simplerecon
1.0.0
Il s'agit de la mise en œuvre de référence Pytorch pour la formation et le test des modèles d'estimation de la profondeur MVS en utilisant la méthode décrite dans
Simplerecon: reconstruction 3D sans convolutions 3D
Mohamed Sayed, John Gibson, Jamie Watson, Victor Adrian Prisacariu, Michael Firman et Clement Godard
Paper, ECCV 2022 (ARXIV PDF), matériel supplémentaire, page de projet, vidéo
Ce code est pour une utilisation non commerciale; Veuillez consulter le fichier de licence pour les conditions. Si vous trouvez une partie de cette base de code utile, veuillez citer notre article à l'aide du bibtex ci-dessous et lier ce référentiel. Merci!
25/05/2023: Véritions du package fixe pour llvm-openmp , clang et protobuf . Utilisez ce nouveau fichier d'environnement si vous avez du mal à exécuter le code et / ou si le coré de données est limité à un seul thread.
09/03/2023: Ajout de la version Kornia au fichier Environments pour résoudre le problème de typage de Kornia. (Merci @Natesimon!)
26/01/2023: La licence a été modifiée pour faciliter la gestion du modèle pour des raisons académiques. Veuillez le fichier de licence pour les détails exacts.
Il y a une mise à jour au 31/12/2022 qui corrige une légère intrinsèque, une augmentation de flip pour le volume des coûts et un bug de précision numérique en projection. Tous les scores s'améliorent. Vous devrez mettre à jour vos fourches et utiliser de nouveaux poids. Voir les correctifs de bug.
Les analyses précomputées pour les cadres par défaut en ligne sont ici: https://drive.google.com/drive/folders/1dsofi9gayyhqjsx4i_ng0-3ebcafwxjv?usp=share_link
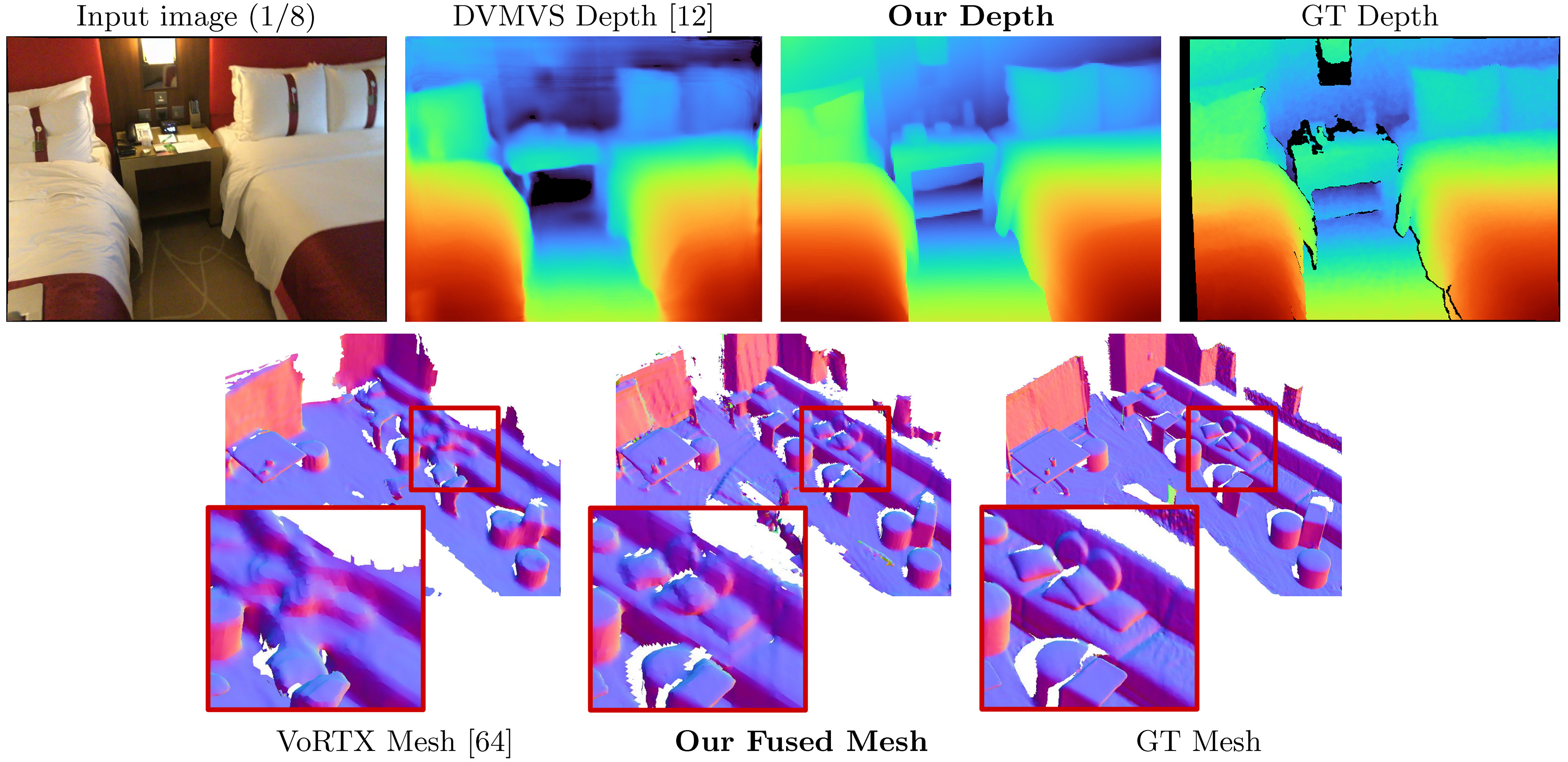
SimplereCon prend les images RVB posées en entrée et publie une carte de profondeur pour une image cible.
En supposant une nouvelle distribution Anaconda, vous pouvez installer des dépendances avec:
conda env create -f simplerecon_env.ymlNous avons dirigé nos expériences avec Pytorch 1.10, Cuda 11.3, Python 3.9.7 et Debian GNU / Linux 10.
Téléchargez un modèle pré-entraîné dans les weights/ dossiers.
