simplerecon
1.0.0
Esta es la implementación de Pytorch de referencia para capacitar y probar modelos de estimación de profundidad de MVS utilizando el método descrito en
SimpleRecon: Reconstrucción 3D sin convoluciones 3D
Mohamed Sayed, John Gibson, Jamie Watson, Victor Adrian Prisacariu, Michael Firman y Clément Godard
Paper, ECCV 2022 (ARXIV PDF), material suplementario, página del proyecto, video
Este código es para uso no comercial; Consulte el archivo de licencia para los términos. Si encuentra útil alguna parte de esta base de código, cita nuestro documento con el bibtex a continuación y vincule este repositorio. ¡Gracias!
25/05/2023: Veriones de paquete fijas para llvm-openmp , clang y protobuf . Use este nuevo archivo de entorno si tiene problemas para ejecutar el código y/o si DataLoading se limita a un solo hilo.
03/09/2023: Se agregó la versión de Kornia al archivo de entornos para solucionar el problema de escritura de Kornia. (¡Gracias @natesimon!)
26/01/2023: La licencia se ha modificado para facilitar la ejecución del modelo por razones académicas. Por favor, el archivo de licencia para los detalles exactos.
Hay una actualización a partir del 31/12/2022 que corrige intrínsecs ligeramente incorrectos, el aumento de la voltea para el volumen de costos y un error de precisión numérica en la proyección. Todos los puntajes mejoran. Deberá actualizar sus horquillas y usar nuevos pesos. Ver correcciones de errores.
Los escaneos precomputados para los marcos predeterminados en línea están aquí: https://drive.google.com/drive/folders/1DSOFI9GAYYHQJSX4I_NG0-3EBCAFWXJV?USP=SHARE_LINK
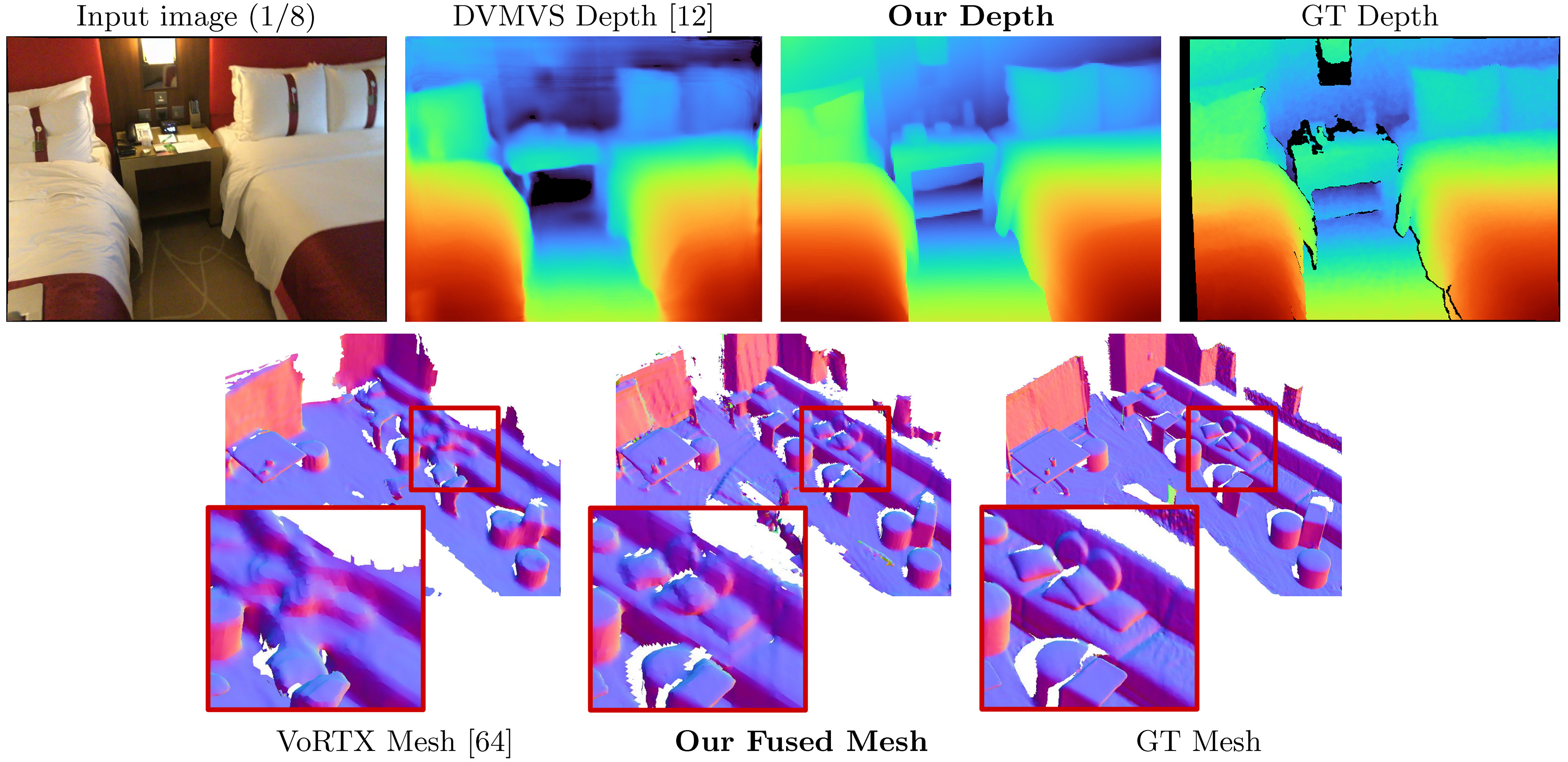
SimpleRecon toma a medida que la entrada planteó imágenes RGB y genera un mapa de profundidad para una imagen de destino.
Suponiendo una distribución de Anaconda fresca, puede instalar dependencias con:
conda env create -f simplerecon_env.ymlEjecutamos nuestros experimentos con Pytorch 1.10, Cuda 11.3, Python 3.9.7 y Debian GNU/Linux 10.
