simplerecon
1.0.0
هذا هو تطبيق Pytorch المرجعي لتدريب واختبار نماذج تقدير عمق MVS باستخدام الطريقة الموضحة في
Simplerecon: إعادة بناء ثلاثية الأبعاد بدون تلحقات ثلاثية الأبعاد
محمد سيد ، جون جيبسون ، جيمي واتسون ، فيكتور أدريان بريساكاريو ، مايكل فيرمان ، وكليمنت جودارد
ورقة ، ECCV 2022 (ARXIV PDF) ، المواد الإضافية ، صفحة المشروع ، الفيديو
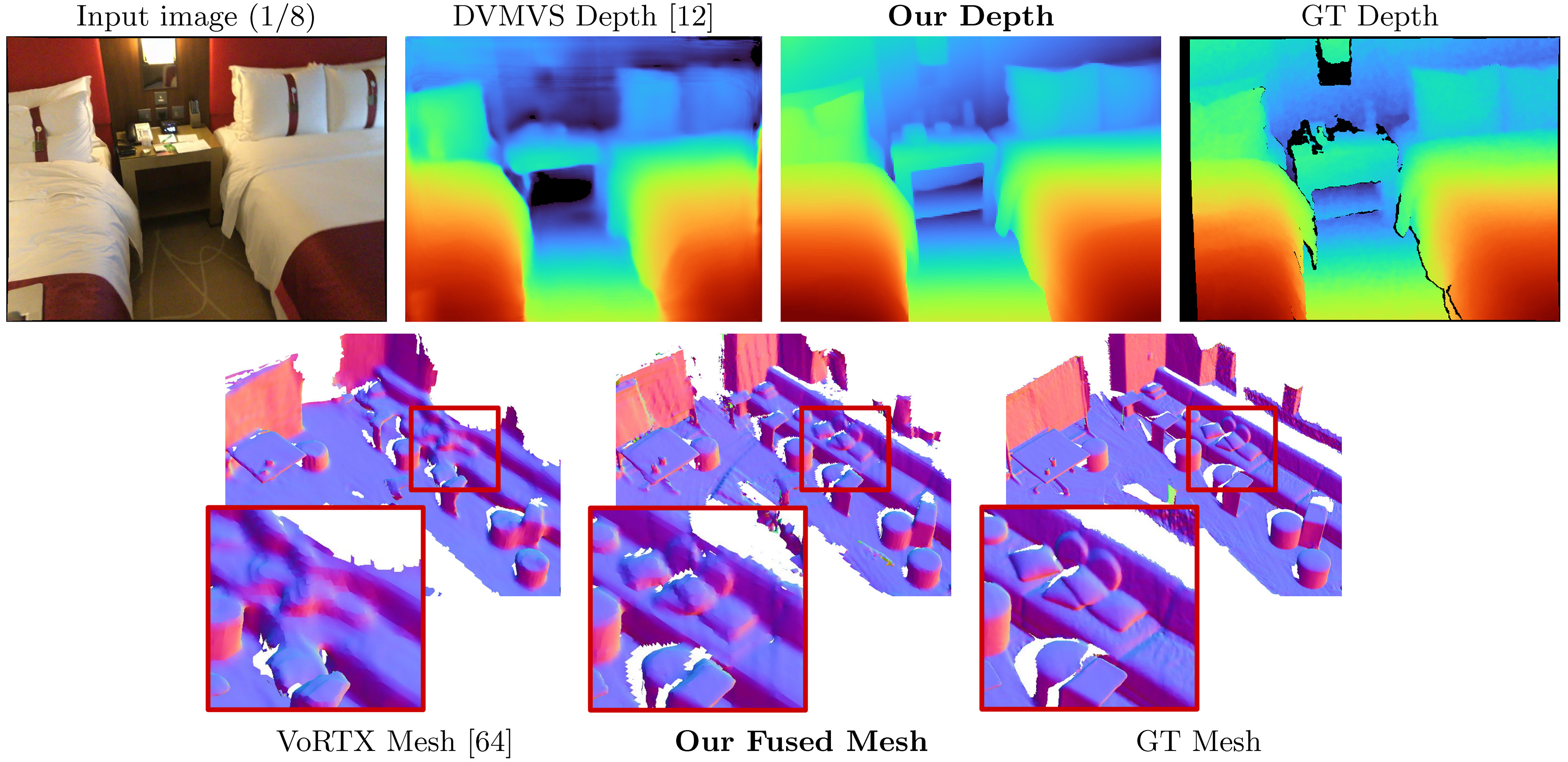
هذا الرمز مخصص للاستخدام غير التجاري ؛ يرجى الاطلاع على ملف الترخيص للشروط. إذا وجدت أي جزء من قاعدة الشفرة هذه مفيدة ، فيرجى الاستشهاد بالورقة باستخدام bibtex أدناه وربط هذا الريبو. شكرًا!
clang llvm-openmp protobuf استخدم ملف البيئة الجديد هذا إذا كنت تواجه مشكلة في تشغيل الكود و/أو إذا كان dataloading يقتصر على مؤشر ترابط واحد.
