหนักเหล่านี้ควรเปลี่ยนเป็นระบบ Scannet คลาสชุดข้อมูลที่เรารวมจะทำการแปลงที่เหมาะสม
มีข้อบกพร่องอยู่สองสามข้อในการอัปเดตนี้คุณจะต้องอัปเดตส้อมของคุณและใช้น้ำหนักใหม่จากตารางใกล้จุดเริ่มต้นของ readme นี้ คุณจะต้องตรวจสอบให้แน่ใจว่าคุณมีไฟล์ Intrinsics ที่ถูกต้องโดยใช้เครื่องอ่าน
ต้องขอบคุณทุกคนที่ชี้ให้เห็นและอดทนในขณะที่เราทำการแก้ไข
คะแนนทั้งหมดปรับปรุงด้วยการแก้ไขเหล่านี้และน้ำหนักที่เกี่ยวข้องจะถูกอัปโหลดที่นี่ สำหรับคะแนนเก่ารหัสและน้ำหนักให้ตรวจสอบ Hash Hash: 7DE5B451E340F9A11C7FD67BD0C42204D0B009A9
คะแนนเต็มสำหรับรุ่นที่มีการแก้ไขข้อผิดพลาด:
ความลึก
--config | abs diff ↓ | abs rel ↓ | sq rel ↓ | rmse ↓ | บันทึก rmse ↓ | เดลต้า <1.05 ↑ | เดลต้า <1.10 ↑ |
|---|---|---|---|---|---|---|---|
hero_model.yaml , metadata + resnet | 0.0868 | 0.0428 | 0.0127 | 0.1472 | 0.0681 | 74.26 | 90.88 |
dot_product_model.yaml , dot product + resnet | 0.0910 | 0.0453 | 0.0134 | 0.1509 | 0.0704 | 71.90 | 89.75 |
ฟิวชั่นตาข่าย
--config | ACC ↓ | คอมพ์↓ | ลบล้าง↓ | เรียกคืน↑ | ความแม่นยำ↑ | F-score ↑ |
|---|---|---|---|---|---|---|
hero_model.yaml , metadata + resnet | 5.41 | 5.98 | 5.69 | 0.695 | 0.668 | 0.680 |
dot_product_model.yaml , dot product + resnet | 5.66 | 6.18 | 5.92 | 0.682 | 0.655 | 0.667 |
การเปรียบเทียบ:
--config | แบบอย่าง | abs diff ↓ | sq rel ↓ | เดลต้า <1.05 ↑ | ลบล้าง↓ | F-score ↑ |
|---|---|---|---|---|---|---|
hero_model.yaml | การจับคู่ข้อมูลเมตา + resnet | 0.0868 | 0.0127 | 74.26 | 5.69 | 0.680 |
Old hero_model.yaml | การจับคู่ข้อมูลเมตา + resnet | 0.0885 | 0.0125 | 73.16 | 5.81 | 0.671 |
dot_product_model.yaml | การจับคู่ผลิตภัณฑ์ DOT + resnet | 0.0910 | 0.0134 | 71.90 | 5.92 | 0.667 |
dot_product_model.yaml เก่า | การจับคู่ผลิตภัณฑ์ DOT + resnet | 0.0941 | 0.0139 | 70.48 | 6.29 | 0.642 |
ในขั้นต้น repo นี้ถ่มน้ำลายไฟล์ tuple สำหรับ keyframes สไตล์ DVMVS เริ่มต้นที่มี 9 เฟรมพิเศษของ 25599 สำหรับชุดทดสอบ Scannetv2 มีข้อผิดพลาดเล็กน้อยกับการจัดการการติดตามที่หายไปซึ่งตอนนี้ได้รับการแก้ไขแล้ว repo นี้ควรเลียนแบบบัฟเฟอร์ Keyframe DVMVS อย่างแน่นอนพร้อมกับคีย์เฟรม 25590 สำหรับการทดสอบ เอฟเฟกต์ข้อผิดพลาดนี้มีเพียงการรวมเฟรมพิเศษ 9 เฟรมส่วนอื่น ๆ ทั้งหมดนั้นเหมือนกับ DVMVs เฟรมที่กระทำผิดอยู่ในการสแกนเหล่านี้
scan previous count new count
--------------------------------------
scene0711_00 393 392
scene0727_00 209 208
scene0736_00 1023 1022
scene0737_00 408 407
scene0751_00 165 164
scene0775_00 220 219
scene0791_00 227 226
scene0794_00 141 140
scene0795_00 102 101
ไฟล์ tuple สำหรับการทดสอบเริ่มต้นได้รับการอัปเดตแล้ว เนื่องจากนี่คือความแตกต่างเล็ก ๆ (~ 3E-4) ในการทำคะแนนพิเศษคะแนนไม่เปลี่ยนแปลง
TL; DR: ปรับขนาดท่าและครอบตัดภาพของคุณ
เราให้ข้อมูล Dataloader สำหรับการโหลดภาพจากการสร้าง Colmap Sparse Reconstruction เพื่อให้สิ่งนี้ทำงานร่วมกับ Simpleerecon คุณจะต้องครอบตัดภาพของคุณเพื่อให้ตรงกับ FOV ของ Scannet (คล้ายกับ FOV ของ iPhone ในโหมดวิดีโอ) และปรับตำแหน่งท่าทางของคุณโดยใช้การวัดในโลกแห่งความเป็นจริง หากขั้นตอนเหล่านี้ไม่ได้ดำเนินการปริมาณต้นทุนจะไม่ถูกสร้างขึ้นอย่างถูกต้องและเครือข่ายจะไม่ประเมินความลึกอย่างเหมาะสม
เราขอขอบคุณAljažBožič of Transformerfusion, Jiaming Sun of Neural Recon และ Arda Düzçeker of DeepVideomvs สำหรับการให้ข้อมูลที่เป็นประโยชน์อย่างรวดเร็วเพื่อช่วยในการเดินสาย
สคริปต์ Tuple Generation ใช้ประโยชน์จาก Keyframe Buffer ของ DeepVideOMVS รุ่นใหม่ (ขอบคุณอีกครั้ง Arda and Co!)
โมดูลฟิวชั่น Pytorch Point Cloud ที่รหัส torch_point_cloud_fusion ถูกยืมมาจาก repo ของ 3DVNET ขอบคุณ Alexander Rich!
นอกจากนี้เรายังขอขอบคุณทีมงานโครงสร้างพื้นฐานของ Niantic สำหรับการกระทำที่รวดเร็วเมื่อเราต้องการพวกเขา ขอบคุณคน!
โมฮาเหม็ดได้รับทุนจากทุนการศึกษาระดับปริญญาเอกของ Microsoft Research (MRL 2018-085)
หากคุณพบว่างานของเรามีประโยชน์ในการวิจัยของคุณโปรดพิจารณาอ้างถึงบทความของเรา:
@inproceedings{sayed2022simplerecon,
title={SimpleRecon: 3D Reconstruction Without 3D Convolutions},
author={Sayed, Mohamed and Gibson, John and Watson, Jamie and Prisacariu, Victor and Firman, Michael and Godard, Cl{'e}ment},
booktitle={Proceedings of the European Conference on Computer Vision (ECCV)},
year={2022},
}
ลิขสิทธิ์© Niantic, Inc. 2022. สิทธิบัตรที่รอดำเนินการ สงวนลิขสิทธิ์ โปรดดูไฟล์ใบอนุญาตสำหรับข้อกำหนด


