simplerecon
1.0.0
이것은 다음에 설명 된 방법을 사용하여 MVS 깊이 추정 모델 교육 및 테스트를위한 참조 pytorch 구현입니다.
Simplerecon : 3D 컨볼 루션이없는 3D 재구성
Mohamed Sayed, John Gibson, Jamie Watson, Victor Adrian Prisacariu, Michael Firman 및 Clément Godard
종이, ECCV 2022 (Arxiv PDF), 보충 자료, 프로젝트 페이지, 비디오
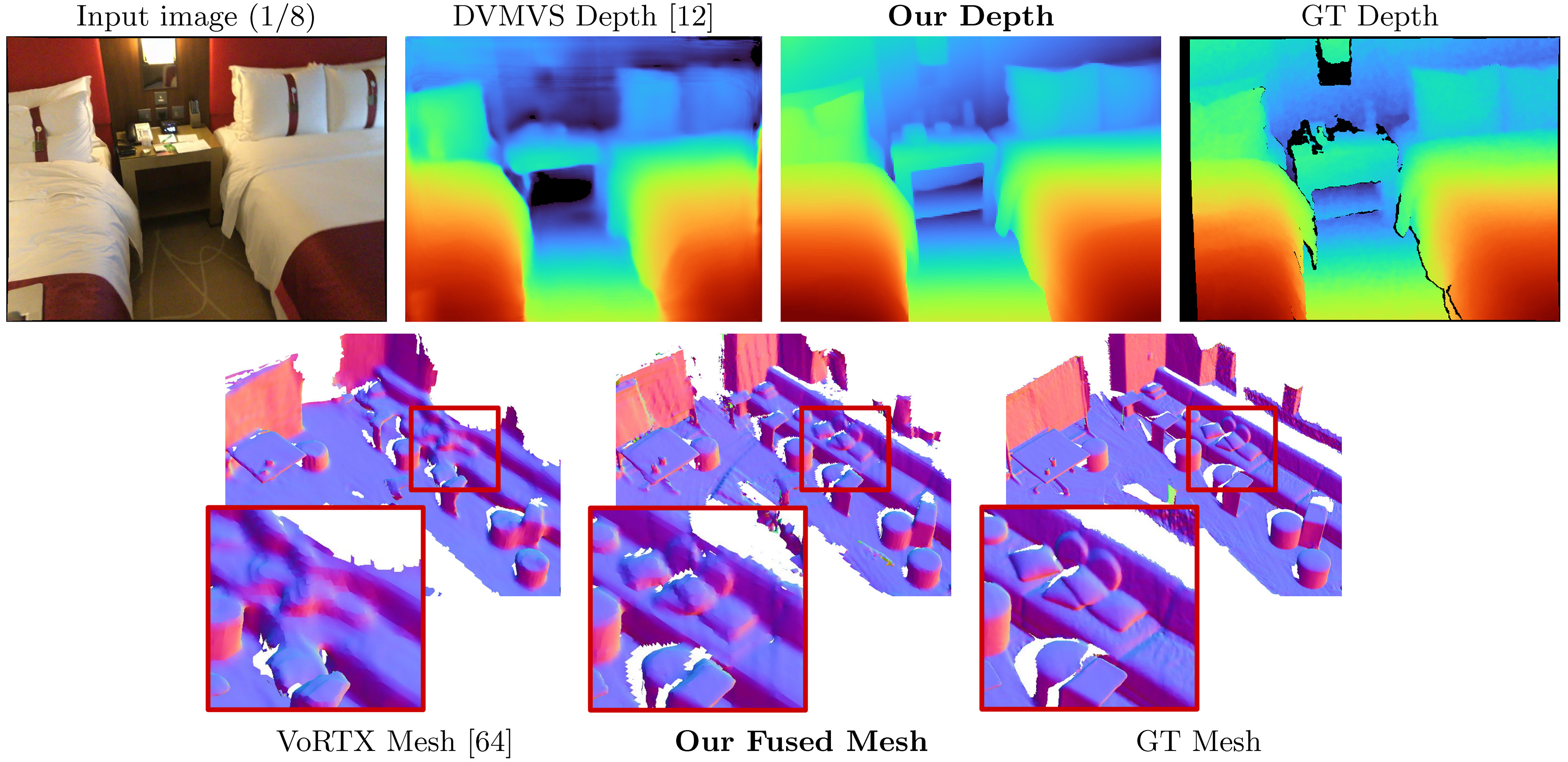
이 코드는 비상업적 사용을위한 것입니다. 용어는 라이센스 파일을 참조하십시오. 이 코드베이스의 일부가 도움이되면 아래의 Bibtex를 사용하여 논문을 인용 하고이 리베르를 연결하십시오. 감사해요!