09/03/2023: تمت إضافة إصدار Kornia إلى ملف البيئات لإصلاح مشكلة كتابة Kornia. (شكرًا Natesimon!)
26/01/2023: تم تعديل الترخيص لجعل تشغيل النموذج لأسباب أكاديمية أسهل. يرجى ملف الترخيص للحصول على التفاصيل الدقيقة.
يوجد تحديث اعتبارًا من 31/12/2022 يعمل على إصلاح عنادق خاطئ قليلاً ، وزيادة الوجه لحجم التكلفة ، وخلل الدقة العددية في الإسقاط. جميع الدرجات تتحسن. ستحتاج إلى تحديث شوكاتك واستخدام أوزان جديدة. انظر إصلاحات الأخطاء.
عمليات مسح مسبقة للإطارات الافتراضية عبر الإنترنت هنا: https://drive.google.com/drive/folders/1dsofi9gayyhqjsx4i_ng0-3ebcafwxjv؟usp=share_link
يأخذ SimplereCon كما تم طرح إدخال صور RGB ، ويخرج خريطة عمق لصورة مستهدفة.
بافتراض توزيع Anaconda جديد ، يمكنك تثبيت التبعيات مع:
conda env create -f simplerecon_env.ymlأجرينا تجاربنا مع Pytorch 1.10 و Cuda 11.3 و Python 3.9.7 و Debian Gnu/Linux 10.
قم بتنزيل نموذج مسبق في weights/ المجلد.
نحن نقدم النماذج التالية (الدرجات مع إطارات المفاتيح الافتراضية عبر الإنترنت):
--config | نموذج | ABS Diff ↓ | SQ REL ↓ | دلتا <1.05 ↑ | Chamfer ↓ | F-Score ↑ |
|---|---|---|---|---|---|---|
hero_model.yaml | Metadata + Resnet مطابقة | 0.0868 | 0.0127 | 74.26 | 5.69 | 0.680 |
dot_product_model.yaml | منتج DOT + مطابقة RESNET | 0.0910 | 0.0134 | 71.90 | 5.92 | 0.667 |
hero_model هو الشخص الذي نستخدمه في الورقة مثلنا
--config | نموذج | سرعة الاستدلال ( --batch_size 1 ) | استنتاج ذاكرة GPU | وقت التدريب التقريبي |
|---|---|---|---|---|
hero_model | البطل ، البيانات الوصفية + RESNET | 130ms / 70ms (تحسين السرعة) | 2.6 جيجابايت / 5.7 جيجابايت (تحسين السرعة) | 36 ساعة |
dot_product_model | منتج DOT + RESNET | 80ms | 2.6 جيجابايت | 36 ساعة |
مع زيادة سرعة الدُفعات بشكل كبير. مع حجم الدُفعة 8 على الطراز المحسن غير السرعة ، ينخفض الكمون إلى 40 مللي ثانية.
datasets/arkit_dataset.py . تحديث: يوجد الآن readme data_scripts/ios_logger_arkit_readme.md لكيفية معالجة وتشغيل مسح iOS-logger باستخدام البرنامج النصي على data_scripts/ios_logger_preprocessing.py . لقد قمنا الآن بتضمين اثنين من عمليات الفحص للأشخاص لتجربتها على الفور مع الكود. يمكنك تنزيل هذه المسح من هنا.
خطوات:
hero_model في دليل الأوزان.dataset_path في configs/data/vdr_dense.yaml إلى المسار الأساسي لمجلد VDR غير المصدفة.CUDA_VISIBLE_DEVICES=0 python test.py --name HERO_MODEL
--output_base_path OUTPUT_PATH
--config_file configs/models/hero_model.yaml
--load_weights_from_checkpoint weights/hero_model.ckpt
--data_config configs/data/vdr_dense.yaml
--num_workers 8
--batch_size 2
--fast_cost_volume
--run_fusion
--depth_fuser open3d
--fuse_color
--dump_depth_visualization ; سيؤدي ذلك إلى إخراج الشبكات ، بمعنى العمق السريع ، و SoCres عند قيامه بتقييم مع عمق Lidar تحت OUTPUT_PATH .