Nous fournissons les modèles suivants (les scores sont avec les images clés par défaut en ligne):
--config | Modèle | ABS Diff ↓ | SQ Rel ↓ | delta <1,05 ↑ | Chanfrein ↓ | F-score ↑ |
|---|---|---|---|---|---|---|
hero_model.yaml | Metadata + Resnet correspondant | 0,0868 | 0,0127 | 74.26 | 5.69 | 0,680 |
dot_product_model.yaml | DOT Product + Resnet correspondant | 0,0910 | 0,0134 | 71.90 | 5.92 | 0,667 |
hero_model est celui que nous utilisons dans le papier comme le nôtre
--config | Modèle | Vitesse d'inférence ( --batch_size 1 ) | Mémoire de GPU d'inférence | Temps de formation approximatif |
|---|---|---|---|---|
hero_model | Héros, métadonnées + resnet | 130 ms / 70 ms (vitesse optimisée) | 2,6 Go / 5,7 Go (vitesse optimisée) | 36 heures |
dot_product_model | Produit DOT + Resnet | 80 ms | 2,6 Go | 36 heures |
Avec des lots plus importants, la vitesse augmente considérablement. Avec la taille du lot 8 sur le modèle optimisé sans vitesse, la latence tombe à ~ 40 ms.
datasets/arkit_dataset.py . MISE À JOUR: Il existe maintenant une lecture rapide Data_Scripts / iOS_Logger_arkit_readme.md pour comment traiter et exécuter une numérisation iOS-Logger à l'aide du script sur data_scripts/ios_logger_preprocessing.py . Nous avons maintenant inclus deux analyses pour les gens pour essayer immédiatement avec le code. Vous pouvez télécharger ces analyses à partir d'ici.
Mesures:
hero_model dans le répertoire des poids.dataset_path dans configs/data/vdr_dense.yaml sur le chemin de base du dossier VDR non décompressé.CUDA_VISIBLE_DEVICES=0 python test.py --name HERO_MODEL
--output_base_path OUTPUT_PATH
--config_file configs/models/hero_model.yaml
--load_weights_from_checkpoint weights/hero_model.ckpt
--data_config configs/data/vdr_dense.yaml
--num_workers 8
--batch_size 2
--fast_cost_volume
--run_fusion
--depth_fuser open3d
--fuse_color
--dump_depth_visualization ; Cela sortira des maillages, une profondeur rapide à savoir et SOCRES lorsqu'il est comparé à la profondeur lidar sous OUTPUT_PATH .