Descargue un modelo previo alado en los weights/ carpeta.
Proporcionamos los siguientes modelos (los puntajes son con fotogramas de teclas predeterminados en línea):
--config | Modelo | ABS Diff ↓ | SQ Rel ↓ | Delta <1.05 ↑ | Chaffer ↓ | Puntaje f |
|---|---|---|---|---|---|---|
hero_model.yaml | Metadatos + coincidencia de resnet | 0.0868 | 0.0127 | 74.26 | 5.69 | 0.680 |
dot_product_model.yaml | Producto DOT + coincidencia de resnet | 0.0910 | 0.0134 | 71.90 | 5.92 | 0.667 |
hero_model es el que usamos en el periódico como nuestro
--config | Modelo | Velocidad de inferencia ( --batch_size 1 ) | Memoria de inferencia de gpu | Tiempo de entrenamiento aproximado |
|---|---|---|---|---|
hero_model | Héroe, Metadatos + Resnet | 130 ms / 70ms (velocidad optimizada) | 2.6GB / 5.7 GB (velocidad optimizada) | 36 horas |
dot_product_model | Producto Dot + Resnet | 80 ms | 2.6GB | 36 horas |
Con lotes más grandes, la velocidad aumenta considerablemente. Con el tamaño del lote 8 en el modelo optimizado sin velocidad, la latencia cae a ~ 40 ms.
datasets/arkit_dataset.py . ACTUALIZACIÓN: Ahora hay un rápido readMe data_scripts/ios_logger_arkit_readme.md sobre cómo procesar y ejecutar Inference un escaneo de iOS-Logger usando el script en data_scripts/ios_logger_preprocessing.py . Ahora hemos incluido dos escaneos para que las personas prueben de inmediato con el código. Puede descargar estos escaneos desde aquí.
Pasos:
hero_model en el directorio de pesas.dataset_path en configs/data/vdr_dense.yaml a la ruta base de la carpeta VDR descomprimida.CUDA_VISIBLE_DEVICES=0 python test.py --name HERO_MODEL
--output_base_path OUTPUT_PATH
--config_file configs/models/hero_model.yaml
--load_weights_from_checkpoint weights/hero_model.ckpt
--data_config configs/data/vdr_dense.yaml
--num_workers 8
--batch_size 2
--fast_cost_volume
--run_fusion
--depth_fuser open3d
--fuse_color
--dump_depth_visualization ; Esto emitirá mallas, profundidad rápida a saber y Sócres cuando se comparó con la profundidad de LiDAR bajo OUTPUT_PATH .