يستخدم هذا الأمر vdr_dense.yaml الذي سيولد أعماقًا لكل إطار ودمجها في شبكة. في الورقة ، نقوم بالإبلاغ عن نتائج مع إطارات المفاتيح المنصهرة بدلاً من ذلك ، ويمكنك تشغيلها باستخدام vdr_default.yaml . يمكنك أيضًا استخدام tuples dense_offline بدلاً من ذلك باستخدام vdr_dense_offline.yaml .
انظر القسم أدناه عند الاختبار والتقييم. تأكد من استخدام أعلام التكوين الصحيحة لمجموعات البيانات.
يرجى اتباع التعليمات هنا لتنزيل مجموعة البيانات. مجموعة البيانات هذه كبيرة جدًا (> 2 تيرابايت) ، لذا تأكد من أن لديك مساحة كافية ، خاصة لاستخراج الملفات.
بمجرد التنزيل ، استخدم هذا البرنامج النصي لتصدير بيانات مستشعر RAW إلى الصور وملفات العمق.
لقد كتبنا برنامجًا تعليميًا سريعًا وقمنا بتضمين البرامج النصية المعدلة لمساعدتك في تنزيل واستخراج Scannetv2. يمكنك العثور عليها على data_scripts/scannet_wrangling_scripts/
يجب عليك تغيير وسيطة تكوين dataset_path لتكوينات بيانات SCANNETV2 في configs/data/ لمطابقة مكان مجموعة البيانات الخاصة بك.
تتوقع Codebase أن تكون Scannetv2 بالتنسيق التالي:
dataset_path
scans_test (test scans)
scene0707
scene0707_00_vh_clean_2.ply (gt mesh)
sensor_data
frame-000261.pose.txt
frame-000261.color.jpg
frame-000261.color.512.png (optional, image at 512x384)
frame-000261.color.640.png (optional, image at 640x480)
frame-000261.depth.png (full res depth, stored scale *1000)
frame-000261.depth.256.png (optional, depth at 256x192 also
scaled)
scene0707.txt (scan metadata and image sizes)
intrinsic
intrinsic_depth.txt
intrinsic_color.txt
...
scans (val and train scans)
scene0000_00
(see above)
scene0000_01
....
في هذا المثال ، يجب أن يحتوي scene0707.txt على بيانات تعريف SCAN:
colorHeight = 968
colorToDepthExtrinsics = 0.999263 -0.010031 0.037048 ........
colorWidth = 1296
depthHeight = 480
depthWidth = 640
fx_color = 1170.187988
fx_depth = 570.924255
fy_color = 1170.187988
fy_depth = 570.924316
mx_color = 647.750000
mx_depth = 319.500000
my_color = 483.750000
my_depth = 239.500000
numColorFrames = 784
numDepthFrames = 784
numIMUmeasurements = 1632
يجب أن يحتوي frame-000261.pose.txt على وضع في النموذج:
-0.384739 0.271466 -0.882203 4.98152
0.921157 0.0521417 -0.385682 1.46821
-0.0587002 -0.961035 -0.270124 1.51837
frame-000261.color.512.png و frame-000261.color.640.png هي إصدارات مسجلة من الصورة الأصلية لحفظ الوقت وحساب الوقت أثناء التدريب والاختبار. frame-000261.depth.256.png هو أيضًا نسخة مجددة مسبقة من خريطة العمق.
جميع الإصدارات المسبقة المُجهزة من العمق والصور لطيفة ولكنها غير مطلوبة. إذا لم تكن موجودة ، فسيتم تحميل إصدارات الدقة الكاملة ، وتسخينها على الذبابة.
بشكل افتراضي ، نقدر خريطة عمق لكل إطار مفتاح في فحص. نستخدم مجرش DeepVideomvs لفصل الإطار الرئيسي وبناء tuples لتتناسب. نستخدم خرائط العمق في إطارات المفاتيح هذه للانصهار العمق. لكل إطار مفتاح ، نربط قائمة بالأطر المصدر التي سيتم استخدامها لبناء حجم التكلفة. نستخدم أيضًا tuples كثيفة ، حيث نتوقع خريطة عمق لكل إطار في البيانات ، وليس فقط في إطارات المفاتيح المحددة ؛ هذه تستخدم في الغالب للتصور.
نقوم بإنشاء وتصدير قائمة من tuples عبر جميع عمليات المسح التي تعمل كعناصر مجموعة البيانات. لقد قمنا بحساب هذه القوائم وهي متوفرة في data_splits ضمن تقسيم كل مجموعة بيانات. بالنسبة لمسح اختبار Scannet ، فهي في data_splits/ScanNetv2/standard_split . يتم حساب أرقام العمق الأساسية الخاصة بنا باستخدام data_splits/ScanNetv2/standard_split/test_eight_view_deepvmvs.txt .