Cette commande utilise vdr_dense.yaml qui générera des profondeurs pour chaque trame et les fusionnera dans un maillage. Dans l'article, nous rapportons à la place des scores avec des clés fusionnés, et vous pouvez exécuter ceux à l'aide de vdr_default.yaml . Vous pouvez également utiliser des tuples dense_offline en utilisant à la place vdr_dense_offline.yaml .
Voir la section ci-dessous sur les tests et l'évaluation. Assurez-vous d'utiliser les indicateurs de configuration corrects pour les ensembles de données.
Veuillez suivre les instructions ici pour télécharger l'ensemble de données. Cet ensemble de données est assez grand (> 2 To), alors assurez-vous d'avoir suffisamment d'espace, en particulier pour extraire des fichiers.
Une fois téléchargé, utilisez ce script pour exporter des données de capteur brutes vers des images et des fichiers de profondeur.
Nous avons écrit un tutoriel rapide et inclus des scripts modifiés pour vous aider à télécharger et à extraire SCANNETV2. Vous pouvez les trouver chez DATA_Scripts / scannet_wrangling_scripts /
Vous devez modifier l'argument de configuration de dataset_path pour les configurations de données scannetv2 sur configs/data/ pour correspondre à votre ensemble de données.
La base de code s'attend à ce que ScanNetv2 soit dans le format suivant:
dataset_path
scans_test (test scans)
scene0707
scene0707_00_vh_clean_2.ply (gt mesh)
sensor_data
frame-000261.pose.txt
frame-000261.color.jpg
frame-000261.color.512.png (optional, image at 512x384)
frame-000261.color.640.png (optional, image at 640x480)
frame-000261.depth.png (full res depth, stored scale *1000)
frame-000261.depth.256.png (optional, depth at 256x192 also
scaled)
scene0707.txt (scan metadata and image sizes)
intrinsic
intrinsic_depth.txt
intrinsic_color.txt
...
scans (val and train scans)
scene0000_00
(see above)
scene0000_01
....
Dans cet exemple, scene0707.txt doit contenir les métadonnées du scan:
colorHeight = 968
colorToDepthExtrinsics = 0.999263 -0.010031 0.037048 ........
colorWidth = 1296
depthHeight = 480
depthWidth = 640
fx_color = 1170.187988
fx_depth = 570.924255
fy_color = 1170.187988
fy_depth = 570.924316
mx_color = 647.750000
mx_depth = 319.500000
my_color = 483.750000
my_depth = 239.500000
numColorFrames = 784
numDepthFrames = 784
numIMUmeasurements = 1632
frame-000261.pose.txt doit contenir une pose dans le formulaire:
-0.384739 0.271466 -0.882203 4.98152
0.921157 0.0521417 -0.385682 1.46821
-0.0587002 -0.961035 -0.270124 1.51837
frame-000261.color.512.png et frame-000261.color.640.png sont des versions redimensionnées précatirées de l'image d'origine pour économiser le temps de chargement et de calculer le temps pendant la formation et les tests. frame-000261.depth.256.png est également une version redimensionnée pré-muette de la carte de profondeur.
Toutes les versions pré-redimensionnées de la profondeur et des images sont agréables à avoir mais pas nécessaires. S'ils n'existent pas, les versions de résolution complète seront chargées et échantillonnent à la volée.
Par défaut, nous estimons une carte de profondeur pour chaque image clé dans un scan. Nous utilisons l'heuristique de DeepvideoMV pour la séparation des images clés et construisons des tuples pour correspondre. Nous utilisons les cartes de profondeur à ces images clés pour la fusion de profondeur. Pour chaque image clé, nous associons une liste de trames source qui seront utilisées pour construire le volume des coûts. Nous utilisons également des tuples denses, où nous prédisons une carte de profondeur pour chaque trame des données, et pas seulement à des images clés spécifiques; Ceux-ci sont principalement utilisés pour la visualisation.
Nous générons et exportons une liste de tuples sur tous les analyses qui agissent comme les éléments de l'ensemble de données. Nous avons précomposé ces listes et elles sont disponibles sur data_splits sous la scission de chaque ensemble de données. Pour les analyses de test de scannet, ils sont sur data_splits/ScanNetv2/standard_split . Nos numéros de profondeur de base sont calculés à l'aide de data_splits/ScanNetv2/standard_split/test_eight_view_deepvmvs.txt .
