simplerecon
1.0.0
Ini adalah referensi implementasi pytorch untuk pelatihan dan pengujian model estimasi kedalaman MVS menggunakan metode yang dijelaskan dalam
Simplerecon: Rekonstruksi 3D tanpa Konvolusi 3D
Mohamed Sayed, John Gibson, Jamie Watson, Victor Adrian Prisacariu, Michael Firman, dan Clément Godard
Kertas, ECCV 2022 (ARXIV PDF), Materi Tambahan, Halaman Proyek, Video
Kode ini untuk penggunaan non-komersial; Silakan lihat file lisensi untuk persyaratan. Jika Anda menemukan bagian dari basis kode ini bermanfaat, silakan kutip kertas kami menggunakan Bibtex di bawah ini dan tautkan repo ini. Terima kasih!
25/05/2023: Memperbaiki Paket Verions untuk llvm-openmp , clang , dan protobuf . Gunakan file lingkungan baru ini jika Anda kesulitan menjalankan kode dan/atau jika dataloading terbatas pada satu utas.
09/03/2023: Menambahkan versi Kornia ke file lingkungan untuk memperbaiki masalah pengetikan Kornia. (terima kasih @natesimon!)
26/01/2023: Lisensi telah dimodifikasi untuk membuat menjalankan model karena alasan akademik lebih mudah. Harap file lisensi untuk detail yang tepat.
Ada pembaruan pada 31/12/2022 yang memperbaiki intrinsik yang sedikit salah, augmentasi flip untuk volume biaya, dan bug presisi numerik dalam proyeksi. Semua skor membaik. Anda perlu memperbarui garpu Anda dan menggunakan bobot baru. Lihat perbaikan bug.
Pemindaian pra-komputasi untuk frame default online ada di sini: https://drive.google.com/drive/folders/1dsofi9gayyhqjsx4i_ng0-3ebcafwxjv?usp=share_link
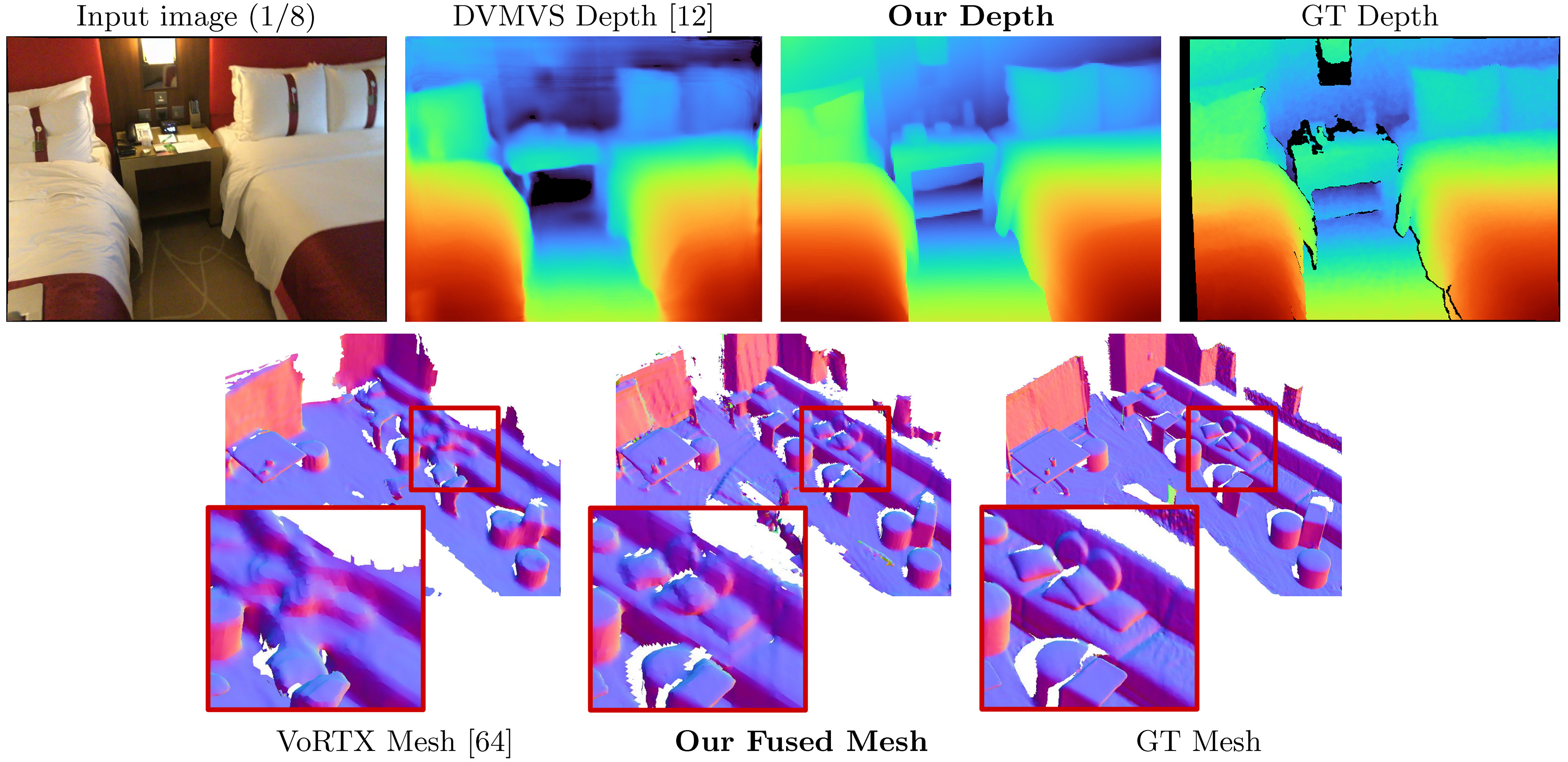
Simplerecon mengambil input yang ditimbulkan gambar RGB, dan mengeluarkan peta kedalaman untuk gambar target.
Dengan asumsi distribusi Anaconda yang segar, Anda dapat menginstal dependensi dengan:
conda env create -f simplerecon_env.ymlKami menjalankan eksperimen kami dengan Pytorch 1.10, Cuda 11.3, Python 3.9.7 dan Debian GNU/Linux 10.
Unduh model pretrained ke dalam weights/ folder.