25/05/2023 : llvm-openmp , clang 및 protobuf 대한 고정 패키지 정리. 코드를 실행하는 데 문제가 있거나 데이터 로딩이 단일 스레드로 제한되는 경우이 새로운 환경 파일을 사용하십시오.
09/03/2023 : Kornia 타이핑 문제를 해결하기 위해 환경 파일에 Kornia 버전을 추가했습니다. (감사합니다 @natesimon!)
26/01/2023 : 라이센스는 학문적 이유로 모델을 실행하기 위해 수정되었습니다. 정확한 세부 정보는 라이센스 파일을 보내주십시오.
20022 년 12 월 31 일 기준으로 약간 잘못된 내입, 비용 부피의 플립 확대 및 프로젝션의 수치 정밀 버그를 고정시키는 업데이트가 있습니다. 모든 점수가 향상됩니다. 포크를 업데이트하고 새로운 가중치를 사용해야합니다. 버그 수정을 참조하십시오.
온라인 기본 프레임에 대한 사전 계산 스캔은 다음과 같습니다. https://drive.google.com/drive/folders/1dsofi9gayyhqjsx4i_ng0-3ebcafwxjv?usp=share_link
Simplerecon은 입력 포즈 RGB 이미지로 가져 가고 대상 이미지의 깊이 맵을 출력합니다.
새로운 아나콘다 분포를 가정하면 다음과 함께 종속성을 설치할 수 있습니다.
conda env create -f simplerecon_env.yml우리는 Pytorch 1.10, Cuda 11.3, Python 3.9.7 및 Debian GNU/Linux 10을 사용하여 실험을했습니다.
사전에 사전 된 모델을 weights/ 폴더로 다운로드하십시오.
우리는 다음 모델을 제공합니다 (점수는 온라인 기본 키 프레임으로) :
--config | 모델 | ABS diff ↓ | SQ Rel ↓ | 델타 <1.05 ↑ | 모 틸트 ↓ | F- 점수 ↑ |
|---|---|---|---|---|---|---|
hero_model.yaml | 메타 데이터 + RESNET 매칭 | 0.0868 | 0.0127 | 74.26 | 5.69 | 0.680 |
dot_product_model.yaml | 도트 제품 + RESNET 매칭 | 0.0910 | 0.0134 | 71.90 | 5.92 | 0.667 |
hero_model 우리 가 논문에서 사용하는 것입니다.
--config | 모델 | 추론 속도 ( --batch_size 1 ) | 추론 GPU 메모리 | 대략적인 교육 시간 |
|---|---|---|---|---|
hero_model | 영웅, 메타 데이터 + resnet | 130ms / 70ms (속도 최적화) | 2.6GB / 5.7GB (속도 최적화) | 36 시간 |
dot_product_model | 도트 제품 + resnet | 80ms | 2.6GB | 36 시간 |
배치가 클수록 속도가 상당히 증가합니다. 비 속도 최적화 모델에서 배치 크기 8을 사용하면 대기 시간이 ~ 40ms로 떨어집니다.
datasets/arkit_dataset.py 에 있습니다. 업데이트 : 이제 Data_Scripts/iOS_LOGGER_PREPROCESSING.PY에서 스크립트를 사용하여 iOS-Logger 스캔을 처리하고 실행하는 방법에 대한 빠른 README data_scripts/ios_logger_preprocessing.py 가 있습니다. 우리는 이제 사람들이 코드를 사용하여 즉시 시도 할 수있는 두 가지 스캔을 포함 시켰습니다. 여기 에서이 스캔을 다운로드 할 수 있습니다.
단계 :
hero_model 의 가중치를 가중치 디렉토리로 다운로드하십시오.configs/data/vdr_dense.yaml 에서 옵션 dataset_path 의 값을 압축 된 vdr 폴더의 기본 경로로 수정하십시오.CUDA_VISIBLE_DEVICES=0 python test.py --name HERO_MODEL
--output_base_path OUTPUT_PATH
--config_file configs/models/hero_model.yaml
--load_weights_from_checkpoint weights/hero_model.ckpt
--data_config configs/data/vdr_dense.yaml
--num_workers 8
--batch_size 2
--fast_cost_volume
--run_fusion
--depth_fuser open3d
--fuse_color
--dump_depth_visualization ; 이것은 OUTPUT_PATH 에서 Lidar 깊이에 대해 벤치마킹 될 때 메시, 빠른 깊이, 즉, 소크라스를 출력합니다.