Voici une taxe rapide du type de tuples pour le test:
default : un tuple pour chaque image clé suivant DeepVideoMVS où toutes les trames source se trouvent dans le passé. Utilisé pour toute évaluation de profondeur et de maillage, sauf indication contraire. Pour scannet, utilisez data_splits/ScanNetv2/standard_split/test_eight_view_deepvmvs.txt .offline : un tuple pour chaque trame du scan où les trames source peuvent être à la fois dans le passé et le futur par rapport à la trame actuelle. Ceux-ci sont utiles lorsqu'une scène est capturée hors ligne et que vous voulez la meilleure précision possible. Avec les tuples en ligne, le volume des coûts contiendra des régions vides à mesure que la caméra s'éloigne et que toutes les cadres source sont à la traîne; Cependant, avec les tuples hors ligne, le volume des coûts est plein aux deux extrémités, conduisant à une meilleure échelle (et métrique).dense : un tuple en ligne (comme par défaut) pour chaque trame de l'analyse où toutes les trames source se trouvent dans le passé. Pour scannet, ce serait data_splits/ScanNetv2/standard_split/test_eight_view_deepvmvs_dense.txt .offline : un tuple hors ligne pour chaque image clé pour chaque image clé de l'analyse.Pour les ensembles de train et de validation, nous suivons la même stratégie d'augmentation de tuple que dans DeepvideoMVS et utilisons le même script de génération de base.
Si vous souhaitez générer ces tuples vous-même, vous pouvez utiliser les scripts sur data_scripts/generate_train_tuples.py pour les tuples de train et data_scripts/generate_test_tuples.py pour tester les tuples. Ceux-ci suivent le même format de configuration que test.py et utiliseront la classe de jeu de données que vous créez pour lire Pose Informaiton.
Exemple de test:
# default tuples
python ./data_scripts/generate_test_tuples.py
--data_config configs/data/scannet_default_test.yaml
--num_workers 16
# dense tuples
python ./data_scripts/generate_test_tuples.py
--data_config configs/data/scannet_dense_test.yaml
--num_workers 16Exemples de train:
# train
python ./data_scripts/generate_train_tuples.py
--data_config configs/data/scannet_default_train.yaml
--num_workers 16
# val
python ./data_scripts/generate_val_tuples.py
--data_config configs/data/scannet_default_val.yaml
--num_workers 16 Ces scripts vérifieront d'abord chaque trame de l'ensemble de données pour s'assurer qu'il a une trame RVB existante, une trame de profondeur existante (le cas échéant pour l'ensemble de données), ainsi qu'un fichier de pose existant et valide. Il enregistrera ces valid_frames dans un fichier texte dans le dossier de chaque analyse, mais si le répertoire est uniquement lu, il ignorera l'enregistrement d'un fichier valid_frames et générera de toute façon des tuples.
Vous pouvez utiliser test.py pour déduire et évaluer les cartes de profondeur et les maillages de fusion.
Tous les résultats seront stockés dans un dossier de résultats de base (résultats_path) à:
opts.output_base_path/opts.name/opts.dataset/opts.frame_tuple_type/
où Opts est la classe options . Par exemple, lorsque opts.output_base_path est ./results , opts.name est HERO_MODEL , opts.dataset est scannet et opts.frame_tuple_type est default , le répertoire de sortie sera
./results/HERO_MODEL/scannet/default/
Assurez-vous de définir --opts.output_base_path à un répertoire qui vous convient pour stocker les résultats.
--frame_tuple_type est le type de tuple d'image utilisé pour les MV. Une sélection doit être fournie dans le fichier data_config que vous avez utilisé.
Par défaut, test.py tentera de calculer les scores de profondeur pour chaque trame et fournira à la fois des métriques moyennées par trame et en moyenne. Le script sauvera ces scores (par scène et totaux) sous results_path/scores .
Nous avons fait de notre mieux pour nous assurer qu'un bug de lots de torche dans le codeur correspondant est corrigé pour (<10 ^ -4) des tests précis en désactivant l'image par lots dans ce coder. Exécutez --batch_size 4 au plus en cas de doute, et si vous cherchez à devenir aussi stables que les nombres possibles et à éviter les gremlins pytorch, utilisez --batch_size 1 pour l'évaluation de comparaison.
