simplerecon
1.0.0
これは、で説明されている方法を使用して、MVS深度推定モデルをトレーニングおよびテストするためのPytorch実装の参照です
SimpleRecon:3D畳み込みのない3D再構成
Mohamed Sayed、John Gibson、Jamie Watson、Victor Adrian Prisacariu、Michael Firman、ClémentGodard
Paper、ECCV 2022(ARXIV PDF)、補足資料、プロジェクトページ、ビデオ
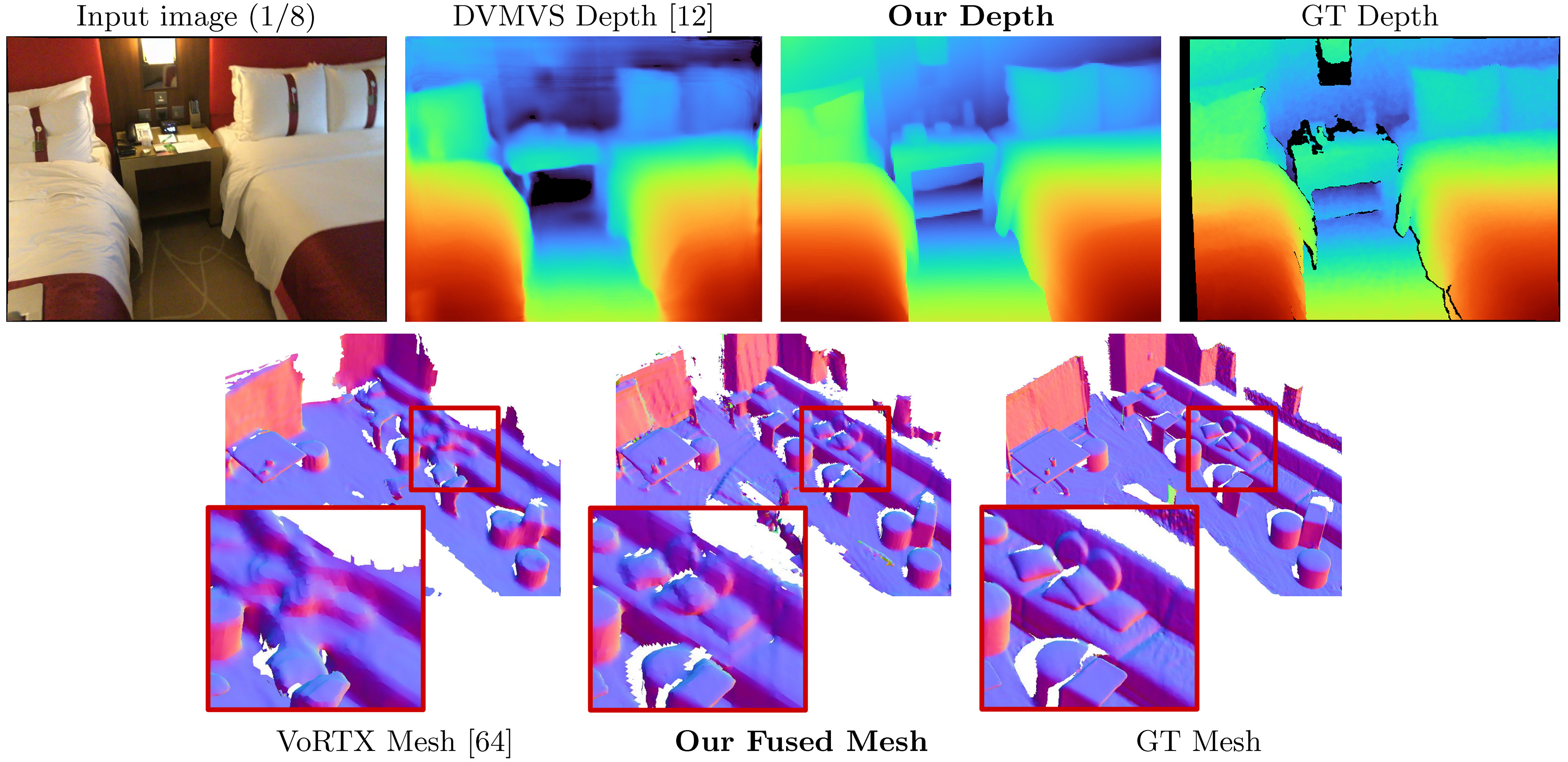
このコードは、非営利目的のためのものです。条件については、ライセンスファイルをご覧ください。このコードベースの一部が役立つ場合は、以下のbibtexを使用して論文を引用して、このレポをリンクしてください。ありがとう!