Kami memberikan model berikut (skor dengan keyframe default online):
--config | Model | ABS Diff ↓ | SQ Rel ↓ | Delta <1.05 ↑ | Chamfer ↓ | F-score ↑ |
|---|---|---|---|---|---|---|
hero_model.yaml | Metadata + RESNET Pencocokan | 0,0868 | 0,0127 | 74.26 | 5.69 | 0.680 |
dot_product_model.yaml | Produk titik + pencocokan resnet | 0,0910 | 0,0134 | 71.90 | 5.92 | 0.667 |
hero_model adalah yang kami gunakan di koran sebagai milik kami
--config | Model | Kecepatan Inferensi ( --batch_size 1 ) | Memori GPU inferensi | Perkiraan waktu pelatihan |
|---|---|---|---|---|
hero_model | Pahlawan, Metadata + Resnet | 130ms / 70ms (kecepatan dioptimalkan) | 2.6GB / 5.7GB (kecepatan dioptimalkan) | 36 jam |
dot_product_model | Produk titik + resnet | 80ms | 2.6GB | 36 jam |
Dengan kecepatan batch yang lebih besar meningkat. Dengan ukuran batch 8 pada model yang dioptimalkan non-kecepatan, latensi turun menjadi ~ 40ms.
datasets/arkit_dataset.py . UPDATE: Sekarang ada Data_Scripts README CEPAT/IOS_LOGGER_ARKIT_README.MD untuk cara memproses dan menjalankan inferensi pemindaian iOS-logger menggunakan skrip di data_scripts/ios_logger_preprocessing.py . Kami sekarang telah menyertakan dua pemindaian untuk orang untuk segera mencoba dengan kode tersebut. Anda dapat mengunduh pemindaian ini dari sini.
Tangga:
hero_model ke direktori bobot.dataset_path di configs/data/vdr_dense.yaml ke jalur dasar folder VDR yang tidak di -zip.CUDA_VISIBLE_DEVICES=0 python test.py --name HERO_MODEL
--output_base_path OUTPUT_PATH
--config_file configs/models/hero_model.yaml
--load_weights_from_checkpoint weights/hero_model.ckpt
--data_config configs/data/vdr_dense.yaml
--num_workers 8
--batch_size 2
--fast_cost_volume
--run_fusion
--depth_fuser open3d
--fuse_color
--dump_depth_visualization ; Ini akan menghasilkan meshes, kedalaman cepat yaitu, dan Socres ketika dibandingkan dengan kedalaman lidar di bawah OUTPUT_PATH .