이 명령은 vdr_dense.yaml 사용하여 모든 프레임에 대한 깊이를 생성하고 메쉬에 융합합니다. 논문에서 우리는 대신 융합 키 프레임으로 점수를보고하고 vdr_default.yaml 사용하여 실행할 수 있습니다. 대신 vdr_dense_offline.yaml 사용하여 dense_offline 튜플을 사용할 수도 있습니다.
테스트 및 평가에 대한 아래 섹션을 참조하십시오. 데이터 세트에 올바른 구성 플래그를 사용하십시오.
여기에 지침을 따라 데이터 세트를 다운로드하십시오. 이 데이터 세트는 상당히 큽니다 (> 2TB). 특히 파일을 추출하기에 충분한 공간이 있는지 확인하십시오.
다운로드되면이 스크립트를 사용하여 원시 센서 데이터를 이미지 및 깊이 파일로 내보내십시오.
우리는 빠른 튜토리얼을 작성했으며 Scannetv2 다운로드 및 추출에 도움이되는 수정 된 스크립트를 포함 시켰습니다. data_scripts/scannet_wrangling_scripts/에서 찾을 수 있습니다.
configs/data/ 에서 scannetv2 데이터 구성에 대한 dataset_path config 인수를 변경해야합니다.
CodeBase는 Scannetv2가 다음 형식이 될 것으로 기대합니다.
dataset_path
scans_test (test scans)
scene0707
scene0707_00_vh_clean_2.ply (gt mesh)
sensor_data
frame-000261.pose.txt
frame-000261.color.jpg
frame-000261.color.512.png (optional, image at 512x384)
frame-000261.color.640.png (optional, image at 640x480)
frame-000261.depth.png (full res depth, stored scale *1000)
frame-000261.depth.256.png (optional, depth at 256x192 also
scaled)
scene0707.txt (scan metadata and image sizes)
intrinsic
intrinsic_depth.txt
intrinsic_color.txt
...
scans (val and train scans)
scene0000_00
(see above)
scene0000_01
....
이 예에서는 scene0707.txt 스캔의 메타 데이터를 포함해야합니다.
colorHeight = 968
colorToDepthExtrinsics = 0.999263 -0.010031 0.037048 ........
colorWidth = 1296
depthHeight = 480
depthWidth = 640
fx_color = 1170.187988
fx_depth = 570.924255
fy_color = 1170.187988
fy_depth = 570.924316
mx_color = 647.750000
mx_depth = 319.500000
my_color = 483.750000
my_depth = 239.500000
numColorFrames = 784
numDepthFrames = 784
numIMUmeasurements = 1632
frame-000261.pose.txt 양식으로 포즈를 포함해야합니다.
-0.384739 0.271466 -0.882203 4.98152
0.921157 0.0521417 -0.385682 1.46821
-0.0587002 -0.961035 -0.270124 1.51837
frame-000261.color.512.png 및 frame-000261.color.640.png 는 훈련 및 테스트 중에로드 및 시간을 절약하기 위해 원본 이미지의 크기가 크기가 큰 버전입니다. frame-000261.depth.256.png 는 깊이 맵의 선행 된 해상 버전입니다.
깊이와 이미지의 모든 크기가 크기가 좋은 버전은 사용하기에 좋지만 필요하지는 않습니다. 존재하지 않으면 전체 해상도 버전이로드되고 즉시 다운 샘플링됩니다.
기본적으로 스캔에서 각 키 프레임에 대한 깊이 맵을 추정합니다. 우리는 키 프레임 분리에 DeepVideomvs의 휴리스틱을 사용하고 일치하는 튜플을 구성합니다. 깊이 융합을 위해이 키 프레임의 깊이 맵을 사용합니다. 각 키 프레임에 대해 비용 볼륨을 구축하는 데 사용될 소스 프레임 목록을 연관시킵니다. 우리는 또한 밀도가 높은 튜플을 사용합니다. 여기서 특정 키 프레임뿐만 아니라 데이터의 각 프레임에 대한 깊이 맵을 예측합니다. 이것들은 주로 시각화에 사용됩니다.
우리는 데이터 세트의 요소 역할을하는 모든 스캔에서 튜플 목록을 생성하고 내 보냅니다. 우리는이 목록을 사전 계산했으며 각 데이터 세트 분할의 data_splits 에서 사용할 수 있습니다. Scannet의 테스트 스캔의 경우 data_splits/ScanNetv2/standard_split 에 있습니다. 우리의 핵심 깊이 번호는 data_splits/ScanNetv2/standard_split/test_eight_view_deepvmvs.txt 사용하여 계산됩니다.