25/05/2023: llvm-openmp 、 clang 、およびprotobufのパッケージベリオンを修正しました。コードの実行に問題がある場合、および/またはデータロードが単一のスレッドに制限されている場合は、この新しい環境ファイルを使用してください。
09/03/2023:Korniaバージョンを環境ファイルに追加して、Korniaタイピングの問題を修正しました。 (ありがとう@natesimon!)
26/01/2023:ライセンスは、学問的な理由でモデルを実行するように変更されました。正確な詳細については、ライセンスファイルをご覧ください。
31/12/2022の時点で、わずかに間違った内因性、コストボリュームのフリップ増強、および投影の数値精度のバグを修正するアップデートがあります。すべてのスコアが改善します。フォークを更新し、新しいウェイトを使用する必要があります。バグ修正を参照してください。
オンラインデフォルトのフレームの事前計算スキャンは、https://drive.google.com/drive/folders/1dsofi9gayyhqjsx4i_ng0-3ebcafwxjv?usp=share_linkです
SimpleConは、入力がRGB画像をポーズにしたときに取得し、ターゲット画像の深さマップを出力します。
新鮮なアナコンダ分布を仮定すると、次のような依存関係をインストールできます。
conda env create -f simplerecon_env.ymlPytorch 1.10、Cuda 11.3、Python 3.9.7、Debian Gnu/Linux 10で実験を実行しました。
事前に処理されたモデルをweights/ Folderにダウンロードします。
次のモデルを提供します(スコアはオンラインデフォルトのキーフレームを使用しています):
--config | モデル | ABS Diff↓ | sq rel↓ | デルタ<1.05↑ | 面取り↓↓ | fスコア↑ |
|---|---|---|---|---|---|---|
hero_model.yaml | メタデータ +リセネットマッチング | 0.0868 | 0.0127 | 74.26 | 5.69 | 0.680 |
dot_product_model.yaml | DOT製品 + ResNetマッチング | 0.0910 | 0.0134 | 71.90 | 5.92 | 0.667 |
hero_model私たちが私たちのものとして論文で使用しているものです
--config | モデル | 推論速度( --batch_size 1 ) | 推論GPUメモリ | おおよそのトレーニング時間 |
|---|---|---|---|---|
hero_model | ヒーロー、メタデータ + resnet | 130ms / 70ms(速度最適化) | 2.6GB / 5.7GB(速度最適化) | 36時間 |
dot_product_model | ドット製品 + resnet | 80ms | 2.6GB | 36時間 |
バッチが大きくなると、速度が大幅に向上します。非速度最適化されたモデルにバッチサイズ8があるため、レイテンシは約40msに低下します。
datasets/arkit_dataset.pyにあります。更新:現在、data_scripts/ios_logger_processing.pyでスクリプトを使用して推論を処理して実行する方法について、すばやくreadme data_scripts/ios_logger_preprocessing.pyがあります。 これで、コードをすぐに試してみるための2つのスキャンが含まれています。ここからこれらのスキャンをダウンロードできます。
ステップ:
hero_modelのWeightsをWeightsディレクトリにダウンロードします。configs/data/vdr_dense.yamlのオプションdataset_pathの値を、解凍されたVDRフォルダーのベースパスに変更します。CUDA_VISIBLE_DEVICES=0 python test.py --name HERO_MODEL
--output_base_path OUTPUT_PATH
--config_file configs/models/hero_model.yaml
--load_weights_from_checkpoint weights/hero_model.ckpt
--data_config configs/data/vdr_dense.yaml
--num_workers 8
--batch_size 2
--fast_cost_volume
--run_fusion
--depth_fuser open3d
--fuse_color
--dump_depth_visualization ;これにより、出力メッシュ、クイック深度Viz、およびsocresがOUTPUT_PATH下でlidarの深さに対してベンチマークされたときにソクレが出力されます。
このコマンドは、すべてのフレームの深さを生成し、それらをメッシュに融合するvdr_dense.yamlを使用します。論文では、代わりに融合キーフレームでスコアを報告し、 vdr_default.yamlを使用してそれらを実行できます。代わりにvdr_dense_offline.yamlを使用して、 dense_offlineタプルを使用することもできます。
テストと評価については、以下のセクションを参照してください。データセットに正しい構成フラグを使用してください。