Perintah ini menggunakan vdr_dense.yaml yang akan menghasilkan kedalaman untuk setiap bingkai dan menggabungkannya ke dalam mesh. Dalam makalah kami melaporkan skor dengan bingkai kunci yang menyatu, dan Anda dapat menjalankannya menggunakan vdr_default.yaml . Anda juga dapat menggunakan tupel dense_offline dengan menggunakan vdr_dense_offline.yaml .
Lihat bagian di bawah tentang pengujian dan evaluasi. Pastikan untuk menggunakan bendera konfigurasi yang benar untuk set data.
Silakan ikuti instruksi di sini untuk mengunduh dataset. Dataset ini cukup besar (> 2TB), jadi pastikan Anda memiliki ruang yang cukup, terutama untuk mengekstraksi file.
Setelah diunduh, gunakan skrip ini untuk mengekspor data sensor mentah ke gambar dan file kedalaman.
Kami telah menulis tutorial singkat dan menyertakan skrip yang dimodifikasi untuk membantu Anda mengunduh dan mengekstraksi ScannetV2. Anda dapat menemukannya di data_scripts/scannet_wrangling_scripts/
Anda harus mengubah argumen konfigurasi dataset_path untuk konfigurasi data scannetv2 di configs/data/ agar sesuai dengan di mana dataset Anda berada.
Basis kode mengharapkan scannetV2 berada dalam format berikut:
dataset_path
scans_test (test scans)
scene0707
scene0707_00_vh_clean_2.ply (gt mesh)
sensor_data
frame-000261.pose.txt
frame-000261.color.jpg
frame-000261.color.512.png (optional, image at 512x384)
frame-000261.color.640.png (optional, image at 640x480)
frame-000261.depth.png (full res depth, stored scale *1000)
frame-000261.depth.256.png (optional, depth at 256x192 also
scaled)
scene0707.txt (scan metadata and image sizes)
intrinsic
intrinsic_depth.txt
intrinsic_color.txt
...
scans (val and train scans)
scene0000_00
(see above)
scene0000_01
....
Dalam contoh ini scene0707.txt harus berisi metadata pemindaian:
colorHeight = 968
colorToDepthExtrinsics = 0.999263 -0.010031 0.037048 ........
colorWidth = 1296
depthHeight = 480
depthWidth = 640
fx_color = 1170.187988
fx_depth = 570.924255
fy_color = 1170.187988
fy_depth = 570.924316
mx_color = 647.750000
mx_depth = 319.500000
my_color = 483.750000
my_depth = 239.500000
numColorFrames = 784
numDepthFrames = 784
numIMUmeasurements = 1632
frame-000261.pose.txt harus berisi pose dalam bentuk:
-0.384739 0.271466 -0.882203 4.98152
0.921157 0.0521417 -0.385682 1.46821
-0.0587002 -0.961035 -0.270124 1.51837
frame-000261.color.512.png dan frame-000261.color.640.png adalah versi yang diubah ukurannya dari gambar asli untuk menghemat beban dan menghitung waktu selama pelatihan dan pengujian. frame-000261.depth.256.png juga merupakan versi yang diubah ukurannya dari peta kedalaman.
Semua versi kedalaman dan gambar yang diubah ukurannya bagus untuk dimiliki tetapi tidak diperlukan. Jika tidak ada, versi resolusi penuh akan dimuat, dan downsampled dengan cepat.
Secara default, kami memperkirakan peta kedalaman untuk setiap batasan kunci dalam pemindaian. Kami menggunakan heuristik DeepVideoMVS untuk pemisahan bingkai kunci dan membangun tupel agar cocok. Kami menggunakan peta kedalaman pada kerangka kunci ini untuk fusi kedalaman. Untuk setiap Kunci Kunci, kami mengaitkan daftar bingkai sumber yang akan digunakan untuk membangun volume biaya. Kami juga menggunakan tupel padat, di mana kami memprediksi peta kedalaman untuk setiap bingkai dalam data, dan tidak hanya pada kerangka kunci tertentu; Ini sebagian besar digunakan untuk visualisasi.
Kami menghasilkan dan mengekspor daftar tupel di semua pemindaian yang bertindak sebagai elemen dataset. Kami telah menghitung daftar ini dan tersedia di data_splits di bawah setiap perpecahan dataset. Untuk pemindaian uji Scannet, mereka berada di data_splits/ScanNetv2/standard_split . Angka kedalaman inti kami dihitung menggunakan data_splits/ScanNetv2/standard_split/test_eight_view_deepvmvs.txt .