Este comando usa vdr_dense.yaml que generará profundidades para cada cuadro y las fusionará en una malla. En el documento, informamos puntajes con fotogramas de clave fusionadas, y puede ejecutar aquellos que usan vdr_default.yaml . También puede usar dense_offline tuples en su lugar usando vdr_dense_offline.yaml .
Consulte la sección a continuación sobre pruebas y evaluación. Asegúrese de usar los indicadores de configuración correctos para conjuntos de datos.
Siga las instrucciones aquí para descargar el conjunto de datos. Este conjunto de datos es bastante grande (> 2tb), así que asegúrese de tener suficiente espacio, especialmente para extraer archivos.
Una vez descargado, use este script para exportar datos de sensor sin procesar a imágenes y archivos de profundidad.
Hemos escrito un tutorial rápido e incluimos scripts modificados para ayudarlo a descargar y extraer Scannetv2. Puede encontrarlos en data_scripts/Scannet_wrangling_scripts/
Debe cambiar el argumento de configuración dataset_path para las configuraciones de datos ScannetV2 en configs/data/ para que coincida con su conjunto de datos.
La base de código espera que ScannetV2 esté en el siguiente formato:
dataset_path
scans_test (test scans)
scene0707
scene0707_00_vh_clean_2.ply (gt mesh)
sensor_data
frame-000261.pose.txt
frame-000261.color.jpg
frame-000261.color.512.png (optional, image at 512x384)
frame-000261.color.640.png (optional, image at 640x480)
frame-000261.depth.png (full res depth, stored scale *1000)
frame-000261.depth.256.png (optional, depth at 256x192 also
scaled)
scene0707.txt (scan metadata and image sizes)
intrinsic
intrinsic_depth.txt
intrinsic_color.txt
...
scans (val and train scans)
scene0000_00
(see above)
scene0000_01
....
En este ejemplo de scene0707.txt debe contener los metadatos del escaneo:
colorHeight = 968
colorToDepthExtrinsics = 0.999263 -0.010031 0.037048 ........
colorWidth = 1296
depthHeight = 480
depthWidth = 640
fx_color = 1170.187988
fx_depth = 570.924255
fy_color = 1170.187988
fy_depth = 570.924316
mx_color = 647.750000
mx_depth = 319.500000
my_color = 483.750000
my_depth = 239.500000
numColorFrames = 784
numDepthFrames = 784
numIMUmeasurements = 1632
frame-000261.pose.txt debe contener pose en el formulario:
-0.384739 0.271466 -0.882203 4.98152
0.921157 0.0521417 -0.385682 1.46821
-0.0587002 -0.961035 -0.270124 1.51837
frame-000261.color.512.png y frame-000261.color.640.png son versiones redimensionadas de la imagen original para ahorrar tiempo de carga y calcular durante el entrenamiento y las pruebas. frame-000261.depth.256.png también es una versión redimensionada del mapa de profundidad.
Es bueno tener todas las versiones de profundidad e imágenes redimensionadas, pero no se requieren. Si no existen, las versiones de resolución completa se cargarán y se muestrean en la marcha.
De manera predeterminada, estimamos un mapa de profundidad para cada fotograma clave en un escaneo. Utilizamos la heurística de DeepVideomvs para la separación del fotograma clave y construimos tuples para que coincidan. Usamos los mapas de profundidad en estos fotogramas clave para la fusión de profundidad. Para cada fotograma clave, asociamos una lista de marcos de origen que se utilizarán para construir el volumen de costos. También usamos tuplas densas, donde predecimos un mapa de profundidad para cada cuadro en los datos, y no solo en fotogramas clave específicos; Estos se utilizan principalmente para la visualización.
Generamos y exportamos una lista de tuplas en todos los escaneos que actúan como elementos del conjunto de datos. Hemos precomputado estas listas y están disponibles en data_splits en la división de cada conjunto de datos. Para los escaneos de prueba de Scannet, están en data_splits/ScanNetv2/standard_split . Nuestros números de profundidad básicos se calculan utilizando data_splits/ScanNetv2/standard_split/test_eight_view_deepvmvs.txt .