ここの手順に従って、データセットをダウンロードしてください。このデータセットは非常に大きい(> 2TB)ので、特にファイルを抽出するのに十分なスペースがあることを確認してください。
ダウンロードしたら、このスクリプトを使用して、生センサーデータを画像と深度ファイルにエクスポートします。
簡単なチュートリアルを作成し、Scannetv2のダウンロードと抽出に役立つ修正されたスクリプトを含めました。 data_scripts/scannet_wrangling_scripts/でそれらを見つけることができます
configs/data/でscannetv2データ構成のdataset_path config引数を変更する必要があります。
コードベースは、scannetv2が次の形式であると予想しています。
dataset_path
scans_test (test scans)
scene0707
scene0707_00_vh_clean_2.ply (gt mesh)
sensor_data
frame-000261.pose.txt
frame-000261.color.jpg
frame-000261.color.512.png (optional, image at 512x384)
frame-000261.color.640.png (optional, image at 640x480)
frame-000261.depth.png (full res depth, stored scale *1000)
frame-000261.depth.256.png (optional, depth at 256x192 also
scaled)
scene0707.txt (scan metadata and image sizes)
intrinsic
intrinsic_depth.txt
intrinsic_color.txt
...
scans (val and train scans)
scene0000_00
(see above)
scene0000_01
....
この例ではscene0707.txtスキャンのメタデータを含める必要があります。
colorHeight = 968
colorToDepthExtrinsics = 0.999263 -0.010031 0.037048 ........
colorWidth = 1296
depthHeight = 480
depthWidth = 640
fx_color = 1170.187988
fx_depth = 570.924255
fy_color = 1170.187988
fy_depth = 570.924316
mx_color = 647.750000
mx_depth = 319.500000
my_color = 483.750000
my_depth = 239.500000
numColorFrames = 784
numDepthFrames = 784
numIMUmeasurements = 1632
frame-000261.pose.txtフォームのポーズを含める必要があります。
-0.384739 0.271466 -0.882203 4.98152
0.921157 0.0521417 -0.385682 1.46821
-0.0587002 -0.961035 -0.270124 1.51837
frame-000261.color.512.pngおよびframe-000261.color.640.pngは、トレーニングとテスト中に負荷と計算時間を節約するために、元の画像のサイズ変更されたバージョンです。 frame-000261.depth.256.png深度マップの前提条件のサイズ変更バージョンでもあります。
ディープと画像の前身バージョンはすべて、必要ではありませんが、必要ではありません。それらが存在しない場合、フル解像度バージョンはロードされ、その場でダウンサンプリングされます。
デフォルトでは、スキャン内の各キーフレームの深度マップを推定します。キーフレーム分離のためにdeepvideomvsのヒューリスティックを使用し、一致するタプルを構築します。深さ融合のために、これらのキーフレームで深度マップを使用します。各キーフレームについて、コストボリュームの構築に使用されるソースフレームのリストを関連付けます。また、特定のキーフレームだけでなく、データ内の各フレームの深さマップを予測する密なタプルも使用します。これらは主に視覚化に使用されます。
データセットの要素として機能するすべてのスキャンにわたって、タプルのリストを生成およびエクスポートします。これらのリストを事前に計算しましたが、各データセットの分割の下でdata_splitsで利用できます。 Scannetのテストスキャンではdata_splits/ScanNetv2/standard_splitにあります。コア深度番号はdata_splits/ScanNetv2/standard_split/test_eight_view_deepvmvs.txtを使用して計算されます。
これは、テスト用のタプルのタイプの簡単な分類群です。