Berikut adalah Taxonamy cepat dari jenis tupel untuk diuji:
default : Tuple untuk setiap Kunci Kunci Mengikuti DeepVideoVs di mana semua bingkai sumber berada di masa lalu. Digunakan untuk semua evaluasi kedalaman dan mesh kecuali dinyatakan sebaliknya. Untuk scannet gunakan data_splits/ScanNetv2/standard_split/test_eight_view_deepvmvs.txt .offline : Tuple untuk setiap bingkai dalam pemindaian di mana bingkai sumber dapat menjadi baik di masa lalu dan masa depan relatif terhadap bingkai saat ini. Ini berguna ketika sebuah adegan ditangkap secara offline, dan Anda menginginkan akurasi terbaik. Dengan tupel online, volume biaya akan berisi daerah kosong saat kamera bergerak dan semua bingkai sumber tertinggal; Namun dengan tupel offline, volume biaya penuh di kedua ujungnya, yang mengarah ke estimasi skala yang lebih baik (dan metrik).dense : Tuple online (seperti default) untuk setiap bingkai dalam pemindaian di mana semua bingkai sumber berada di masa lalu. Untuk scannet ini adalah data_splits/ScanNetv2/standard_split/test_eight_view_deepvmvs_dense.txt .offline : Tuple offline untuk setiap keyframe atau setiap batasan kunci dalam pemindaian.Untuk set kereta dan validasi, kami mengikuti strategi augmentasi tuple yang sama seperti di DeepVideo dan menggunakan skrip generasi inti yang sama.
Jika Anda ingin menghasilkan tupel ini sendiri, Anda dapat menggunakan skrip di data_scripts/generate_train_tuples.py untuk tupel kereta dan data_scripts/generate_test_tuples.py untuk tupel uji. Ini mengikuti format konfigurasi yang sama dengan test.py dan akan menggunakan kelas dataset apa pun yang Anda buat untuk membaca Pose Informaiton.
Contoh untuk tes:
# default tuples
python ./data_scripts/generate_test_tuples.py
--data_config configs/data/scannet_default_test.yaml
--num_workers 16
# dense tuples
python ./data_scripts/generate_test_tuples.py
--data_config configs/data/scannet_dense_test.yaml
--num_workers 16Contoh untuk kereta:
# train
python ./data_scripts/generate_train_tuples.py
--data_config configs/data/scannet_default_train.yaml
--num_workers 16
# val
python ./data_scripts/generate_val_tuples.py
--data_config configs/data/scannet_default_val.yaml
--num_workers 16 Script ini pertama -tama akan memeriksa setiap bingkai dalam dataset untuk memastikan memiliki bingkai RGB yang ada, bingkai kedalaman yang ada (jika sesuai untuk dataset), dan juga file pose yang ada dan valid. Ini akan menyimpan valid_frames ini dalam file teks di setiap folder pemindaian, tetapi jika direktori hanya dibaca, itu akan mengabaikan menyimpan file valid_frames dan menghasilkan tupel.
Anda dapat menggunakan test.py untuk menyimpulkan dan mengevaluasi peta kedalaman dan menyatu.
Semua hasil akan disimpan di folder hasil dasar (result_path) di:
opts.output_base_path/opts.name/opts.dataset/opts.frame_tuple_type/
di mana opts adalah kelas options . Misalnya, saat opts.output_base_path adalah ./results , opts.name adalah HERO_MODEL , opts.dataset adalah scannet , dan opts.frame_tuple_type default , direktori output akan
./results/HERO_MODEL/scannet/default/
Pastikan untuk mengatur --opts.output_base_path ke direktori yang cocok untuk Anda menyimpan hasil.
--frame_tuple_type adalah jenis tuple gambar yang digunakan untuk MVS. Pilihan harus disediakan dalam file data_config yang Anda gunakan.
Secara default test.py akan mencoba menghitung skor kedalaman untuk setiap bingkai dan memberikan rangka bingkai dan adegan rata -rata metrik. Script akan menyimpan skor ini (per adegan dan total) di bawah results_path/scores .
Kami telah melakukan yang terbaik untuk memastikan bahwa bug batching obor melalui encoder yang cocok diperbaiki untuk (<10^-4) pengujian yang akurat dengan menonaktifkan batching gambar melalui encoder itu. Jalankan --batch_size 4 paling banyak jika diragukan, dan jika Anda ingin menjadi stabil sebagaimana dimungkinkan dan menghindari gremlin pytorch, gunakan --batch_size 1 untuk evaluasi perbandingan.