Aquí hay una taxona rápida del tipo de tuplas para la prueba:
default : una tupla para cada fotograma clave que sigue a DeepVideomVs donde todos los cuadros de origen están en el pasado. Utilizado para toda la evaluación de profundidad y malla a menos que se indique lo contrario. Para escané, use data_splits/ScanNetv2/standard_split/test_eight_view_deepvmvs.txt .offline : una tupla para cada cuadro en el escaneo donde los marcos de origen pueden ser tanto en el pasado como en el futuro en relación con el marco actual. Estos son útiles cuando una escena se captura fuera de línea, y desea la mejor precisión posible. Con las tuplas en línea, el volumen de costos contendrá regiones vacías a medida que la cámara se aleje y todos los marcos de origen se queden atrás; Sin embargo, con tuplas fuera de línea, el volumen de costos está lleno en ambos extremos, lo que lleva a una mejor estimación de escala (y métrica).dense : una tupla en línea (como predeterminada) para cada cuadro en el escaneo donde todos los cuadros de origen están en el pasado. Para el escaneo, esto sería data_splits/ScanNetv2/standard_split/test_eight_view_deepvmvs_dense.txt .offline : una tupla fuera de línea para cada fotograma clave para cada fotograma clave en el escaneo.Para los conjuntos de trenes y validación, seguimos la misma estrategia de aumento de tupla que en DeepVideomVS y usamos el mismo script de generación de núcleo.
Si desea generar estas tuplas usted mismo, puede usar los scripts en data_scripts/generate_train_tuples.py para entrenar tuplas y data_scripts/generate_test_tuples.py para probar tuples. Estos siguen el mismo formato de configuración que test.py y usará cualquier clase de conjunto de datos que cree para leer Pose Informaiton.
Ejemplo para la prueba:
# default tuples
python ./data_scripts/generate_test_tuples.py
--data_config configs/data/scannet_default_test.yaml
--num_workers 16
# dense tuples
python ./data_scripts/generate_test_tuples.py
--data_config configs/data/scannet_dense_test.yaml
--num_workers 16Ejemplos para el tren:
# train
python ./data_scripts/generate_train_tuples.py
--data_config configs/data/scannet_default_train.yaml
--num_workers 16
# val
python ./data_scripts/generate_val_tuples.py
--data_config configs/data/scannet_default_val.yaml
--num_workers 16 Estos scripts primero verificarán cada cuadro en el conjunto de datos para asegurarse de que tenga un marco RGB existente, un marco de profundidad existente (si es apropiado para el conjunto de datos) y también un archivo de pose existente y válido. Guardará estos valid_frames en un archivo de texto en la carpeta de cada escaneo, pero si el directorio se lee solo, ignorará guardar un archivo valid_frames y generar tuplas de todos modos.
Puede usar test.py para inferir y evaluar mapas de profundidad y fusiones de mallas.
Todos los resultados se almacenarán en una carpeta de resultados base (resultados_path) en:
opts.output_base_path/opts.name/opts.dataset/opts.frame_tuple_type/
donde opta es la clase options . Por ejemplo, cuando opts.output_base_path es ./results , opts.name es HERO_MODEL , opts.dataset es scannet y opts.frame_tuple_type es default , el directorio de salida será
./results/HERO_MODEL/scannet/default/
Asegúrese de establecer --opts.output_base_path en un directorio adecuado para que pueda almacenar resultados.
--frame_tuple_type es el tipo de tupla de imagen utilizada para MVS. Se debe proporcionar una selección en el archivo data_config que utilizó.
Por defecto, test.py intentará calcular los puntajes de profundidad para cada cuadro y proporcionará métricas promediadas por la escena y las métricas promedio de escena. El script guardará estos puntajes (por escena y totales) en results_path/scores .
Hemos hecho todo lo posible para asegurarnos de que un error de lotes de antorcha a través del codificador coincidente se solucione para pruebas (<10^-4) precisas al deshabilitar el lote de imagen a través de ese codificador. Ejecute --batch_size 4 como máximo si está en duda, y si está buscando obtener los números lo más estables posible y evitar los gremlins de Pytorch, use --batch_size 1 para la evaluación de comparación.