default :すべてのソースフレームが過去にあるDeepVideomvsに続くすべてのキーフレームのタプル。特に明記しない限り、すべての深さとメッシュの評価に使用されます。 scannetを使用してdata_splits/ScanNetv2/standard_split/test_eight_view_deepvmvs.txtを使用します。offline :現在のフレームと比較して、ソースフレームが過去と未来の両方で可能になるスキャン内のすべてのフレームのタプル。これらは、シーンがオフラインでキャプチャされる場合に役立ち、可能な限り最高の精度を必要とします。オンラインのタプルを使用すると、カメラが移動し、すべてのソースフレームが遅れているため、コストボリュームには空の領域が含まれます。ただし、オフラインのタプルでは、コストボリュームは両端でいっぱいで、スケール(およびメトリック)の推定値が向上します。dense :すべてのソースフレームが過去にあるスキャン内のすべてのフレームのオンラインタプル(デフォルトなど)。 scannetの場合、これはdata_splits/ScanNetv2/standard_split/test_eight_view_deepvmvs_dense.txtです。offline :スキャン内のすべてのキーフレームのすべてのキーフレームのオフラインタプル。列車と検証セットの場合、DeepVideomvsと同じタプル増強戦略に従い、同じコア生成スクリプトを使用します。
これらのタプルを自分で生成したい場合は、スクリプトをdata_scripts/generate_train_tuples.pyでトレインタプルとdata_scripts/generate_test_tuples.pyで使用できます。これらはtest.pyと同じ構成形式に従い、ビルドするデータセットクラスを使用してポーズインフォドンを読み取ります。
テストの例:
# default tuples
python ./data_scripts/generate_test_tuples.py
--data_config configs/data/scannet_default_test.yaml
--num_workers 16
# dense tuples
python ./data_scripts/generate_test_tuples.py
--data_config configs/data/scannet_dense_test.yaml
--num_workers 16電車の例:
# train
python ./data_scripts/generate_train_tuples.py
--data_config configs/data/scannet_default_train.yaml
--num_workers 16
# val
python ./data_scripts/generate_val_tuples.py
--data_config configs/data/scannet_default_val.yaml
--num_workers 16これらのスクリプトは、最初にデータセット内の各フレームをチェックして、既存のRGBフレーム、既存の深度フレーム(データセットに適切な場合)、および既存の有効なポーズファイルを備えていることを確認します。これらのvalid_framesは各スキャンのフォルダーのテキストファイルに保存されますが、ディレクトリが読み取られる場合、 valid_framesファイルの保存を無視してタプルを生成します。
test.pyを使用して、深さマップを推測および評価し、メッシュを融合できます。
すべての結果は、以下のベース結果フォルダー(Results_Path)に保存されます。
opts.output_base_path/opts.name/opts.dataset/opts.frame_tuple_type/
Optsはoptionsクラスです。たとえば、 opts.output_base_pathが./resultsである場合、 opts.nameはHERO_MODEL 、 opts.datasetはscannet 、 opts.frame_tuple_typeはdefaultです。
./results/HERO_MODEL/scannet/default/
結果を保存するのに適したディレクトリに--opts.output_base_path設定してください。
--frame_tuple_typeは、MVSに使用される画像タプルのタイプです。使用したdata_configファイルで選択を提供する必要があります。
デフォルトでは、 test.py各フレームの深さスコアを計算しようとし、フレーム平均とシーンの平均メトリックの両方を提供します。スクリプトはresults_path/scoresの下でこれらのスコア(シーンごとと合計)を保存します。
一致するエンコーダーを介したトーチバッチバグが、そのエンコーダを介して画像バッチを無効にすることにより(<10^-4)正確なテストに対して固定されるように最善を尽くしました。 run --batch_size 4疑わしい場合は、可能な数字と同じくらい安定してPytorch Gremlinsを避けようとしている場合は、比較評価に--batch_size 1使用します。
これを速度で使用する場合は、 --fast_cost_volume trueに設定します。これにより、一致するエンコーダーを介したバッチを有効にし、EINOPS最適化されたフィーチャボリュームを有効にします。
# Example command to just compute scores
CUDA_VISIBLE_DEVICES=0 python test.py --name HERO_MODEL
--output_base_path OUTPUT_PATH
--config_file configs/models/hero_model.yaml
--load_weights_from_checkpoint weights/hero_model.ckpt
--data_config configs/data/scannet_default_test.yaml
--num_workers 8
--batch_size 4 ;