다음은 테스트를위한 튜플 유형에 대한 빠른 분류입니다.
default : 모든 소스 프레임이 과거에있는 DeepVideOMVS에 따른 모든 키 프레임에 대한 튜플. 달리 명시되지 않는 한 모든 깊이 및 메쉬 평가에 사용됩니다. Scannet의 경우 data_splits/ScanNetv2/standard_split/test_eight_view_deepvmvs.txt 사용하십시오.offline : 현재 프레임에 비해 소스 프레임이 과거와 미래에 모두 소스 프레임이 될 수있는 스캔의 모든 프레임에 대한 튜플. 장면이 오프라인으로 캡처 될 때 유용하며 최상의 정확도를 원합니다. 온라인 튜플을 사용하면 카메라가 멀어지고 모든 소스 프레임이 뒤처짐에 따라 비용 부피에는 빈 영역이 포함됩니다. 그러나 오프라인 튜플을 사용하면 비용량이 양쪽 끝에 가득 차서 더 나은 규모 (및 메트릭) 추정치로 이어집니다.dense : 모든 소스 프레임이 과거에있는 스캔의 모든 프레임에 대한 온라인 튜플 (기본값). SCANNET의 경우 data_splits/ScanNetv2/standard_split/test_eight_view_deepvmvs_dense.txt 입니다.offline : 스캔의 모든 키 프레임에 대한 모든 키 프레임에 대한 오프라인 튜플.기차 및 검증 세트의 경우 DeepvideOMVS와 동일한 튜플 증강 전략을 따르고 동일한 핵심 생성 스크립트를 사용합니다.
이 튜플을 직접 생성하려면 data_scripts/generate_train_tuples.py 에서 스크립트를 기차 튜플 및 data_scripts/generate_test_tuples.py 에 사용할 수 있습니다. 이들은 test.py 와 동일한 구성 형식을 따르며 작성하여 Posse Informaiton을 읽기 위해 작성하는 모든 데이터 세트 클래스를 사용합니다.
시험 예 :
# default tuples
python ./data_scripts/generate_test_tuples.py
--data_config configs/data/scannet_default_test.yaml
--num_workers 16
# dense tuples
python ./data_scripts/generate_test_tuples.py
--data_config configs/data/scannet_dense_test.yaml
--num_workers 16기차 예 :
# train
python ./data_scripts/generate_train_tuples.py
--data_config configs/data/scannet_default_train.yaml
--num_workers 16
# val
python ./data_scripts/generate_val_tuples.py
--data_config configs/data/scannet_default_val.yaml
--num_workers 16 이 스크립트는 먼저 데이터 세트의 각 프레임을 확인하여 기존 RGB 프레임, 기존 깊이 프레임 (데이터 세트에 적합한 경우) 및 기존 및 유효한 포즈 파일이 있는지 확인합니다. 이 valid_frames 각 스캔 폴더의 텍스트 파일에 저장되지만 디렉토리를 읽으면 valid_frames 파일 저장을 무시하고 어쨌든 튜플을 생성합니다.
깊이 맵을 추론하고 평가하기 위해 test.py 사용할 수 있습니다.
모든 결과는 기본 결과 폴더 (results_path)에 저장됩니다.
opts.output_base_path/opts.name/opts.dataset/opts.frame_tuple_type/
Opts는 options 클래스입니다. 예를 들어, opts.output_base_path 가 ./results , opts.name 은 HERO_MODEL , opts.dataset 은 scannet 이고 opts.frame_tuple_type 가 default 되면 출력 디렉토리는 다음과 같습니다.
./results/HERO_MODEL/scannet/default/
결과를 저장하기에 적합한 디렉토리로 --opts.output_base_path 설정하십시오.
--frame_tuple_type 는 MVS에 사용되는 이미지 튜플 유형입니다. 사용한 data_config 파일에 선택을 제공해야합니다.
기본적으로 test.py 각 프레임의 깊이 점수를 계산하려고 시도하고 프레임 평균 및 장면 평균 메트릭을 모두 제공합니다. 스크립트는이 점수 (장면 및 총계 당)를 results_path/scores 에서 저장합니다.
우리는 일치하는 인코더를 통한 토치 배치 버그가 해당 인코더를 통해 이미지 배치를 비활성화하여 정확한 테스트를 위해 고정되도록 최선을 다했습니다. 의심스러운 경우 최대 --batch_size 4 최대로, 가능한 숫자만큼 안정된 숫자를 얻고 pytorch gremlins를 피하려면 비교 평가를 위해 --batch_size 1 사용하십시오.