فيما يلي تصنيف سريع من نوع tuples للاختبار:
default : توبلي لكل إطار مفتاح يتبع DeepVideomvs حيث تكون جميع إطارات المصدر في الماضي. تستخدم لجميع التقييم عمق وشبكة ما لم ينص على خلاف ذلك. بالنسبة إلى Scannet ، استخدم data_splits/ScanNetv2/standard_split/test_eight_view_deepvmvs.txt .offline : توبلي لكل إطار في المسح حيث يمكن أن تكون إطارات المصدر في الماضي والمستقبل بالنسبة للإطار الحالي. هذه مفيدة عندما يتم التقاط مشهد في وضع عدم الاتصال ، وتريد أفضل دقة ممكنة. مع tuples عبر الإنترنت ، سيحتوي حجم التكلفة على مناطق فارغة حيث تتحرك الكاميرا بعيدًا وتتخلف جميع إطارات المصدر ؛ ومع ذلك مع TUPLES دون اتصال ، فإن حجم التكلفة ممتلئ من كلا الطرفين ، مما يؤدي إلى تقدير أفضل (وقياس).dense : توبلي عبر الإنترنت (مثل الافتراضي) لكل إطار في المسح حيث تكون جميع إطارات المصدر في الماضي. بالنسبة إلى Scannet ، سيكون هذا هو data_splits/ScanNetv2/standard_split/test_eight_view_deepvmvs_dense.txt .offline : Tuple في وضع عدم الاتصال لكل إطار رئيسي لكل إطار مفتاح في الفحص.بالنسبة لمجموعات القطار والتحقق من الصحة ، نتبع نفس استراتيجية تكبير Tuple كما هو الحال في DeepVideomvs ونستخدم نفس البرنامج النصي للجيل الأساسي.
إذا كنت ترغب في إنشاء هذه الأشياء بنفسك ، فيمكنك استخدام البرامج النصية على data_scripts/generate_train_tuples.py لتدريب tuples و data_scripts/generate_test_tuples.py للاختبار tuples. هذه تتبع نفس تنسيق التكوين مثل test.py وسوف تستخدم أي فئة مجموعة البيانات التي تنشئها لقراءة Pose Informaiton.
مثال للاختبار:
# default tuples
python ./data_scripts/generate_test_tuples.py
--data_config configs/data/scannet_default_test.yaml
--num_workers 16
# dense tuples
python ./data_scripts/generate_test_tuples.py
--data_config configs/data/scannet_dense_test.yaml
--num_workers 16أمثلة للقطار:
# train
python ./data_scripts/generate_train_tuples.py
--data_config configs/data/scannet_default_train.yaml
--num_workers 16
# val
python ./data_scripts/generate_val_tuples.py
--data_config configs/data/scannet_default_val.yaml
--num_workers 16 ستقوم هذه البرامج النصية أولاً بفحص كل إطار في مجموعة البيانات للتأكد من أنه يحتوي على إطار RGB موجود ، وإطار عمق موجود (إذا كان ذلك مناسبًا لمجموعة البيانات) ، وأيضًا ملفًا موجودًا وصالحًا. سيؤدي ذلك إلى حفظ هذه valid_frames في ملف نصي في مجلد كل مسح ، ولكن إذا تمت قراءة الدليل فقط ، فسيتجاهل حفظ ملف valid_frames وإنشاء tuples على أي حال.
يمكنك استخدام test.py لاستنتاج وتقييم خرائط العمق وشبكات الانصهار.
سيتم تخزين جميع النتائج في مجلد النتائج الأساسية (REVENTS_PATH) على:
opts.output_base_path/opts.name/opts.dataset/opts.frame_tuple_type/
حيث OPTS هي فئة options . opts.dataset opts.frame_tuple_type scannet HERO_MODEL opts.name ./results opts.output_base_path default
./results/HERO_MODEL/scannet/default/
تأكد من تعيين --opts.output_base_path إلى دليل مناسب لك لتخزين النتائج.
--frame_tuple_type هو نوع tuple الصورة المستخدمة في MVS. يجب توفير تحديد في ملف data_config الذي استخدمته.
بشكل افتراضي ، سيحاول test.py حساب درجات العمق لكل إطار وتوفير متوسط الإطار ومتوسط المشهد. سيحفظ البرنامج النصي هذه الدرجات (لكل مشهد ومجموع) ضمن results_path/scores .
لقد بذلنا قصارى جهدنا للتأكد من أن الخلل في تجميع الشعلة من خلال التشفير المطابق ثابت للاختبار الدقيق (<10^-4) عن طريق تعطيل تكوين الصورة من خلال هذا التشفير. RUN --batch_size 4 على الأكثر إذا كنت في شك ، وإذا كنت تتطلع إلى الحصول على أرقام مستقرة قدر الإمكان وتجنب gremlins pytorch ، استخدم --batch_size 1 لتقييم المقارنة.