Jika Anda ingin menggunakan ini untuk kecepatan, atur --fast_cost_volume ke true. Ini akan memungkinkan batching melalui encoder yang cocok dan akan memungkinkan volume fitur yang dioptimalkan Einops.
# Example command to just compute scores
CUDA_VISIBLE_DEVICES=0 python test.py --name HERO_MODEL
--output_base_path OUTPUT_PATH
--config_file configs/models/hero_model.yaml
--load_weights_from_checkpoint weights/hero_model.ckpt
--data_config configs/data/scannet_default_test.yaml
--num_workers 8
--batch_size 4 ;
# If you'd like to get a super fast version use:
CUDA_VISIBLE_DEVICES=0 python test.py --name HERO_MODEL
--output_base_path OUTPUT_PATH
--config_file configs/models/hero_model.yaml
--load_weights_from_checkpoint weights/hero_model.ckpt
--data_config configs/data/scannet_default_test.yaml
--num_workers 8
--fast_cost_volume
--batch_size 2 ;Skrip ini juga dapat digunakan untuk melakukan beberapa tugas tambahan yang berbeda, termasuk:
TSDF Fusion
Untuk menjalankan TSDF Fusion menyediakan bendera --run_fusion . Anda memiliki dua pilihan untuk Fusers
--depth_fuser ours (default) akan menggunakan fuser kami, yang jeratnya digunakan di sebagian besar visualisasi dan untuk skor. Fuser ini tidak mendukung warna. Kami telah menyediakan cabang kustom scikit-image dengan implementasi khusus dari measure.matching_cubes yang memungkinkan satu dinding. Kami menggunakan jerat berdinding tunggal untuk evaluasi. Jika ini tidak penting bagi Anda, Anda dapat mengatur export_single_mesh ke False untuk panggilan ke export_mesh di test.py--depth_fuser open3d akan menggunakan fuser kedalaman open3d. Fuser ini mendukung warna dan Anda dapat mengaktifkannya dengan menggunakan bendera --fuse_color . Secara default, peta kedalaman akan dipotong hingga 3m untuk fusi dan resolusi TSDF 0,04m 3 akan digunakan, tetapi Anda dapat mengubahnya dengan mengubah keduanya --max_fusion_depth dan --fusion_resolution
Anda dapat secara opsional meminta kedalaman yang diprediksi yang digunakan untuk Fusion untuk ditutupi ketika tidak ada informasi MVS VAIID yang ada menggunakannya --mask_pred_depths . Ini tidak diaktifkan secara default.
Anda juga dapat menggabungkan kedalaman tebakan terbaik dari volume biaya sebelum volume biaya encoder-dekoder yang memperkenalkan citra yang kuat sebelumnya. Anda dapat melakukan ini dengan menggunakan --fusion_use_raw_lowest_cost .
Meshes akan disimpan di bawah results_path/meshes/ .
# Example command to fuse depths to get meshes
CUDA_VISIBLE_DEVICES=0 python test.py --name HERO_MODEL
--output_base_path OUTPUT_PATH
--config_file configs/models/hero_model.yaml
--load_weights_from_checkpoint weights/hero_model.ckpt
--data_config configs/data/scannet_default_test.yaml
--num_workers 8
--run_fusion
--batch_size 8 ;Kedalaman cache
Anda secara opsional dapat menyimpan kedalaman dengan menyediakan bendera --cache_depths . Mereka akan disimpan di results_path/depths .
# Example command to compute scores and cache depths
CUDA_VISIBLE_DEVICES=0 python test.py --name HERO_MODEL
--output_base_path OUTPUT_PATH
--config_file configs/models/hero_model.yaml
--load_weights_from_checkpoint weights/hero_model.ckpt
--data_config configs/data/scannet_default_test.yaml
--num_workers 8
--cache_depths
--batch_size 8 ;
# Example command to fuse depths to get color meshes
CUDA_VISIBLE_DEVICES=0 python test.py --name HERO_MODEL
--output_base_path OUTPUT_PATH
--config_file configs/models/hero_model.yaml
--load_weights_from_checkpoint weights/hero_model.ckpt
--data_config configs/data/scannet_default_test.yaml
--num_workers 8
--run_fusion
--depth_fuser open3d
--fuse_color
--batch_size 4 ;Kaum cepat
Ada skrip lain untuk visualisasi yang lebih dalam dari kedalaman dan fusi output, tetapi untuk ekspor cepat visualisasi peta kedalaman yang dapat Anda gunakan --dump_depth_visualization . Visualisasi akan disimpan di results_path/viz/quick_viz/ .