속도에 이것을 사용하려면 --fast_cost_volume true로 설정하십시오. 이렇게하면 일치하는 인코더를 통한 배치가 가능하며 Einops 최적화 기능 볼륨이 가능합니다.
# Example command to just compute scores
CUDA_VISIBLE_DEVICES=0 python test.py --name HERO_MODEL
--output_base_path OUTPUT_PATH
--config_file configs/models/hero_model.yaml
--load_weights_from_checkpoint weights/hero_model.ckpt
--data_config configs/data/scannet_default_test.yaml
--num_workers 8
--batch_size 4 ;
# If you'd like to get a super fast version use:
CUDA_VISIBLE_DEVICES=0 python test.py --name HERO_MODEL
--output_base_path OUTPUT_PATH
--config_file configs/models/hero_model.yaml
--load_weights_from_checkpoint weights/hero_model.ckpt
--data_config configs/data/scannet_default_test.yaml
--num_workers 8
--fast_cost_volume
--batch_size 2 ;이 스크립트는 다음을 포함하여 몇 가지 다른 보조 작업을 수행하는 데 사용될 수도 있습니다.
TSDF 퓨전
tsdf fusion을 실행하려면 --run_fusion 플래그를 제공합니다. 퓨저를위한 두 가지 선택이 있습니다
--depth_fuser ours (기본값)는 대부분의 시각화 및 점수에 메시가 사용되는 퓨저를 사용합니다. 이 퓨저는 색상을 지원하지 않습니다. 우리는 Scikit-Image의 사용자 정의 지점에 measure.matching_cubes 의 맞춤형 구현을 제공했습니다. 우리는 평가를 위해 단일 벽 메쉬를 사용합니다. 이것이 중요하지 않은 경우 test.py 에서 export_mesh 호출하기 위해 Export_single_mesh를 False 로 설정할 수 있습니다.--depth_fuser open3d Open3D 깊이 퓨저를 사용합니다. 이 퓨저는 색상을 지원하며 --fuse_color 플래그를 사용하여이를 활성화 할 수 있습니다. 기본적으로 퓨전의 경우 깊이 맵이 3m에 클립되고 0.04m 3 의 TSDF 해상도가 사용되지만 --max_fusion_depth 및 --fusion_resolution 모두 변경하여 변경할 수 있습니다.
vaiid mvs 정보가 --mask_pred_depths 사용하지 않을 때 융합에 사용되는 예측 된 깊이를 선택적으로 요청할 수 있습니다. 기본적으로 활성화되지 않습니다.
또한 이전에 강한 이미지를 도입하는 비용 기록 인코더 디코더 앞에서 비용 볼륨에서 최고의 추측 깊이를 융합시킬 수도 있습니다. --fusion_use_raw_lowest_cost 사용 하여이 작업을 수행 할 수 있습니다.
메시는 results_path/meshes/ 에 저장됩니다.
# Example command to fuse depths to get meshes
CUDA_VISIBLE_DEVICES=0 python test.py --name HERO_MODEL
--output_base_path OUTPUT_PATH
--config_file configs/models/hero_model.yaml
--load_weights_from_checkpoint weights/hero_model.ckpt
--data_config configs/data/scannet_default_test.yaml
--num_workers 8
--run_fusion
--batch_size 8 ;캐시 깊이
--cache_depths 플래그를 제공하여 선택적으로 깊이를 저장할 수 있습니다. results_path/depths 에 저장됩니다.
# Example command to compute scores and cache depths
CUDA_VISIBLE_DEVICES=0 python test.py --name HERO_MODEL
--output_base_path OUTPUT_PATH
--config_file configs/models/hero_model.yaml
--load_weights_from_checkpoint weights/hero_model.ckpt
--data_config configs/data/scannet_default_test.yaml
--num_workers 8
--cache_depths
--batch_size 8 ;
# Example command to fuse depths to get color meshes
CUDA_VISIBLE_DEVICES=0 python test.py --name HERO_MODEL
--output_base_path OUTPUT_PATH
--config_file configs/models/hero_model.yaml
--load_weights_from_checkpoint weights/hero_model.ckpt
--data_config configs/data/scannet_default_test.yaml
--num_workers 8
--run_fusion
--depth_fuser open3d
--fuse_color
--batch_size 4 ;빠른 viz
출력 깊이와 융합의 더 깊은 시각화를위한 다른 스크립트가 있지만 깊이 맵 시각화를 빠르게 내보내기 위해서는 --dump_depth_visualization 사용할 수 있습니다. 시각화는 results_path/viz/quick_viz/ 에 저장됩니다.