إذا كنت ترغب في استخدام هذا للسرعة ، فقم بتعيين --fast_cost_volume إلى True. سيمكن هذا التضخم من خلال المشفر المطابق وسيمكن من وحدة التخزين المحسّنة EINOPS.
# Example command to just compute scores
CUDA_VISIBLE_DEVICES=0 python test.py --name HERO_MODEL
--output_base_path OUTPUT_PATH
--config_file configs/models/hero_model.yaml
--load_weights_from_checkpoint weights/hero_model.ckpt
--data_config configs/data/scannet_default_test.yaml
--num_workers 8
--batch_size 4 ;
# If you'd like to get a super fast version use:
CUDA_VISIBLE_DEVICES=0 python test.py --name HERO_MODEL
--output_base_path OUTPUT_PATH
--config_file configs/models/hero_model.yaml
--load_weights_from_checkpoint weights/hero_model.ckpt
--data_config configs/data/scannet_default_test.yaml
--num_workers 8
--fast_cost_volume
--batch_size 2 ;يمكن أيضًا استخدام هذا البرنامج النصي لأداء بعض المهام المساعدة المختلفة ، بما في ذلك:
TSDF الانصهار
لتشغيل TSDF Fusion توفير علامة --run_fusion . لديك خياران للمزهر
--depth_fuser ours (الافتراضي) سوف يستخدم مصهرنا ، الذي يتم استخدام شبكاته في معظم التصورات وللدرجات. هذا الصهر لا يدعم اللون. لقد قدمنا فرعًا مخصصًا من صورة Scikit مع تنفيذنا المخصص لـ measure.matching_cubes الذي يسمح بالتجول المفرد. نستخدم شبكات مسورة واحدة للتقييم. إذا لم يكن هذا أمرًا مهمًا بالنسبة لك ، فيمكنك تعيين export_single_mesh على False لصالح الاتصال إلى export_mesh في test.py--depth_fuser open3d Depth_Fuser Open3D. يدعم هذا الصهر اللون ويمكنك تمكينه باستخدام علامة --fuse_color . بشكل افتراضي ، سيتم قطع خرائط العمق إلى 3 أمتار للانصهار وسيتم استخدام دقة TSDF بقيمة 0.04 م 3 ، ولكن يمكنك تغيير ذلك عن طريق تغيير كلاهما --max_fusion_depth و --fusion_resolution
يمكنك أن تسأل عن الأعماق المتوقعة المستخدمة في الانصهار ليتم إخفاءها عند عدم وجود معلومات Vaiid MVS باستخدام --mask_pred_depths . لا يتم تمكين هذا بشكل افتراضي.
يمكنك أيضًا دمج أفضل أعماق التخمين من حجم التكلفة قبل ترميز وحدة التخزين التي تقدم صورة تقدم صورة قوية قبل. يمكنك القيام بذلك باستخدام --fusion_use_raw_lowest_cost .
سيتم تخزين الشبكات تحت results_path/meshes/ .
# Example command to fuse depths to get meshes
CUDA_VISIBLE_DEVICES=0 python test.py --name HERO_MODEL
--output_base_path OUTPUT_PATH
--config_file configs/models/hero_model.yaml
--load_weights_from_checkpoint weights/hero_model.ckpt
--data_config configs/data/scannet_default_test.yaml
--num_workers 8
--run_fusion
--batch_size 8 ;أعماق ذاكرة التخزين المؤقت
يمكنك تخزين الأعماق اختياريا من خلال توفير علامة --cache_depths . سيتم تخزينها في results_path/depths .
# Example command to compute scores and cache depths
CUDA_VISIBLE_DEVICES=0 python test.py --name HERO_MODEL
--output_base_path OUTPUT_PATH
--config_file configs/models/hero_model.yaml
--load_weights_from_checkpoint weights/hero_model.ckpt
--data_config configs/data/scannet_default_test.yaml
--num_workers 8
--cache_depths
--batch_size 8 ;
# Example command to fuse depths to get color meshes
CUDA_VISIBLE_DEVICES=0 python test.py --name HERO_MODEL
--output_base_path OUTPUT_PATH
--config_file configs/models/hero_model.yaml
--load_weights_from_checkpoint weights/hero_model.ckpt
--data_config configs/data/scannet_default_test.yaml
--num_workers 8
--run_fusion
--depth_fuser open3d
--fuse_color
--batch_size 4 ;بمعنى سريع
هناك نصوص أخرى لتصورات أعمق لعمق الإخراج والانصهار ، ولكن للتصدير السريع لتصور خريطة العمق يمكنك استخدامه --dump_depth_visualization . سيتم تخزين التصورات في results_path/viz/quick_viz/ .