# Example command to output quick depth visualizations
CUDA_VISIBLE_DEVICES=0 python test.py --name HERO_MODEL
--output_base_path OUTPUT_PATH
--config_file configs/models/hero_model.yaml
--load_weights_from_checkpoint weights/hero_model.ckpt
--data_config configs/data/scannet_default_test.yaml
--num_workers 8
--dump_depth_visualization
--batch_size 4 ; Kami juga memungkinkan fusi awan titik peta kedalaman menggunakan fuser dari repo 3DVNet.
# Example command to fuse depths into point clouds.
CUDA_VISIBLE_DEVICES=0 python pc_fusion.py --name HERO_MODEL
--output_base_path OUTPUT_PATH
--config_file configs/models/hero_model.yaml
--load_weights_from_checkpoint weights/hero_model.ckpt
--data_config configs/data/scannet_dense_test.yaml
--num_workers 8
--batch_size 4 ; Ubah configs/data/scannet_dense_test.yaml ke configs/data/scannet_default_test.yaml untuk menggunakan keyframe hanya jika Anda tidak ingin menunggu terlalu lama.
Kami menggunakan evaluasi jala TransformerFusion untuk tabel hasil utama kami tetapi atur benih ke nilai tetap untuk konsistensi ketika sampel secara acak. Kami juga melaporkan metrik mesh menggunakan evaluasi NeuralRecon dalam materi tambahan.
Untuk evaluasi cloud titik, kami menggunakan kode TransformerFusion tetapi memuat di titik cloud sebagai pengganti pengambilan sampel permukaan mesh.
Secara default model dan file acara tensorboard disimpan ke ~/tmp/tensorboard/<model_name> . Ini dapat diubah dengan bendera --log_dir .
Kami berlatih dengan batch_size 16 dengan presisi 16-bit pada dua A100 pada split scannetv2 default.
Contoh perintah untuk berlatih dengan dua GPU:
CUDA_VISIBLE_DEVICES=0,1 python train.py --name HERO_MODEL
--log_dir logs
--config_file configs/models/hero_model.yaml
--data_config configs/data/scannet_default_train.yaml
--gpus 2
--batch_size 16 ; Kode mendukung sejumlah GPU untuk pelatihan. Anda dapat menentukan GPU mana yang akan digunakan dengan lingkungan CUDA_VISIBLE_DEVICES .
Semua pelatihan kami dilakukan pada dua NVIDIA A100.
Dataset yang berbeda
Anda dapat berlatih pada dataset MVS khusus dengan menulis kelas Dataloader baru yang mewarisi dari GenericMVSDataset di datasets/generic_mvs_dataset.py . Lihat kelas ScannetDataset dalam datasets/scannet_dataset.py atau bahkan kelas lain dalam datasets untuk contoh.
Untuk finetune, memuat pos pemeriksaan sederhana (bukan resume!) Dan berlatih dari sana:
CUDA_VISIBLE_DEVICES=0 python train.py --config configs/models/hero_model.yaml
--data_config configs/data/scannet_default_train.yaml
--load_weights_from_checkpoint weights/hero_model.ckptUbah konfigurasi data ke dataset apa pun yang ingin Anda lakukan.
Lihat options.py untuk berbagai opsi pelatihan lainnya, seperti tingkat pembelajaran dan pengaturan ablasi, dan opsi pengujian.
Selain visualisasi kedalaman cepat dalam skrip test.py , ada dua skrip untuk memvisualisasikan output kedalaman.
Yang pertama adalah visualization_scripts/visualize_scene_depth_output.py . Ini akan menghasilkan video dengan gambar warna dari referensi dan bingkai sumber, prediksi kedalaman, estimasi volume biaya, kedalaman GT, dan perkiraan normals dari kedalaman. Script mengasumsikan Anda memiliki output kedalaman cache menggunakan test.py dan menerima format template perintah yang sama seperti test.py :
# Example command to get visualizations for dense frames
CUDA_VISIBLE_DEVICES=0 python ./visualization_scripts/visualize_scene_depth_output.py --name HERO_MODEL
--output_base_path OUTPUT_PATH
--data_config configs/data/scannet_dense_test.yaml
--num_workers 8 ; di mana OUTPUT_PATH adalah direktori hasil dasar untuk Simplerecon (apa yang Anda gunakan untuk tes untuk memulai). Anda secara opsional dapat menjalankan .visualization_scripts/generate_gt_min_max_cache.py sebelum skrip ini untuk mendapatkan rata -rata adegan untuk nilai kedalaman min dan maks yang digunakan untuk colormapping; Jika itu tidak tersedia, skrip akan menggunakan 0m dan 5m untuk colomapping min dan max.