# Example command to output quick depth visualizations
CUDA_VISIBLE_DEVICES=0 python test.py --name HERO_MODEL
--output_base_path OUTPUT_PATH
--config_file configs/models/hero_model.yaml
--load_weights_from_checkpoint weights/hero_model.ckpt
--data_config configs/data/scannet_default_test.yaml
--num_workers 8
--dump_depth_visualization
--batch_size 4 ; 또한 3DVNet의 repo의 퓨저를 사용하여 깊이 맵의 포인트 클라우드 퓨전을 허용합니다.
# Example command to fuse depths into point clouds.
CUDA_VISIBLE_DEVICES=0 python pc_fusion.py --name HERO_MODEL
--output_base_path OUTPUT_PATH
--config_file configs/models/hero_model.yaml
--load_weights_from_checkpoint weights/hero_model.ckpt
--data_config configs/data/scannet_dense_test.yaml
--num_workers 8
--batch_size 4 ; configs/data/scannet_dense_test.yaml configs/data/scannet_default_test.yaml 로 변경하여 너무 오래 기다리지 않는 경우에만 키 프레임을 사용하십시오.
우리는 메인 결과 테이블에 대한 TransformerFusion의 메쉬 평가를 사용하지만 무작위로 메쉬를 샘플링 할 때 일관성을 위해 시드를 고정 값으로 설정합니다. 또한 보충 자료에서 Neuralrecon의 평가를 사용하여 메쉬 메트릭을보고합니다.
포인트 클라우드 평가를 위해 변압기 퓨전 코드를 사용하지만 메쉬 표면을 샘플링 할 대신 포인트 클라우드에로드합니다.
기본적으로 모델과 Tensorboard 이벤트 파일은 ~/tmp/tensorboard/<model_name> 에 저장됩니다. --log_dir 플래그로 변경할 수 있습니다.
우리는 기본 Scannetv2 분할에서 2 개의 A100에서 16 비트 정밀도로 16의 Batch_size로 훈련합니다.
예제 명령 명령 두 개의 GPU로 훈련하십시오.
CUDA_VISIBLE_DEVICES=0,1 python train.py --name HERO_MODEL
--log_dir logs
--config_file configs/models/hero_model.yaml
--data_config configs/data/scannet_default_train.yaml
--gpus 2
--batch_size 16 ; 이 코드는 교육을 위해 모든 GPU를 지원합니다. CUDA_VISIBLE_DEVICES 환경에서 사용할 GPU를 지정할 수 있습니다.
우리의 모든 훈련 실행은 두 개의 Nvidia A100에서 수행되었습니다.
다른 데이터 세트
datasets/generic_mvs_dataset.py 에서 GenericMVSDataset 에서 상속되는 새 데이터 로더 클래스를 작성하여 사용자 정의 MVS 데이터 세트를 교육 할 수 있습니다. datasets/scannet_dataset.py 의 ScannetDataset 클래스 또는 실제로 datasets 의 다른 클래스를 참조하십시오.
미세한 경우, 단순한 체크 포인트 (이력서가 아님)를 간단하게로드하고 거기에서 훈련하십시오.
CUDA_VISIBLE_DEVICES=0 python train.py --config configs/models/hero_model.yaml
--data_config configs/data/scannet_default_train.yaml
--load_weights_from_checkpoint weights/hero_model.ckpt데이터 구성을 변경하려는 데이터 세트로 변경하십시오.
학습 속도 및 절제 설정 및 테스트 옵션과 같은 다른 교육 옵션 범위는 options.py 참조하십시오.
test.py 스크립트의 빠른 깊이 시각화 외에 깊이 출력 시각화를위한 두 개의 스크립트가 있습니다.
첫 번째는 visualization_scripts/visualize_scene_depth_output.py 입니다. 이렇게하면 참조 및 소스 프레임의 컬러 이미지, 깊이 예측, 비용 볼륨 추정치, GT 깊이 및 깊이에서 추정 된 정상이 포함 된 비디오가 생성됩니다. 스크립트는 test.py 사용하여 캐시 된 깊이 출력이 있다고 가정하고 test.py 와 동일한 명령 템플릿 형식을 수락합니다.