# If you'd like to get a super fast version use:
CUDA_VISIBLE_DEVICES=0 python test.py --name HERO_MODEL
--output_base_path OUTPUT_PATH
--config_file configs/models/hero_model.yaml
--load_weights_from_checkpoint weights/hero_model.ckpt
--data_config configs/data/scannet_default_test.yaml
--num_workers 8
--fast_cost_volume
--batch_size 2 ;このスクリプトは、以下を含むいくつかの異なる補助タスクを実行するためにも使用できます。
TSDF融合
TSDF Fusionを実行するには、 --run_fusionフラグを提供します。フューザーには2つの選択肢があります
--depth_fuser ours (デフォルト)は、ほとんどの視覚化およびスコアでメッシュが使用されるフューザーを使用します。このフューザーは色をサポートしていません。 scikit-imageのカスタムブランチを提供しました。 measure.matching_cubesのカスタム実装。単一の壁を許可するmatching_cubes。評価には、単一の壁のメッシュを使用します。これが重要でない場合は、 test.pyのexport_meshへの呼び出しのためにexport_single_meshをFalseに設定できます。--depth_fuser open3d Open3D Depth Fuserを使用します。このフューザーは色をサポートしており、 --fuse_colorフラグを使用してこれを有効にすることができます。デフォルトでは、フュージョンのために深さマップを3Mにクリップし、0.04m 3のTSDF解像度を使用しますが、 --max_fusion_depthと--fusion_resolution両方を変更することでそれを変更できます
--mask_pred_depthsを使用してVAIID MVS情報が存在しない場合、融合がマスクされるために使用される予測される深さをオプションで要求できます。これはデフォルトでは有効になりません。
また、コストボリュームエンコーダーデコーダーが事前に強力な画像を導入する前に、コストボリュームから最高の推測深度を融合することもできます。 --fusion_use_raw_lowest_costを使用してこれを行うことができます。
メッシュはresults_path/meshes/に保存されます。
# Example command to fuse depths to get meshes
CUDA_VISIBLE_DEVICES=0 python test.py --name HERO_MODEL
--output_base_path OUTPUT_PATH
--config_file configs/models/hero_model.yaml
--load_weights_from_checkpoint weights/hero_model.ckpt
--data_config configs/data/scannet_default_test.yaml
--num_workers 8
--run_fusion
--batch_size 8 ;深さをキャッシュします
--cache_depthsフラグを提供することにより、オプションで深さを保存できます。それらはresults_path/depthsに保存されます。
# Example command to compute scores and cache depths
CUDA_VISIBLE_DEVICES=0 python test.py --name HERO_MODEL
--output_base_path OUTPUT_PATH
--config_file configs/models/hero_model.yaml
--load_weights_from_checkpoint weights/hero_model.ckpt
--data_config configs/data/scannet_default_test.yaml
--num_workers 8
--cache_depths
--batch_size 8 ;
# Example command to fuse depths to get color meshes
CUDA_VISIBLE_DEVICES=0 python test.py --name HERO_MODEL
--output_base_path OUTPUT_PATH
--config_file configs/models/hero_model.yaml
--load_weights_from_checkpoint weights/hero_model.ckpt
--data_config configs/data/scannet_default_test.yaml
--num_workers 8
--run_fusion
--depth_fuser open3d
--fuse_color
--batch_size 4 ;クイックViz
出力の深さと融合のより深い視覚化のための他のスクリプトがありますが、深度マップの視覚化を迅速にエクスポートするには、 --dump_depth_visualization使用できます。視覚化はresults_path/viz/quick_viz/に保存されます。