# Example command to output quick depth visualizations
CUDA_VISIBLE_DEVICES=0 python test.py --name HERO_MODEL
--output_base_path OUTPUT_PATH
--config_file configs/models/hero_model.yaml
--load_weights_from_checkpoint weights/hero_model.ckpt
--data_config configs/data/scannet_default_test.yaml
--num_workers 8
--dump_depth_visualization
--batch_size 4 ; نسمح أيضًا بالاندماج السحابي للنقطة لخرائط العمق باستخدام الصهر من ريبو 3DVNET.
# Example command to fuse depths into point clouds.
CUDA_VISIBLE_DEVICES=0 python pc_fusion.py --name HERO_MODEL
--output_base_path OUTPUT_PATH
--config_file configs/models/hero_model.yaml
--load_weights_from_checkpoint weights/hero_model.ckpt
--data_config configs/data/scannet_dense_test.yaml
--num_workers 8
--batch_size 4 ; تغيير configs/data/scannet_dense_test.yaml إلى configs/data/scannet_default_test.yaml لاستخدام إطارات المفاتيح فقط إذا كنت لا تريد الانتظار لفترة طويلة.
نحن نستخدم تقييم شبكة Transformerfusion لجدول النتائج الرئيسية لدينا ولكن اضبط البذور على قيمة ثابتة للتناسق عند شبكات أخذ العينات بشكل عشوائي. نقوم أيضًا بالإبلاغ عن مقاييس شبكة باستخدام تقييم NeuralRecon في المادة الإضافية.
لتقييم السحابة النقطة ، نستخدم رمز Transformerfusion ولكن التحميل في سحابة نقطة بدلاً من أخذ عينات من سطح شبكة.
بشكل افتراضي ، يتم حفظ النماذج الافتراضية وملفات الأحداث Tensorboard إلى ~/tmp/tensorboard/<model_name> . يمكن تغيير هذا مع علم --log_dir .
نقوم بالتدريب مع Batch_size من 16 بدقة 16 بت على اثنين من A100 على تقسيم Scannetv2 الافتراضي.
مثال على الأمر للتدريب مع اثنين من وحدات معالجة الرسومات:
CUDA_VISIBLE_DEVICES=0,1 python train.py --name HERO_MODEL
--log_dir logs
--config_file configs/models/hero_model.yaml
--data_config configs/data/scannet_default_train.yaml
--gpus 2
--batch_size 16 ; يدعم الرمز أي عدد من وحدات معالجة الرسومات للتدريب. يمكنك تحديد وحدات معالجة الرسومات التي يجب استخدامها مع بيئة CUDA_VISIBLE_DEVICES .
تم تنفيذ جميع عمليات التدريب لدينا على اثنين من Nvidia A100s.
مجموعة بيانات مختلفة
يمكنك التدريب على مجموعة بيانات MVS مخصصة عن طريق كتابة فئة جديدة من dataloader ترث من GenericMVSDataset في datasets/generic_mvs_dataset.py . راجع فئة ScannetDataset في datasets/scannet_dataset.py أو بالفعل أي فئة أخرى في datasets لمثال.
إلى Finetune ، قم بتحميل نقطة تفتيش بسيطة (لا تستأنف!) والتدريب من هناك:
CUDA_VISIBLE_DEVICES=0 python train.py --config configs/models/hero_model.yaml
--data_config configs/data/scannet_default_train.yaml
--load_weights_from_checkpoint weights/hero_model.ckptقم بتغيير البيانات إلى أي مجموعة بيانات ترغب في FineTune.
انظر options.py للحصول على مجموعة من خيارات التدريب الأخرى ، مثل معدلات التعلم وإعدادات الاجتثاث ، وخيارات الاختبار.
بخلاف تصور العمق السريع في البرنامج النصي test.py ، هناك نصتان لتصور إخراج العمق.
الأول هو visualization_scripts/visualize_scene_depth_output.py . سيؤدي ذلك إلى إنتاج مقطع فيديو يحتوي على صور ملونة للإطارات المرجعية والإيجاد ، والتنبؤ بالعمق ، وتقدير حجم التكلفة ، وعمق GT ، والمعايير المقدرة من العمق. يفترض البرنامج النصي أن يكون لديك إخراج عمق مخبأة باستخدام test.py ويقبل نفس تنسيق قالب الأوامر مثل test.py :
# Example command to get visualizations for dense frames
CUDA_VISIBLE_DEVICES=0 python ./visualization_scripts/visualize_scene_depth_output.py --name HERO_MODEL
--output_base_path OUTPUT_PATH
--data_config configs/data/scannet_dense_test.yaml
--num_workers 8 ; حيث يكون OUTPUT_PATH هو دليل النتائج الأساسية لـ Simplerecon (ما استخدمته لتبدأ لتبدأ). يمكنك تشغيل .visualization_scripts/generate_gt_min_max_cache.py إذا لم تكن متوفرة ، فسيستخدم البرنامج النصي 0M و 5M لـ Colomapping Min و Max.