# Example command to get visualizations for dense frames
CUDA_VISIBLE_DEVICES=0 python ./visualization_scripts/visualize_scene_depth_output.py --name HERO_MODEL
--output_base_path OUTPUT_PATH
--data_config configs/data/scannet_dense_test.yaml
--num_workers 8 ; 여기서 OUTPUT_PATH Simplerecon의 기본 결과 디렉토리입니다 (테스트를 시작하기 위해 사용한 것). 이 스크립트 전에 .visualization_scripts/generate_gt_min_max_cache.py 선택적으로 실행할 수 있습니다. 사용할 수없는 경우 스크립트는 Colompapping Min 및 Max에 0m 및 5m를 사용합니다.
두 번째는 메시를 실시간 시각화 할 수 있습니다. 이 스크립트는 사용 가능한 경우 캐시 된 깊이 맵을 사용합니다. 그렇지 않으면 모델을 사용하여 퓨전 전에 예측합니다. 스크립트는 깊이 맵에 반복적으로로드하고, 퓨즈를 융합시키고,이 단계에서 메쉬 파일을 저장 한 다음, Birdseye 비디오의 카메라 마커와 FPV 비디오의 카메라 관점 에서이 메쉬를 렌더링합니다.
# Example command to get live visualizations for mesh reconstruction
CUDA_VISIBLE_DEVICES=0 python visualize_live_meshing.py --name HERO_MODEL
--output_base_path OUTPUT_PATH
--config_file configs/models/hero_model.yaml
--load_weights_from_checkpoint weights/hero_model.ckpt
--data_config configs/data/scannet_dense_test.yaml
--num_workers 8 ; 기본적으로 스크립트는 메시를 중간 위치에 저장하고 선택적으로 해당 메시를로드하여 --use_precomputed_partial_meshes 전달하여 동일한 메시를 다시 시각화 할 때 시간을 절약 할 수 있습니다. 모든 중간 메시는 이전 달리기에서 계산해야했습니다.
tl; dr : world_T_cam == world_from_cam
이 repo는 "CAM_T_WORLD"표기법을 사용하여 세계에서 카메라 포인트 (Extrinsics)로 변환을 나타냅니다. 의도는 좌표 프레임 이름이 오른쪽에서 왼쪽으로 곱하는 데 사용될 때 변수의 양쪽에 일치하도록하는 것입니다.
cam_points = cam_T_world @ world_points
world_T_cam 카메라 포즈 (캠에서 월드 코디로)를 나타냅니다. ref_T_src 소스에서 참조 뷰로 변환을 나타냅니다.
마지막 으로이 표기법은 다음과 같은 회전과 번역을 모두 표현할 수 있습니다. world_R_cam 및 world_t_cam
이 repo는 스캐넷을 대상으로하기 때문에 기능은 모든 좌표계 (입력 플래그를 통해 신호)를 허용해야하지만, 우리가 제공하는 모델 가중치는 스캐넷 좌표계를 가정합니다. 메타 데이터의 일부로 Ray 정보를 포함하므로 이것은 중요합니다. 이러한 가중치와 함께 사용되는 다른 데이터 세트는 스캐넷 시스템으로 변환해야합니다. 우리가 포함하는 데이터 세트 클래스는 적절한 변환을 수행합니다.
이 업데이트에는 몇 가지 버그가 해결되므로 포크를 업데이트 하고이 readme의 시작 부분 근처 테이블에서 새로운 가중치를 사용해야합니다. 또한 독자를 사용하여 올바른 고유 파일을 추출했는지 확인해야합니다.
우리가 수정 작업을하는 동안 그것을 지적하고 인내심을 가진 모든 분들께 감사드립니다.