# Example command to output quick depth visualizations
CUDA_VISIBLE_DEVICES=0 python test.py --name HERO_MODEL
--output_base_path OUTPUT_PATH
--config_file configs/models/hero_model.yaml
--load_weights_from_checkpoint weights/hero_model.ckpt
--data_config configs/data/scannet_default_test.yaml
--num_workers 8
--dump_depth_visualization
--batch_size 4 ; また、3DVNETのリポジトリのフューザーを使用して、深度マップのポイントクラウドフュージョンを許可します。
# Example command to fuse depths into point clouds.
CUDA_VISIBLE_DEVICES=0 python pc_fusion.py --name HERO_MODEL
--output_base_path OUTPUT_PATH
--config_file configs/models/hero_model.yaml
--load_weights_from_checkpoint weights/hero_model.ckpt
--data_config configs/data/scannet_dense_test.yaml
--num_workers 8
--batch_size 4 ; configs/data/scannet_dense_test.yaml configs/data/scannet_default_test.yamlに変更して、あまり長く待たない場合にのみキーフレームを使用します。
メインの結果テーブルには、トランスフュージョンのメッシュ評価を使用しますが、メッシュをランダムにサンプリングすると、一貫性のためにシードを固定値に設定します。また、補足資料でのNeuralReconの評価を使用してメッシュメトリックを報告します。
ポイントクラウド評価には、TransformerFusionのコードを使用しますが、メッシュの表面をサンプリングする代わりにポイントクラウドにロードします。
デフォルトでは、モデルとテンソルボードイベントファイルは~/tmp/tensorboard/<model_name>に保存されます。これは、 --log_dirフラグで変更できます。
デフォルトのscannetv2分割で2つのA100で16ビットの精度で16のbatch_sizeでトレーニングします。
2つのGPUでトレーニングする例コマンド:
CUDA_VISIBLE_DEVICES=0,1 python train.py --name HERO_MODEL
--log_dir logs
--config_file configs/models/hero_model.yaml
--data_config configs/data/scannet_default_train.yaml
--gpus 2
--batch_size 16 ;このコードは、トレーニングのために任意の数のGPUをサポートしています。 CUDA_VISIBLE_DEVICES環境で使用するgpusを指定できます。
すべてのトレーニングの実行は、2つのNVIDIA A100で実行されました。
別のデータセット
datasets/generic_mvs_dataset.pyでGenericMVSDatasetから継承する新しいDataloaderクラスを作成することにより、カスタムMVSデータセットでトレーニングできます。 datasets/scannet_dataset.pyのScannetDatasetクラス、または実際には、 datasetsの他のクラスを参照してください。
微調整するには、チェックポイントを単純にロードし(履歴書ではありません!)、そこからトレーニングしてください。
CUDA_VISIBLE_DEVICES=0 python train.py --config configs/models/hero_model.yaml
--data_config configs/data/scannet_default_train.yaml
--load_weights_from_checkpoint weights/hero_model.ckptFinetuneに希望するデータセットにデータ構成を変更します。
学習率やアブレーション設定、テストオプションなど、他のトレーニングオプションの範囲については、 options.py参照してください。
test.pyスクリプトの迅速な深さの視覚化以外に、深さ出力を視覚化するための2つのスクリプトがあります。
1つ目はvisualization_scripts/visualize_scene_depth_output.pyです。これにより、参照およびソースフレームのカラー画像、深さ予測、コストボリュームの推定、GT深さ、および深さからの推定法線のビデオが作成されます。スクリプトは、 test.pyを使用してキャッシュされた深度出力があると想定し、 test.pyと同じコマンドテンプレート形式を受け入れます。