والثاني يسمح بتصور مباشر للبطانة. سيستخدم هذا البرنامج النصي خرائط العمق المخبأة إذا كان ذلك متاحًا ، وإلا فإنه سيستخدم النموذج للتنبؤ بها قبل الانصهار. سيتم تحميل البرنامج النصي بشكل متكرر في خريطة عمق ، ودمجه ، وحفظ ملف شبكة في هذه الخطوة ، وتقديم هذه الشبكة إلى جانب علامة الكاميرا لمقطع فيديو BirdSeye ، ومن وجهة نظر الكاميرا لمقطع فيديو FPV.
# Example command to get live visualizations for mesh reconstruction
CUDA_VISIBLE_DEVICES=0 python visualize_live_meshing.py --name HERO_MODEL
--output_base_path OUTPUT_PATH
--config_file configs/models/hero_model.yaml
--load_weights_from_checkpoint weights/hero_model.ckpt
--data_config configs/data/scannet_dense_test.yaml
--num_workers 8 ; بشكل افتراضي ، سيقوم البرنامج النصي بحفظ الشبكات في موقع وسيطة ، ويمكنك اختياريًا تحميل هذه الشبكات لتوفير الوقت عند تصور نفس الشبكات مرة أخرى عن طريق تمرير --use_precomputed_partial_meshes . يجب أن يتم حساب جميع الشبكات الوسيطة في المدى السابق حتى يعمل هذا.
tl ؛ Dr: world_T_cam == world_from_cam
يستخدم هذا الريبو تدوين "cam_t_world" للدلالة على التحول من نقاط العالم إلى نقاط الكاميرا (علم خارجية). القصد من ذلك هو صنعه بحيث تتطابق أسماء الإطارات الإحداثي على جانبي المتغير عند استخدامها في الضرب من اليمين إلى اليسار :
cam_points = cam_T_world @ world_points
يشير world_T_cam إلى الكاميرا (من CAM إلى World Coords). يشير ref_T_src إلى تحول من مصدر إلى عرض مرجعي.
أخيرًا ، يسمح هذا التدوين بتمثيل كل من التناوب والترجمات مثل: world_R_cam و world_t_cam
تم توجيه هذا الريبو نحو السجل ، لذلك على الرغم من أن وظيفته يجب أن تسمح بأي نظام إحداثيات (يشير إلى علامات الإدخال) ، فإن الأوزان النموذجية التي نقدمها تفترض نظام إحداثيات سفن. هذا أمر مهم لأننا ندرج معلومات الشعاع كجزء من البيانات الوصفية. يجب تحويل مجموعات البيانات الأخرى المستخدمة مع هذه الأوزان إلى نظام السجل. ستعمل فئات مجموعة البيانات التي ندرجها على التحويلات المناسبة.
هناك عدد قليل من الأخطاء التي تم تناولها في هذا التحديث ، ستحتاج إلى تحديث شوكاتك واستخدام أوزان جديدة من الجدول بالقرب من بداية هذا القراءة. ستحتاج أيضًا إلى التأكد من أن لديك الملفات الجوهرية الصحيحة المستخرجة باستخدام القارئ.
بفضل كل الذين أشاروا إلى ذلك وكانوا صبورًا أثناء عملنا على الإصلاحات.