Si vous souhaitez l'utiliser pour la vitesse, définissez --fast_cost_volume sur true. Cela permettra un lot via l'encodeur correspondant et permettra un volume de fonctions optimisé Einops.
# Example command to just compute scores
CUDA_VISIBLE_DEVICES=0 python test.py --name HERO_MODEL
--output_base_path OUTPUT_PATH
--config_file configs/models/hero_model.yaml
--load_weights_from_checkpoint weights/hero_model.ckpt
--data_config configs/data/scannet_default_test.yaml
--num_workers 8
--batch_size 4 ;
# If you'd like to get a super fast version use:
CUDA_VISIBLE_DEVICES=0 python test.py --name HERO_MODEL
--output_base_path OUTPUT_PATH
--config_file configs/models/hero_model.yaml
--load_weights_from_checkpoint weights/hero_model.ckpt
--data_config configs/data/scannet_default_test.yaml
--num_workers 8
--fast_cost_volume
--batch_size 2 ;Ce script peut également être utilisé pour effectuer quelques tâches auxiliaires différentes, notamment:
Fusion TSDF
Pour exécuter la fusion TSDF, fournissez l'indicateur --run_fusion . Vous avez deux choix pour les fusions
--depth_fuser ours (par défaut) utilisera notre fusion, dont les maillages sont utilisés dans la plupart des visualisations et pour les scores. Ce fusion ne prend pas en charge la couleur. Nous avons fourni une branche personnalisée de Scikit-Image avec notre implémentation personnalisée de measure.matching_cubes qui permet une paroi unique. Nous utilisons des maillages à parois à un seul pour évaluation. Si cela n'est pas important pour vous, vous pouvez définir le Export_Single_Mesh en False pour l'appel à export_mesh dans test.py--depth_fuser open3d utilisera le fusion de profondeur Open3D. Cette fusion prend en charge la couleur et vous pouvez l'activer en utilisant le drapeau --fuse_color . Par défaut, les cartes de profondeur seront coupées à 3M pour la fusion et une résolution TSDF de 0,04m 3 sera utilisée, mais vous pouvez changer cela en changeant les deux --max_fusion_depth et --fusion_resolution
Vous pouvez en option de demander des profondeurs prédites utilisées pour que la fusion soit masquée lorsqu'aucune information VAIID MVS n'existe en utilisant --mask_pred_depths . Ceci n'est pas activé par défaut.
Vous pouvez également fusionner les meilleures profondeurs de supposition du volume de coûts avant le codeur de volume de coûts-décodeur qui introduit une image forte avant. Vous pouvez le faire en utilisant --fusion_use_raw_lowest_cost .
Les maillages seront stockés dans results_path/meshes/ .
# Example command to fuse depths to get meshes
CUDA_VISIBLE_DEVICES=0 python test.py --name HERO_MODEL
--output_base_path OUTPUT_PATH
--config_file configs/models/hero_model.yaml
--load_weights_from_checkpoint weights/hero_model.ckpt
--data_config configs/data/scannet_default_test.yaml
--num_workers 8
--run_fusion
--batch_size 8 ;Profondeurs de cache
Vous pouvez éventuellement stocker des profondeurs en fournissant le drapeau --cache_depths . Ils seront stockés sur results_path/depths .
# Example command to compute scores and cache depths
CUDA_VISIBLE_DEVICES=0 python test.py --name HERO_MODEL
--output_base_path OUTPUT_PATH
--config_file configs/models/hero_model.yaml
--load_weights_from_checkpoint weights/hero_model.ckpt
--data_config configs/data/scannet_default_test.yaml
--num_workers 8
--cache_depths
--batch_size 8 ;
# Example command to fuse depths to get color meshes
CUDA_VISIBLE_DEVICES=0 python test.py --name HERO_MODEL
--output_base_path OUTPUT_PATH
--config_file configs/models/hero_model.yaml
--load_weights_from_checkpoint weights/hero_model.ckpt
--data_config configs/data/scannet_default_test.yaml
--num_workers 8
--run_fusion
--depth_fuser open3d
--fuse_color
--batch_size 4 ;Quick à savoir
Il existe d'autres scripts pour des visualisations plus profondes des profondeurs de sortie et de la fusion, mais pour l'exportation rapide de la visualisation de la carte de profondeur que vous pouvez utiliser --dump_depth_visualization . Les visualisations seront stockées sur results_path/viz/quick_viz/ .