# Example command to get visualizations for dense frames
CUDA_VISIBLE_DEVICES=0 python ./visualization_scripts/visualize_scene_depth_output.py --name HERO_MODEL
--output_base_path OUTPUT_PATH
--data_config configs/data/scannet_dense_test.yaml
--num_workers 8 ; OUTPUT_PATH simplereconのベース結果ディレクトリ(最初からテストに使用したもの)です。オプションで、 .visualization_scripts/generate_gt_min_max_cache.pyこのスクリプトの前に実行して、コロマッピングに使用される最小および最大深度値のシーンの平均を取得できます。それらが利用できない場合、スクリプトはコロマッピングMinとMaxに0mと5mを使用します。
2番目は、メッシュのライブ視覚化を可能にします。このスクリプトは、利用可能な場合はキャッシュされた深度マップを使用します。そうしないと、モデルを使用して融合前に予測します。スクリプトは、深度マップに繰り返しロードされ、融合し、このステップでメッシュファイルを保存し、このメッシュをバードイヤのビデオのカメラマーカーと並んで、およびFPVビデオのカメラの観点からレンダリングします。
# Example command to get live visualizations for mesh reconstruction
CUDA_VISIBLE_DEVICES=0 python visualize_live_meshing.py --name HERO_MODEL
--output_base_path OUTPUT_PATH
--config_file configs/models/hero_model.yaml
--load_weights_from_checkpoint weights/hero_model.ckpt
--data_config configs/data/scannet_dense_test.yaml
--num_workers 8 ;デフォルトでは、スクリプトはメッシュを中間位置に保存し、オプションでこれらのメッシュをロードして、同じメッシュを再度--use_precomputed_partial_meshes化するときに再び視覚化するときに時間を節約できます。すべての中間メッシュは、これが機能するために前の実行で計算する必要がありました。
tl; dr: world_T_cam == world_from_cam
このレポは、表記「CAM_T_WORLD」を使用して、世界からカメラポイント(外交)への変換を示します。意図は、右から左への乗算で使用すると、座標フレーム名が変数の両側で一致するようにすることです。
cam_points = cam_T_world @ world_points
world_T_cam 、カメラのポーズを示します(カムからワールドコードまで)。 ref_T_src 、ソースから参照ビューへの変換を示します。
最後に、この表記は、 world_R_camやworld_t_camなどの回転と翻訳の両方を表すことができます
このリポジトリはScannetを対象としているため、その機能は任意の座標系(入力フラグを介して信号)を可能にする必要がありますが、私たちが提供するモデルの重みはScannet座標系を想定しています。これは、メタデータの一部としてRay情報を含めるため重要です。これらの重みで使用される他のデータセットは、Scannetシステムに変換する必要があります。含まれるデータセットクラスは、適切な変換を実行します。
このアップデートにはいくつかのバグがあります。フォークを更新し、このREADMEの最初のテーブルから新しいウェイトを使用する必要があります。また、読者を使用して正しい内因性ファイルが抽出されていることを確認する必要があります。
私たちが修正に取り組んでいる間、それを指摘し、忍耐強い人たちに感謝します。
これらの修正によりすべてのスコアが改善され、関連する重みがここにアップロードされます。古いスコア、コード、および重量については、このコミットハッシュ:7DE5B451E340F9A11C7FD67BD0C42204D0B009A9を確認してください
バグ修正を備えたモデルのフルスコア:
深さ
--config | ABS Diff↓ | ABS rel↓ | sq rel↓ | RMSE↓ | ログrmse↓ | デルタ<1.05↑ | デルタ<1.10↑ |
|---|---|---|---|---|---|---|---|
hero_model.yaml 、メタデータ + resnet | 0.0868 | 0.0428 | 0.0127 | 0.1472 | 0.0681 | 74.26 | 90.88 |
dot_product_model.yaml 、dot product + resnet | 0.0910 | 0.0453 | 0.0134 | 0.1509 | 0.0704 | 71.90 | 89.75 |
メッシュフュージョン
--config | ACC↓ | comp↓ | 面取り↓↓ | ↑を思い出してください | 精度↑ | fスコア↑ |