جميع الدرجات تتحسن مع هذه الإصلاحات ، ويتم تحميل الأوزان المرتبطة هنا. للحصول على الدرجات القديمة والرمز والأوزان ، تحقق من تجزئة الالتزام: 7DE5B451E340F9A11C7FD67BD0C42204D0B009A9
درجات كاملة للطرز مع إصلاحات الأخطاء:
عمق
--config | ABS Diff ↓ | ABS REL ↓ | SQ REL ↓ | RMSE ↓ | سجل RMSE ↓ | دلتا <1.05 ↑ | دلتا <1.10 ↑ |
|---|---|---|---|---|---|---|---|
hero_model.yaml ، بيانات التعريف + Resnet | 0.0868 | 0.0428 | 0.0127 | 0.1472 | 0.0681 | 74.26 | 90.88 |
dot_product_model.yaml ، منتج DOT + RESNET | 0.0910 | 0.0453 | 0.0134 | 0.1509 | 0.0704 | 71.90 | 89.75 |
شبكة الانصهار
--config | ACC ↓ | شركات ↓ | Chamfer ↓ | أذكر ↑ | الدقة ↑ | F-Score ↑ |
|---|---|---|---|---|---|---|
hero_model.yaml ، بيانات التعريف + Resnet | 5.41 | 5.98 | 5.69 | 0.695 | 0.668 | 0.680 |
dot_product_model.yaml ، منتج DOT + RESNET | 5.66 | 6.18 | 5.92 | 0.682 | 0.655 | 0.667 |
مقارنة:
--config | نموذج | ABS Diff ↓ | SQ REL ↓ | دلتا <1.05 ↑ | Chamfer ↓ | F-Score ↑ |
|---|---|---|---|---|---|---|
hero_model.yaml | Metadata + Resnet مطابقة | 0.0868 | 0.0127 | 74.26 | 5.69 | 0.680 |
Old hero_model.yaml | Metadata + Resnet مطابقة | 0.0885 | 0.0125 | 73.16 | 5.81 | 0.671 |
dot_product_model.yaml | منتج DOT + مطابقة RESNET | 0.0910 | 0.0134 | 71.90 | 5.92 | 0.667 |
Old dot_product_model.yaml | منتج DOT + مطابقة RESNET | 0.0941 | 0.0139 | 70.48 | 6.29 | 0.642 |
في البداية ، يقوم هذا REPO بتجميع ملفات tuple لإطارات مفاتيح نمط DVMVS الافتراضية مع 9 إطار إضافي قدره 25599 لمجموعة اختبار scannetv2. كان هناك خطأ بسيط مع التعامل مع التتبع المفقود الذي تم إصلاحه الآن. يجب أن يحاكي هذا الريبو الآن المخزن المؤقت لـ DVMVS Keyframe تمامًا ، مع إطارات مفتاحية 25590 للاختبار. كان التأثير الوحيد الذي كان لهذا الخطأ هو إدراج 9 إطارات إضافية ، وكانت جميع tuples الأخرى هي نفسها بالضبط مثل DVMVs. الإطارات المخالفة في هذه الفحص
scan previous count new count
--------------------------------------
scene0711_00 393 392
scene0727_00 209 208
scene0736_00 1023 1022
scene0737_00 408 407
scene0751_00 165 164
scene0775_00 220 219
scene0791_00 227 226
scene0794_00 141 140
scene0795_00 102 101
تم تحديث ملفات tuple للاختبار الافتراضي. نظرًا لأن هذا فرق صغير (~ 3e-4) في الإطارات الإضافية المسجلة ، فإن الدرجات لم تتغير.
TL ؛ DR: قم بتوسيع نطاقه واختصر صورك.
نحن نقوم بتوفير dataloader لتحميل الصور من إعادة الإعمار المتفرق. لكي يعمل هذا مع SimplerEcon ، ستحتاج إلى اقتصاص صورك لمطابقة FOV of Scannet (تشبه تقريبًا FOV الخاص بـ iPhone في وضع الفيديو) ، وتوسيع نطاق موقع Pose الخاص بك باستخدام قياسات العالم الحقيقية المعروفة. إذا لم يتم اتخاذ هذه الخطوات ، فلن يتم بناء حجم التكلفة بشكل صحيح ، ولن تقدر الشبكة عمقًا بشكل صحيح.
نشكر Aljaž Božič من Transformerfusion و Jiaming Sun of Neural Recon و Arda Düzçeker من DeepVideomvs على توفير معلومات مفيدة للمساعدة في خطوط الأساس ولجعلها متوفرة بسهولة ، خاصة في إشعار قصير.
تستخدم البرامج النصية لتوليد Tuple نسخة مكثفة من نسخة معدلة من العازلة الرئيسية لـ DeepVideomvs (شكرًا مرة أخرى Arda and Co!).
يتم استعارة وحدة Pytorch Point Cloud Fusion على رمز torch_point_cloud_fusion من ريبو 3DVnet. شكرا ألكساندر ريتش!
نود أيضًا أن نشكر فريق Niantic للبنية التحتية على الإجراءات السريعة عندما نحتاج إليها. شكرا يا رفاق!
يتم تمويل محمد من خلال منحة Microsoft Research PhD (MRL 2018-085).
إذا وجدت عملنا مفيدًا في بحثك ، فيرجى التفكير في ذكر ورقتنا:
@inproceedings{sayed2022simplerecon,
title={SimpleRecon: 3D Reconstruction Without 3D Convolutions},
author={Sayed, Mohamed and Gibson, John and Watson, Jamie and Prisacariu, Victor and Firman, Michael and Godard, Cl{'e}ment},
booktitle={Proceedings of the European Conference on Computer Vision (ECCV)},
year={2022},
}
حقوق الطبع والنشر © Niantic ، Inc. 2022. براءة اختراع معلقة. جميع الحقوق محفوظة. يرجى الاطلاع على ملف الترخيص للشروط.