이러한 수정 사항으로 모든 점수가 향상되며 관련 가중치는 여기에 업로드됩니다. 이전 점수, 코드 및 가중치의 경우이 커밋 해시를 확인하십시오. 7DE5B451E340F9A11C7FD67BD0C42204D0B009A9
버그 수정이있는 모델의 전체 점수 :
깊이
--config | ABS diff ↓ | ABS Rel ↓ | SQ Rel ↓ | RMSE ↓ | 로그 rmse ↓ | 델타 <1.05 ↑ | 델타 <1.10 ↑ |
|---|---|---|---|---|---|---|---|
hero_model.yaml , 메타 데이터 + resnet | 0.0868 | 0.0428 | 0.0127 | 0.1472 | 0.0681 | 74.26 | 90.88 |
dot_product_model.yaml , dot product + resnet | 0.0910 | 0.0453 | 0.0134 | 0.1509 | 0.0704 | 71.90 | 89.75 |
메쉬 퓨전
--config | ACC ↓ | comp ↓ | 모 틸트 ↓ | 리콜 ↑ | 정밀도 ↑ | F- 점수 ↑ |
|---|---|---|---|---|---|---|
hero_model.yaml , 메타 데이터 + resnet | 5.41 | 5.98 | 5.69 | 0.695 | 0.668 | 0.680 |
dot_product_model.yaml , dot product + resnet | 5.66 | 6.18 | 5.92 | 0.682 | 0.655 | 0.667 |
비교:
--config | 모델 | ABS diff ↓ | SQ Rel ↓ | 델타 <1.05 ↑ | 모 틸트 ↓ | F- 점수 ↑ |
|---|---|---|---|---|---|---|
hero_model.yaml | 메타 데이터 + RESNET 매칭 | 0.0868 | 0.0127 | 74.26 | 5.69 | 0.680 |
Old hero_model.yaml | 메타 데이터 + RESNET 매칭 | 0.0885 | 0.0125 | 73.16 | 5.81 | 0.671 |
dot_product_model.yaml | 도트 제품 + RESNET 매칭 | 0.0910 | 0.0134 | 71.90 | 5.92 | 0.667 |
Old dot_product_model.yaml | 도트 제품 + RESNET 매칭 | 0.0941 | 0.0139 | 70.48 | 6.29 | 0.642 |
처음 에이 repo는 기본 DVMVS 스타일 키 프레임에 대한 튜플 파일을 ScannetV2 테스트 세트에 25599로 25599입니다. 현재 고정 된 추적 손실을 처리하는 사소한 버그가있었습니다. 이 repo는 이제 25590 키 프레임으로 DVMVS 키 프레임 버퍼를 정확하게 모방해야합니다. 이 버그가 가진 유일한 효과는 9 개의 추가 프레임을 포함시키는 것이며, 다른 모든 튜플은 DVMV와 정확히 동일했습니다. 불쾌한 프레임은 이러한 스캔에 있습니다
scan previous count new count
--------------------------------------
scene0711_00 393 392
scene0727_00 209 208
scene0736_00 1023 1022
scene0737_00 408 407
scene0751_00 165 164
scene0775_00 220 219
scene0791_00 227 226
scene0794_00 141 140
scene0795_00 102 101
기본 테스트를위한 튜플 파일이 업데이트되었습니다. 이것은 추가 프레임의 작은 (~ 3e-4) 차이이므로 점수는 변경되지 않습니다.
TL; DR : 포즈를 확장하고 이미지를 자르십시오.
COLMAP 스파 스 재구성에서 이미지를로드하기위한 데이터 로더를 제공합니다. 이것이 Simplerecon과 함께 작동하려면 스캐넷의 FOV (비디오 모드에서 iPhone의 FOV와 거의 유사 함)와 함께 이미지를 자르고 알려진 실제 측정을 사용하여 포즈 위치를 확장해야합니다. 이러한 단계를 수행하지 않으면 비용 볼륨이 올바르게 구축되지 않으며 네트워크는 깊이를 올바르게 추정하지 않습니다.
우리는 변압기 퓨전의 Aljaž Božič, 신경 정찰의 Jiaming Sun 및 Deepvideomvs의 Arda Düzçeker에게 기준선에 도움이되는 유용한 정보를 신속하게 제공하고 특히 짧은 통지로 코드베이스를 쉽게 이용할 수 있도록 감사합니다.
튜플 생성 스크립트는 DeepVideOMVS의 키 프레임 버퍼의 수정 된 버전을 크게 사용합니다 (다시 Arda and Co!).
torch_point_cloud_fusion 코드의 Pytorch Point Cloud Fusion 모듈은 3DVNet의 Repo에서 차용됩니다. 알렉산더 리치 감사합니다!
우리는 또한 Niantic의 인프라 팀에게 필요할 때 빠른 조치에 감사드립니다. 감사합니다.
Mohamed는 Microsoft Research PhD Scholarship (MRL 2018-085)에 의해 자금을 지원받습니다.
귀하의 연구에서 우리의 작업이 유용하다는 것을 알게되면 우리의 논문을 인용하는 것을 고려하십시오.
@inproceedings{sayed2022simplerecon,
title={SimpleRecon: 3D Reconstruction Without 3D Convolutions},
author={Sayed, Mohamed and Gibson, John and Watson, Jamie and Prisacariu, Victor and Firman, Michael and Godard, Cl{'e}ment},
booktitle={Proceedings of the European Conference on Computer Vision (ECCV)},
year={2022},
}
Copyright © Niantic, Inc. 2022. 특허 출원 중. 모든 권리 보유. 용어는 라이센스 파일을 참조하십시오.