Si desea usar esto para Speed, establezca --fast_cost_volume a true. Esto habilitará un lote a través del codificador coincidente y habilitará un volumen de características optimizado de EINOPS.
# Example command to just compute scores
CUDA_VISIBLE_DEVICES=0 python test.py --name HERO_MODEL
--output_base_path OUTPUT_PATH
--config_file configs/models/hero_model.yaml
--load_weights_from_checkpoint weights/hero_model.ckpt
--data_config configs/data/scannet_default_test.yaml
--num_workers 8
--batch_size 4 ;
# If you'd like to get a super fast version use:
CUDA_VISIBLE_DEVICES=0 python test.py --name HERO_MODEL
--output_base_path OUTPUT_PATH
--config_file configs/models/hero_model.yaml
--load_weights_from_checkpoint weights/hero_model.ckpt
--data_config configs/data/scannet_default_test.yaml
--num_workers 8
--fast_cost_volume
--batch_size 2 ;Este script también se puede usar para realizar algunas tareas auxiliares diferentes, que incluyen:
Fusión TSDF
Para ejecutar TSDF Fusion, proporcione el indicador --run_fusion . Tienes dos opciones para fusores
--depth_fuser ours (predeterminado) utilizará nuestro fusor, cuyas mallas se usan en la mayoría de las visualizaciones y para los puntajes. Este fusor no admite el color. Hemos proporcionado una rama personalizada de Scikit-Image con nuestra implementación personalizada de measure.matching_cubes . Utilizamos mallas de paredes individuales para la evaluación. Si esto no es importante para usted, puede establecer el export_single_mesh en False para llamar a export_mesh en test.py--depth_fuser open3d utilizará el fusor de profundidad Open3D. Este fusor admite el color y puede habilitarlo utilizando el indicador --fuse_color . Por defecto, los mapas de profundidad se recortarán a 3M para fusión y se utilizará una resolución TSDF de 0.04m 3 , pero puede cambiarlo cambiando tanto --max_fusion_depth como --fusion_resolution
Puede solicitar opcionalmente las profundidades predichas utilizadas para que la fusión se enmascare cuando no existe información VAIID MVS usando --mask_pred_depths . Esto no está habilitado de forma predeterminada.
También puede fusionar las mejores profundidades de sujetos del volumen de costos antes del descodificador del codificador de volumen de costos que introduce una imagen fuerte anterior. Puede hacer esto usando --fusion_use_raw_lowest_cost .
Las mallas se almacenarán en results_path/meshes/ .
# Example command to fuse depths to get meshes
CUDA_VISIBLE_DEVICES=0 python test.py --name HERO_MODEL
--output_base_path OUTPUT_PATH
--config_file configs/models/hero_model.yaml
--load_weights_from_checkpoint weights/hero_model.ckpt
--data_config configs/data/scannet_default_test.yaml
--num_workers 8
--run_fusion
--batch_size 8 ;Profundidades de caché
Opcionalmente, puede almacenar las profundidades proporcionando el indicador --cache_depths . Se almacenarán en results_path/depths .
# Example command to compute scores and cache depths
CUDA_VISIBLE_DEVICES=0 python test.py --name HERO_MODEL
--output_base_path OUTPUT_PATH
--config_file configs/models/hero_model.yaml
--load_weights_from_checkpoint weights/hero_model.ckpt
--data_config configs/data/scannet_default_test.yaml
--num_workers 8
--cache_depths
--batch_size 8 ;
# Example command to fuse depths to get color meshes
CUDA_VISIBLE_DEVICES=0 python test.py --name HERO_MODEL
--output_base_path OUTPUT_PATH
--config_file configs/models/hero_model.yaml
--load_weights_from_checkpoint weights/hero_model.ckpt
--data_config configs/data/scannet_default_test.yaml
--num_workers 8
--run_fusion
--depth_fuser open3d
--fuse_color
--batch_size 4 ;Rápido a saber
Existen otros scripts para visualizaciones más profundas de las profundidades de salida y la fusión, pero para la exportación rápida de la visualización de mapas de profundidad puede usar --dump_depth_visualization . Las visualizaciones se almacenarán en results_path/viz/quick_viz/ .