|---|---|---|---|---|---|---|
hero_model.yaml 、メタデータ + resnet | 5.41 | 5.98 | 5.69 | 0.695 | 0.668 | 0.680 |
dot_product_model.yaml 、dot product + resnet | 5.66 | 6.18 | 5.92 | 0.682 | 0.655 | 0.667 |
比較:
--config | モデル | ABS Diff↓ | sq rel↓ | デルタ<1.05↑ | 面取り↓↓ | fスコア↑ |
|---|---|---|---|---|---|---|
hero_model.yaml | メタデータ +リセネットマッチング | 0.0868 | 0.0127 | 74.26 | 5.69 | 0.680 |
Old hero_model.yaml | メタデータ +リセネットマッチング | 0.0885 | 0.0125 | 73.16 | 5.81 | 0.671 |
dot_product_model.yaml | DOT製品 + ResNetマッチング | 0.0910 | 0.0134 | 71.90 | 5.92 | 0.667 |
古いdot_product_model.yaml | DOT製品 + ResNetマッチング | 0.0941 | 0.0139 | 70.48 | 6.29 | 0.642 |
当初、このレポは、scannetv2テストセットの9追加フレーム25599を備えたデフォルトのDVMVSスタイルのキーフレームのタプルファイルを吐き出しました。トラッキングの紛失を処理するマイナーなバグがあり、現在修正されています。このレポは、テスト用の25590キーフレームを使用して、DVMVSキーフレームバッファーを正確に模倣する必要があります。このバグが与えた唯一の効果は、9つの追加フレームを含めることでした。他のすべてのタプルはDVMVとまったく同じでした。問題のあるフレームはこれらのスキャンにあります
scan previous count new count
--------------------------------------
scene0711_00 393 392
scene0727_00 209 208
scene0736_00 1023 1022
scene0737_00 408 407
scene0751_00 165 164
scene0775_00 220 219
scene0791_00 227 226
scene0794_00 141 140
scene0795_00 102 101
デフォルトテスト用のTupleファイルが更新されました。これはスコアの余分なフレームの小さな(〜3E-4)の違いであるため、スコアは変更されていません。
tl; dr:ポーズを拡大して画像をトリミングします。
ColMapスパース再構成から画像をロードするためのデータローダーを提供します。これをSimpleConで動作させるには、ScannetのFOVに合わせて画像をトリミングする必要があります(ビデオモードのiPhoneのFOVとほぼ同様)。これらの手順が取られない場合、コストボリュームは正しく構築されず、ネットワークは深さを適切に推定しません。
トランスフュージョンのAljažBožič、Neural ReconのJiaming Sun、およびDeepvideomvsのArdaDüzçekerに、特に短期間でコードベースを簡単に利用できるようにするための有用な情報を迅速に提供してくれたことに感謝します。
Tuple Generationスクリプトは、DeepVideOMVSのキーフレームバッファーの変更されたバージョンを多用しています(ArdaとCo!)。
torch_point_cloud_fusionコードのPytorch Point Cloud Fusion Moduleは、3DVNetのレポから借用されています。アレクサンダーリッチに感謝します!
また、Nianticのインフラストラクチャチームが必要なときに迅速なアクションについて感謝したいと思います。ありがとう!
Mohamedは、Microsoft Research PhD奨学金(MRL 2018-085)によって資金提供されています。
あなたがあなたの研究で私たちの作品が役立つと思うなら、私たちの論文を引用することを検討してください:
@inproceedings{sayed2022simplerecon,
title={SimpleRecon: 3D Reconstruction Without 3D Convolutions},
author={Sayed, Mohamed and Gibson, John and Watson, Jamie and Prisacariu, Victor and Firman, Michael and Godard, Cl{'e}ment},
booktitle={Proceedings of the European Conference on Computer Vision (ECCV)},
year={2022},
}
Copyright©Niantic、Inc。2022。無断転載を禁じます。条件については、ライセンスファイルをご覧ください。