# Example command to output quick depth visualizations
CUDA_VISIBLE_DEVICES=0 python test.py --name HERO_MODEL
--output_base_path OUTPUT_PATH
--config_file configs/models/hero_model.yaml
--load_weights_from_checkpoint weights/hero_model.ckpt
--data_config configs/data/scannet_default_test.yaml
--num_workers 8
--dump_depth_visualization
--batch_size 4 ; Nous autorisons également la fusion de nuages ponctuelles des cartes de profondeur en utilisant le fusion du dépôt de 3DVNET.
# Example command to fuse depths into point clouds.
CUDA_VISIBLE_DEVICES=0 python pc_fusion.py --name HERO_MODEL
--output_base_path OUTPUT_PATH
--config_file configs/models/hero_model.yaml
--load_weights_from_checkpoint weights/hero_model.ckpt
--data_config configs/data/scannet_dense_test.yaml
--num_workers 8
--batch_size 4 ; Modifiez configs/data/scannet_dense_test.yaml en configs/data/scannet_default_test.yaml pour utiliser les images clés uniquement si vous ne voulez pas attendre trop longtemps.
Nous utilisons l'évaluation du maillage de TransformorFusion pour notre tableau de résultats principal mais définissons la graine sur une valeur fixe pour la cohérence lors de l'échantillonnage au hasard. Nous rapportons également des mesures de maillage en utilisant l'évaluation de Neuralrecon dans le matériel supplémentaire.
Pour l'évaluation des nuages de points, nous utilisons le code de TransformerFusion mais chargeons dans un nuage de points à la place de l'échantillonnage de la surface d'un maillage.
Par défaut, les modèles et les fichiers d'événements Tensorboard sont enregistrés sur ~/tmp/tensorboard/<model_name> . Cela peut être modifié avec le drapeau --log_dir .
Nous nous entraînons avec un Batch_Size de 16 avec une précision 16 bits sur deux A100 sur la division ScanNetv2 par défaut.
Exemple de commande pour s'entraîner avec deux GPU:
CUDA_VISIBLE_DEVICES=0,1 python train.py --name HERO_MODEL
--log_dir logs
--config_file configs/models/hero_model.yaml
--data_config configs/data/scannet_default_train.yaml
--gpus 2
--batch_size 16 ; Le code prend en charge n'importe quel nombre de GPU pour la formation. Vous pouvez spécifier les GPU à utiliser avec l'environnement CUDA_VISIBLE_DEVICES .
Toutes nos courses de formation ont été effectuées sur deux NVIDIA A100.
Ensemble de données différents
Vous pouvez vous entraîner sur un ensemble de données MVS personnalisé en écrivant une nouvelle classe DatalOader qui hérite de GenericMVSDataset sur datasets/generic_mvs_dataset.py . Voir la classe ScannetDataset dans datasets/scannet_dataset.py ou même toute autre classe dans datasets pour un exemple.
Pour Finetune, chargez simple un point de contrôle (pas reprendre!) Et s'entraîner à partir de là:
CUDA_VISIBLE_DEVICES=0 python train.py --config configs/models/hero_model.yaml
--data_config configs/data/scannet_default_train.yaml
--load_weights_from_checkpoint weights/hero_model.ckptModifiez les configurations de données en n'importe quel ensemble de données vers lequel vous souhaitez FineTune.
Voir options.py pour la gamme d'autres options de formation, telles que les taux d'apprentissage et les paramètres d'ablation, et les options de test.
Outre une visualisation de profondeur rapide dans le script test.py , il existe deux scripts pour visualiser la sortie de profondeur.