# Example command to output quick depth visualizations
CUDA_VISIBLE_DEVICES=0 python test.py --name HERO_MODEL
--output_base_path OUTPUT_PATH
--config_file configs/models/hero_model.yaml
--load_weights_from_checkpoint weights/hero_model.ckpt
--data_config configs/data/scannet_default_test.yaml
--num_workers 8
--dump_depth_visualization
--batch_size 4 ; También permitimos mapas de profundidad de fusor de fusor de fusor de fusor de fusor de fusor de 3DVNet.
# Example command to fuse depths into point clouds.
CUDA_VISIBLE_DEVICES=0 python pc_fusion.py --name HERO_MODEL
--output_base_path OUTPUT_PATH
--config_file configs/models/hero_model.yaml
--load_weights_from_checkpoint weights/hero_model.ckpt
--data_config configs/data/scannet_dense_test.yaml
--num_workers 8
--batch_size 4 ; Cambie configs/data/scannet_dense_test.yaml a configs/data/scannet_default_test.yaml para usar los cuadros de clave solo si no desea esperar demasiado.
Utilizamos la evaluación de malla de TransformerFusion para nuestra tabla de resultados principales, pero establecemos la semilla en un valor fijo para la consistencia al muestrear aleatoriamente las mallas. También informamos métricas de malla utilizando la evaluación de Neuralrecon en el material suplementario.
Para la evaluación de la nube de puntos, utilizamos el código de TransformerFusion pero cargamos en una nube de puntos en lugar de muestrear la superficie de una malla.
De forma predeterminada, los modelos y los archivos de eventos de Tensorboard se guardan en ~/tmp/tensorboard/<model_name> . Esto se puede cambiar con la bandera --log_dir .
Entrenamos con un lote_size de 16 con precisión de 16 bits en dos A100 en la división de ScannetV2 predeterminada.
Ejemplo Comando para entrenar con dos GPU:
CUDA_VISIBLE_DEVICES=0,1 python train.py --name HERO_MODEL
--log_dir logs
--config_file configs/models/hero_model.yaml
--data_config configs/data/scannet_default_train.yaml
--gpus 2
--batch_size 16 ; El código admite cualquier cantidad de GPU para capacitación. Puede especificar qué GPU usar con el entorno CUDA_VISIBLE_DEVICES .
Todas nuestras carreras de entrenamiento se realizaron en dos A100 NVIDIA.
Diferente conjunto de datos
Puede entrenar en un conjunto de datos MVS personalizado escribiendo una nueva clase DataLoader que hereda de GenericMVSDataset en datasets/generic_mvs_dataset.py . Vea la clase ScannetDataset en datasets/scannet_dataset.py o de hecho cualquier otra clase en datasets para un ejemplo.
Para Finetune, cargue un punto de control simple (¡no se reanude!) Y entrena desde allí:
CUDA_VISIBLE_DEVICES=0 python train.py --config configs/models/hero_model.yaml
--data_config configs/data/scannet_default_train.yaml
--load_weights_from_checkpoint weights/hero_model.ckptCambie las configuraciones de datos a cualquier conjunto de datos al que desee Finetune.
Consulte options.py para la gama de otras opciones de capacitación, como tarifas de aprendizaje y configuraciones de ablación, y opciones de prueba.
Además de la visualización de profundidad rápida en el script test.py , hay dos scripts para visualizar la salida de profundidad.
El primero es visualization_scripts/visualize_scene_depth_output.py . Esto producirá un video con imágenes en color de los marcos de referencia y fuente, predicción de profundidad, estimación de volumen de costos, profundidad GT y normales estimadas desde la profundidad. El script supone que tiene salida de profundidad en caché usando test.py y acepta el mismo formato de plantilla de comando que test.py :
# Example command to get visualizations for dense frames
CUDA_VISIBLE_DEVICES=0 python ./visualization_scripts/visualize_scene_depth_output.py --name HERO_MODEL
--output_base_path OUTPUT_PATH
--data_config configs/data/scannet_dense_test.yaml
--num_workers 8 ; Donde OUTPUT_PATH es el directorio de resultados base para SimpleReCon (lo que usó para comenzar a Test). Opcionalmente, puede ejecutar .visualization_scripts/generate_gt_min_max_cache.py antes de este script para obtener un promedio de escena para los valores de profundidad MIN y máximo utilizados para el colormapaping; Si no están disponibles, el script usará 0m y 5m para Colomapping Min y Max.