Yang kedua memungkinkan visualisasi hidup meshing. Skrip ini akan menggunakan peta kedalaman cache jika tersedia, jika tidak, ia akan menggunakan model untuk memprediksinya sebelum fusi. Script akan memuat secara iteratif di peta kedalaman, menggabungkannya, menyimpan file mesh pada langkah ini, dan membuat jala ini di samping penanda kamera untuk video Birdseye, dan dari sudut pandang kamera untuk video FPV.
# Example command to get live visualizations for mesh reconstruction
CUDA_VISIBLE_DEVICES=0 python visualize_live_meshing.py --name HERO_MODEL
--output_base_path OUTPUT_PATH
--config_file configs/models/hero_model.yaml
--load_weights_from_checkpoint weights/hero_model.ckpt
--data_config configs/data/scannet_dense_test.yaml
--num_workers 8 ; Secara default skrip akan menyimpan jerat ke lokasi perantara, dan Anda dapat secara opsional memuat jerat itu untuk menghemat waktu ketika memvisualisasikan jerat yang sama lagi dengan melewati --use_precomputed_partial_meshes . Semua jerat menengah harus dihitung pada menjalankan sebelumnya agar ini berfungsi.
Tl; dr: world_T_cam == world_from_cam
Repo ini menggunakan notasi "cam_t_world" untuk menunjukkan transformasi dari dunia ke titik kamera (ekstrinsik). Tujuannya adalah untuk membuatnya sehingga nama bingkai koordinat akan cocok di kedua sisi variabel ketika digunakan dalam perkalian dari kanan ke kiri :
cam_points = cam_T_world @ world_points
world_T_cam menunjukkan pose kamera (dari cam ke coords dunia). ref_T_src menunjukkan transformasi dari sumber ke tampilan referensi.
Akhirnya notasi ini memungkinkan untuk mewakili rotasi dan terjemahan seperti: world_R_cam dan world_t_cam
Repo ini diarahkan untuk scannet, jadi sementara fungsinya harus memungkinkan untuk setiap sistem koordinat (ditandai melalui bendera input), bobot model yang kami berikan mengasumsikan sistem koordinat scannet. Ini penting karena kami memasukkan informasi sinar sebagai bagian dari metadata. Kumpulan data lain yang digunakan dengan bobot ini harus diubah ke sistem pemindaian. Kelas dataset yang kami sertakan akan melakukan transformasi yang sesuai.
Ada beberapa bug yang dibahas dalam pembaruan ini, Anda perlu memperbarui garpu Anda dan menggunakan bobot baru dari meja di dekat awal Readme ini. Anda juga perlu memastikan Anda memiliki file intrinsik yang benar diekstraksi menggunakan pembaca.
Berkat semua yang menunjukkannya dan sabar saat kami mengerjakan perbaikan.