Le premier est visualization_scripts/visualize_scene_depth_output.py . Cela produira une vidéo avec des images couleur des cadres de référence et de source, de la prédiction de la profondeur, de l'estimation du volume des coûts, de la profondeur GT et des normales estimées de la profondeur. Le script suppose que vous avez une sortie de profondeur en cache à l'aide de test.py et accepte le même format de modèle de commande que test.py :
# Example command to get visualizations for dense frames
CUDA_VISIBLE_DEVICES=0 python ./visualization_scripts/visualize_scene_depth_output.py --name HERO_MODEL
--output_base_path OUTPUT_PATH
--data_config configs/data/scannet_dense_test.yaml
--num_workers 8 ; où OUTPUT_PATH est le répertoire des résultats de base pour SimplereCon (ce que vous avez utilisé pour le test pour commencer). Vous pouvez éventuellement exécuter .visualization_scripts/generate_gt_min_max_cache.py avant ce script pour obtenir une moyenne de scène pour les valeurs de profondeur MIN et max utilisées pour Colormapping; Si ceux-ci ne sont pas disponibles, le script utilisera 0m et 5m pour Colomaping Min et Max.
Le second permet une visualisation en direct du maillage. Ce script utilisera des cartes de profondeur en cache si disponibles, sinon il utilisera le modèle pour les prédire avant la fusion. Le script se chargera de manière itérative dans une carte en profondeur, le fusionnera, enregistrera un fichier de maillage à cette étape et rendra ce maillage à côté d'un marqueur de caméra pour la vidéo Birdseye, et du point de vue de la caméra pour la vidéo FPV.
# Example command to get live visualizations for mesh reconstruction
CUDA_VISIBLE_DEVICES=0 python visualize_live_meshing.py --name HERO_MODEL
--output_base_path OUTPUT_PATH
--config_file configs/models/hero_model.yaml
--load_weights_from_checkpoint weights/hero_model.ckpt
--data_config configs/data/scannet_dense_test.yaml
--num_workers 8 ; Par défaut, le script enregistre les maillages dans un emplacement intermédiaire, et vous pouvez éventuellement charger ces maillages pour gagner du temps lors de la visualisation des mêmes maillages en passant à la réussite --use_precomputed_partial_meshes . Tous les mailles intermédiaires auront dû être calculées lors de l'exécution précédente pour que cela fonctionne.
Tl; dr: world_T_cam == world_from_cam
Ce repos utilise la notation "CAM_T_WORLD" pour désigner une transformation du monde en points de la caméra (extrinsics). L'intention est de faire en sorte que les noms de trame de coordonnées correspondent de chaque côté de la variable lorsqu'ils sont utilisés dans la multiplication de droite à gauche :
cam_points = cam_T_world @ world_points
world_T_cam désigne la pose de caméra (de la came aux coordonnées mondiales). ref_T_src désigne une transformation d'une source en vue de référence.
Enfin, cette notation permet de représenter à la fois des rotations et des traductions telles que: world_R_cam et world_t_cam
Ce repo est axé sur SCANNET, donc bien que ses fonctionnalités devraient permettre tout système de coordonnées (signalé via des drapeaux d'entrée), les poids du modèle que nous fournissons supposent un système de coordonnées de scanne. Ceci est important car nous incluons les informations RAY dans le cadre des métadonnées. D'autres ensembles de données utilisés avec ces poids doivent être transformés en système scanne. Les classes d'ensemble de données que nous incluons effectueront les transformations appropriées.
Il y a quelques bogues adressés dans cette mise à jour, vous devrez mettre à jour vos fourches et utiliser de nouveaux poids à partir de la table près du début de cette lecture. Vous devrez également vous assurer que les fichiers intrinsiques corrects extraits à l'aide du lecteur.
Merci à tous ceux qui l'ont souligné et qui étaient patients pendant que nous travaillions sur les correctifs.