El segundo permite una visualización en vivo de malla. Este script usará mapas de profundidad en caché si está disponible, de lo contrario usará el modelo para predecirlos antes de la fusión. El script se cargará iterativamente en un mapa de profundidad, lo fusionará, guardará un archivo de malla en este paso y representará esta malla junto con un marcador de cámara para el video BirdSeye, y desde el punto de vista de la cámara para el video FPV.
# Example command to get live visualizations for mesh reconstruction
CUDA_VISIBLE_DEVICES=0 python visualize_live_meshing.py --name HERO_MODEL
--output_base_path OUTPUT_PATH
--config_file configs/models/hero_model.yaml
--load_weights_from_checkpoint weights/hero_model.ckpt
--data_config configs/data/scannet_dense_test.yaml
--num_workers 8 ; De manera predeterminada, el script guardará mallas en una ubicación intermedia, y opcionalmente puede cargar esas mallas para ahorrar tiempo al visualizar las mismas mallas nuevamente pasando --use_precomputed_partial_meshes . Todas las mallas intermedias habrán tenido que calcularse en la ejecución anterior para que esto funcione.
Tl; dr: world_T_cam == world_from_cam
Este repositorio utiliza la notación "Cam_T_World" para denotar una transformación del mundo a los puntos de cámara (extrínsics). La intención es hacerlo para que los nombres de cuadros de coordenadas coincidan a cada lado de la variable cuando se usan en multiplicación de derecha a izquierda :
cam_points = cam_T_world @ world_points
world_T_cam denota la pose de la cámara (de Cam a World Coords). ref_T_src denota una transformación de una fuente a una vista de referencia.
Finalmente, esta notación permite representar rotaciones y traducciones como: world_R_cam y world_t_cam
Este repositorio está orientado hacia el escaneto, por lo que si bien su funcionalidad debe permitir cualquier sistema de coordenadas (señalado a través de indicadores de entrada), los pesos del modelo que proporcionamos asumen un sistema de coordenadas de escaneto. Esto es importante ya que incluimos la información de Ray como parte de los metadatos. Otros conjuntos de datos utilizados con estos pesos deben transformarse en el sistema de escaneo. Las clases de conjunto de datos que incluimos realizarán las transformaciones apropiadas.
Hay algunos errores abordados en esta actualización, deberá actualizar sus horquillas y usar nuevos pesos de la tabla cerca del comienzo de este readme. También deberá asegurarse de tener los archivos intrínsecos correctos extraídos con el lector.
Gracias a todos aquellos que lo señalaron y fueron pacientes mientras trabajábamos en soluciones.