Semua skor meningkat dengan perbaikan ini, dan bobot terkait diunggah di sini. Untuk skor lama, kode, dan bobot, periksa hash komit ini: 7DE5B451E340F9A11C7FD67BD0C42204D0B009A9
Skor penuh untuk model dengan perbaikan bug:
Kedalaman
--config | ABS Diff ↓ | ABS REL ↓ | SQ Rel ↓ | RMSE ↓ | Log RMSE ↓ | Delta <1.05 ↑ | Delta <1,10 ↑ |
|---|---|---|---|---|---|---|---|
hero_model.yaml , metadata + resnet | 0,0868 | 0,0428 | 0,0127 | 0.1472 | 0,0681 | 74.26 | 90.88 |
dot_product_model.yaml , produk dot + resnet | 0,0910 | 0,0453 | 0,0134 | 0.1509 | 0,0704 | 71.90 | 89.75 |
Fusi jala
--config | ACC ↓ | Comp ↓ | Chamfer ↓ | Ingat ↑ | Presisi ↑ | F-score ↑ |
|---|---|---|---|---|---|---|
hero_model.yaml , metadata + resnet | 5.41 | 5.98 | 5.69 | 0.695 | 0.668 | 0.680 |
dot_product_model.yaml , produk dot + resnet | 5.66 | 6.18 | 5.92 | 0.682 | 0.655 | 0.667 |
Perbandingan:
--config | Model | ABS Diff ↓ | SQ Rel ↓ | Delta <1.05 ↑ | Chamfer ↓ | F-score ↑ |
|---|---|---|---|---|---|---|
hero_model.yaml | Metadata + RESNET Pencocokan | 0,0868 | 0,0127 | 74.26 | 5.69 | 0.680 |
Old hero_model.yaml | Metadata + RESNET Pencocokan | 0,0885 | 0,0125 | 73.16 | 5.81 | 0.671 |
dot_product_model.yaml | Produk titik + pencocokan resnet | 0,0910 | 0,0134 | 71.90 | 5.92 | 0.667 |
Old dot_product_model.yaml | Produk titik + pencocokan resnet | 0,0941 | 0,0139 | 70.48 | 6.29 | 0.642 |
Awalnya repo ini meludahkan file tuple untuk kerangka kunci gaya DVMVS default dengan 9 bingkai tambahan 25599 untuk set tes ScannetV2. Ada bug kecil dengan menangani pelacakan yang hilang yang sekarang sudah diperbaiki. Repo ini sekarang harus meniru buffer Keyframe DVMVS dengan tepat, dengan 25590 keyframe untuk pengujian. Satu -satunya efek bug ini adalah dimasukkannya 9 frame tambahan, semua tupel lainnya persis sama dengan DVMV. Bingkai yang menyinggung ada dalam pemindaian ini
scan previous count new count
--------------------------------------
scene0711_00 393 392
scene0727_00 209 208
scene0736_00 1023 1022
scene0737_00 408 407
scene0751_00 165 164
scene0775_00 220 219
scene0791_00 227 226
scene0794_00 141 140
scene0795_00 102 101
File tuple untuk tes default telah diperbarui. Karena ini adalah perbedaan kecil (~ 3E-4) dalam skor bingkai tambahan, skor tidak berubah.
TL; DR: Skala pose Anda dan potong gambar Anda.
Kami menyediakan dataloader untuk memuat gambar dari rekonstruksi jarang colmap. Agar ini bekerja dengan SimpleRecon, Anda harus memotong gambar Anda agar sesuai dengan FOV scannet (kira -kira mirip dengan FOV iPhone dalam mode video), dan skala lokasi pose Anda menggunakan pengukuran dunia nyata yang dikenal. Jika langkah -langkah ini tidak diambil, volume biaya tidak akan dibangun dengan benar, dan jaringan tidak akan memperkirakan kedalaman dengan benar.
Kami berterima kasih kepada Aljaž Božič dari TransformerFusion, Jiaming Sun of Neural Recon, dan Arda Düzçer dari DeepVideoD karena dengan cepat memberikan informasi yang berguna untuk membantu baseline dan untuk membuat basis kode mereka tersedia, terutama dalam waktu singkat.
Skrip generasi tuple memanfaatkan versi yang dimodifikasi dari buffer keyframe DeepVideoMVS (terima kasih lagi Arda dan CO!).
Modul Fusi Cloud Pytorch Point di torch_point_cloud_fusion Code dipinjam dari repo 3DVNET. Terima kasih Alexander Rich!
Kami juga ingin mengucapkan terima kasih kepada tim infrastruktur Niantic untuk tindakan cepat saat kami membutuhkannya. Terima kasih teman -teman!
Mohamed didanai oleh Beasiswa PhD Microsoft Research (MRL 2018-085).
Jika Anda menemukan pekerjaan kami berguna dalam penelitian Anda, pertimbangkan untuk mengutip makalah kami:
@inproceedings{sayed2022simplerecon,
title={SimpleRecon: 3D Reconstruction Without 3D Convolutions},
author={Sayed, Mohamed and Gibson, John and Watson, Jamie and Prisacariu, Victor and Firman, Michael and Godard, Cl{'e}ment},
booktitle={Proceedings of the European Conference on Computer Vision (ECCV)},
year={2022},
}
Hak Cipta © Niantic, Inc. 2022. Paten tertunda. Semua hak dilindungi undang -undang. Silakan lihat file lisensi untuk persyaratan.