Tous les scores s'améliorent avec ces correctifs, et les poids associés sont téléchargés ici. Pour les anciens scores, code et poids, vérifiez ce hachage de validation: 7DE5B451E340F9A11C7FD67BD0C42204D0B009A9
Des scores complets pour les modèles avec des corrections de bogues:
Profondeur
--config | ABS Diff ↓ | ABS Rel ↓ | SQ Rel ↓ | RMSE ↓ | journal RMSE ↓ | delta <1,05 ↑ | delta <1,10 ↑ |
|---|---|---|---|---|---|---|---|
hero_model.yaml , métadonnées + resnet | 0,0868 | 0,0428 | 0,0127 | 0.1472 | 0,0681 | 74.26 | 90.88 |
dot_product_model.yaml , produit dot + resnet | 0,0910 | 0,0453 | 0,0134 | 0.1509 | 0,0704 | 71.90 | 89,75 |
Fusion de maille
--config | ACC ↓ | Comp ↓ | Chanfrein ↓ | Rappel ↑ | Précision ↑ | F-score ↑ |
|---|---|---|---|---|---|---|
hero_model.yaml , métadonnées + resnet | 5.41 | 5.98 | 5.69 | 0,695 | 0,668 | 0,680 |
dot_product_model.yaml , produit dot + resnet | 5.66 | 6.18 | 5.92 | 0,682 | 0,655 | 0,667 |
Comparaison:
--config | Modèle | ABS Diff ↓ | SQ Rel ↓ | delta <1,05 ↑ | Chanfrein ↓ | F-score ↑ |
|---|---|---|---|---|---|---|
hero_model.yaml | Metadata + Resnet correspondant | 0,0868 | 0,0127 | 74.26 | 5.69 | 0,680 |
Old hero_model.yaml | Metadata + Resnet correspondant | 0,0885 | 0,0125 | 73.16 | 5.81 | 0,671 |
dot_product_model.yaml | DOT Product + Resnet correspondant | 0,0910 | 0,0134 | 71.90 | 5.92 | 0,667 |
Old dot_product_model.yaml | DOT Product + Resnet correspondant | 0,0941 | 0,0139 | 70,48 | 6.29 | 0,642 |
Initialement, ce repo a craché des fichiers Tuple pour les images clés de style DVMV par défaut avec 9 trame supplémentaires de 25599 pour le jeu de test SCANNETV2. Il y avait un bug mineur avec la manipulation du suivi perdu qui est maintenant corrigé. Ce repo devrait désormais imiter exactement le tampon de cadres clés DVMVS, avec des images clés 25590 pour les tests. Le seul effet que ce bogue a eu était l'inclusion de 9 images supplémentaires, tous les autres tuples étaient exactement les mêmes que celui des DVMV. Les cadres incriminés sont dans ces scans
scan previous count new count
--------------------------------------
scene0711_00 393 392
scene0727_00 209 208
scene0736_00 1023 1022
scene0737_00 408 407
scene0751_00 165 164
scene0775_00 220 219
scene0791_00 227 226
scene0794_00 141 140
scene0795_00 102 101
Les fichiers Tuple pour le test par défaut ont été mis à jour. Comme il s'agit d'une petite différence (~ 3E-4) dans les cadres supplémentaires marqués, les scores sont inchangés.
TL; DR: Échellez vos poses et recadrez vos images.
Nous fournissons un dataloader pour charger des images à partir d'une reconstruction clairsemée COLMAP. Pour que cela fonctionne avec SimplereCon, vous devrez recadrer vos images pour correspondre au FOV de Scannet (à peu près similaire au FOV d'un iPhone en mode vidéo), et à l'échelle de l'emplacement de votre pose en utilisant des mesures connues du monde réel. Si ces étapes ne sont pas prises, le volume des coûts ne sera pas construit correctement et le réseau n'estimera pas correctement la profondeur.
Nous remercions Aljaž Božič de TransformerFusion, Jiaming Sun of Neural Recon, et Arda Düzçeker de Deepvideomvs pour avoir fourni rapidement des informations utiles pour aider avec les lignes de base et pour rendre leurs bases de code facilement disponibles, en particulier dans un court délai.
Les scripts de génération de tuples utilisent lourds une version modifiée du tampon de transmission de DeepVideoMVS (merci encore Arda et Co!).
Le module Pytorch Point Cloud Fusion sur le code torch_point_cloud_fusion est emprunté au dépôt de 3DVNET. Merci Alexander Rich!
Nous tenons également à remercier l'équipe d'infrastructure de Niantic pour les actions rapides lorsque nous en avions besoin. Merci les gens!
Mohamed est financé par une bourse de doctorat Microsoft Research (MRL 2018-085).
Si vous trouvez notre travail utile dans vos recherches, veuillez envisager de citer notre article:
@inproceedings{sayed2022simplerecon,
title={SimpleRecon: 3D Reconstruction Without 3D Convolutions},
author={Sayed, Mohamed and Gibson, John and Watson, Jamie and Prisacariu, Victor and Firman, Michael and Godard, Cl{'e}ment},
booktitle={Proceedings of the European Conference on Computer Vision (ECCV)},
year={2022},
}
Copyright © Niantic, Inc. 2022. Patent en attente. Tous droits réservés. Veuillez consulter le fichier de licence pour les conditions.