Todos los puntajes mejoran con estas correcciones, y los pesos asociados se cargan aquí. Para puntajes, código y pesas antiguos, consulte este HASH de confirmación: 7DE5B451E340F9A11C7FD67BD0C42204D0B009A9
Puntajes completos para modelos con correcciones de errores:
Profundidad
--config | ABS Diff ↓ | ABS REL ↓ | SQ Rel ↓ | RMSE ↓ | log RMSE ↓ | Delta <1.05 ↑ | Delta <1.10 ↑ |
|---|---|---|---|---|---|---|---|
hero_model.yaml , metadatos + resnet | 0.0868 | 0.0428 | 0.0127 | 0.1472 | 0.0681 | 74.26 | 90.88 |
dot_product_model.yaml , producto dot + resnet | 0.0910 | 0.0453 | 0.0134 | 0.1509 | 0.0704 | 71.90 | 89.75 |
Fusión de malla
--config | ACC ↓ | Comp ↓ | Chaffer ↓ | Recordar ↑ | Precisión ↑ | Puntaje f |
|---|---|---|---|---|---|---|
hero_model.yaml , metadatos + resnet | 5.41 | 5.98 | 5.69 | 0.695 | 0.668 | 0.680 |
dot_product_model.yaml , producto dot + resnet | 5.66 | 6.18 | 5.92 | 0.682 | 0.655 | 0.667 |
Comparación:
--config | Modelo | ABS Diff ↓ | SQ Rel ↓ | Delta <1.05 ↑ | Chaffer ↓ | Puntaje f |
|---|---|---|---|---|---|---|
hero_model.yaml | Metadatos + coincidencia de resnet | 0.0868 | 0.0127 | 74.26 | 5.69 | 0.680 |
Old hero_model.yaml | Metadatos + coincidencia de resnet | 0.0885 | 0.0125 | 73.16 | 5.81 | 0.671 |
dot_product_model.yaml | Producto DOT + coincidencia de resnet | 0.0910 | 0.0134 | 71.90 | 5.92 | 0.667 |
Antiguo dot_product_model.yaml | Producto DOT + coincidencia de resnet | 0.0941 | 0.0139 | 70.48 | 6.29 | 0.642 |
Inicialmente, este repositorio escupe archivos de tuple para los cuadros de teclas de estilo DVMVS predeterminados con 9 marco adicional de 25599 para el conjunto de pruebas ScannetV2. Había un error menor con el manejo de seguimiento perdido que ahora se soluciona. Este repositorio ahora debería imitar el búfer de fotograma de teclas DVMVS exactamente, con 25590 fotogramas clave para las pruebas. El único efecto que tuvo este error fue la inclusión de 9 cuadros adicionales, todas las otras tuplas fueron exactamente el mismo que el de los DVMV. Los marcos ofensivos están en estos escaneos
scan previous count new count
--------------------------------------
scene0711_00 393 392
scene0727_00 209 208
scene0736_00 1023 1022
scene0737_00 408 407
scene0751_00 165 164
scene0775_00 220 219
scene0791_00 227 226
scene0794_00 141 140
scene0795_00 102 101
Los archivos TUPLE para la prueba predeterminada se han actualizado. Dado que esta es una pequeña diferencia (~ 3e-4) en marcos adicionales puntuados, los puntajes no cambian.
TL; DR: Escala sus poses y recorte sus imágenes.
Proporcionamos un dataloader para cargar imágenes de una reconstrucción dispersa de colmap. Para que esto funcione con SimpleReCon, necesitará recortar sus imágenes para que coincida con el FOV del escaneo (aproximadamente similar al FOV de un iPhone en modo de video) y escalar la ubicación de su pose utilizando mediciones conocidas del mundo real. Si no se toman estos pasos, el volumen de costos no se construirá correctamente y la red no estimará la profundidad correctamente.
Agradecemos a Aljaž Božič de Transformerfusion, Jiaming Sun de Neural Recon, y Arda Düzçeker de DeepVidomvs por proporcionar rápidamente información útil para ayudar con las líneas de base y hacer que sus bases estén fácilmente disponibles, especialmente a corto plazo.
Los scripts de generación de tupla hacen un uso pesado de una versión modificada del búfer de cuadro de cuadros de DeepVideomvs (¡gracias de nuevo arda y co!).
El módulo de fusión de la nube de puntos Pytorch en el código torch_point_cloud_fusion se toma prestado del repositorio de 3DVNET. ¡Gracias Alexander Rich!
También nos gustaría agradecer al equipo de infraestructura de Niantic por acciones rápidas cuando las necesitamos. ¡Gracias amigos!
Mohamed está financiado por una beca Microsoft Research PhD (MRL 2018-085).
Si encuentra útil nuestro trabajo en su investigación, considere citar nuestro documento:
@inproceedings{sayed2022simplerecon,
title={SimpleRecon: 3D Reconstruction Without 3D Convolutions},
author={Sayed, Mohamed and Gibson, John and Watson, Jamie and Prisacariu, Victor and Firman, Michael and Godard, Cl{'e}ment},
booktitle={Proceedings of the European Conference on Computer Vision (ECCV)},
year={2022},
}
Copyright © Niantic, Inc. 2022. Patente pendiente. Reservados todos los derechos. Consulte el archivo de licencia para los términos.


