simplerecon
1.0.0
Esta é a implementação de referência de Pytorch para treinamento e teste de modelos de estimativa de profundidade do MVS usando o método descrito em
SimplereCon: reconstrução 3D sem convoluções 3D
Mohamed Sayed, John Gibson, Jamie Watson, Victor Adrian Prisacariu, Michael Firman e Clément Godard
Artigo, ECCV 2022 (arxiv pdf), material suplementar, página do projeto, vídeo
Este código é para uso não comercial; Consulte o arquivo de licença para termos. Se você encontrar alguma parte desta base de código útil, cite nosso artigo usando o Bibtex abaixo e vincule este repositório. Obrigado!
25/05/2023: Verões de embalagem corrigidas para llvm-openmp , clang e protobuf . Use este novo arquivo de ambiente se tiver problemas para executar o código e/ou se o Dataloading estiver sendo limitado a um único thread.
03/09/2023: Adicionada versão Kornia ao arquivo Ambiente para corrigir o problema de digitação de Kornia. (Obrigado @natesimon!)
26/01/2023: A licença foi modificada para facilitar a execução do modelo por razões acadêmicas. Por favor, o arquivo de licença para obter os detalhes exatos.
Há uma atualização a partir de 31/12/2022 que corrige o Intrinsics Intrinsetos um pouco errados, o aumento do flip para o volume de custo e um bug de precisão numérica na projeção. Todas as pontuações melhoram. Você precisará atualizar seus garfos e usar novos pesos. Veja correções de bug.
As varreduras pré-computadas para os quadros padrão on-line estão aqui: https://drive.google.com/drive/folders/1dofi9gayyhqjsx4i_ng0-3ebcafwxjv?usp=share_link
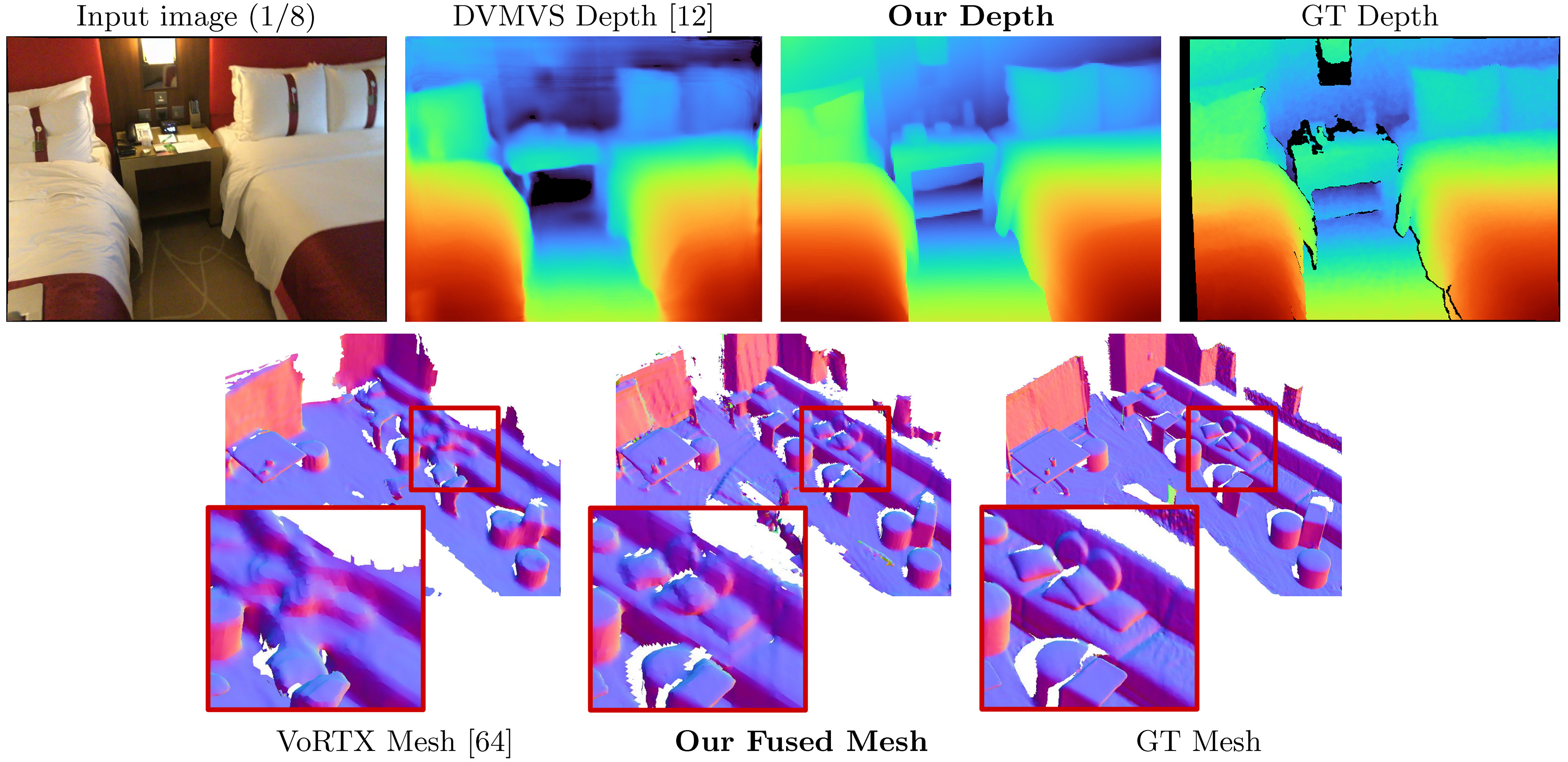
O SimpleReCon toma como entrada colocou imagens RGB e produz um mapa de profundidade para uma imagem de destino.
Assumindo uma nova distribuição da Anaconda, você pode instalar dependências com:
conda env create -f simplerecon_env.ymlExecutamos nossos experimentos com Pytorch 1.10, CUDA 11.3, Python 3.9.7 e Debian GNU/Linux 10.
Faça o download de um modelo pré -terenciado no weights/ pasta.
Fornecemos os seguintes modelos (as pontuações são com quadros -chave padrão on -line):
--config | Modelo | ABS DIFF ∞ | SQ Rel ↓ | delta <1,05 ↑ | Chanfro ↓ | F-score ↑ |
|---|---|---|---|---|---|---|
hero_model.yaml | Metadados + Resnet correspondência | 0,0868 | 0,0127 | 74.26 | 5.69 | 0,680 |
dot_product_model.yaml | DOT PRODUTO + COMPRIMENTO DE RESNET | 0,0910 | 0,0134 | 71.90 | 5.92 | 0,667 |
hero_model é o que usamos no artigo como o nosso
--config | Modelo | Velocidade de inferência ( --batch_size 1 ) | Memória da GPU de inferência | Tempo de treinamento aproximado |
|---|---|---|---|---|
hero_model | Herói, metadados + resnet | 130ms / 70ms (velocidade otimizada) | 2,6 GB / 5,7 GB (otimização da velocidade) | 36 horas |
dot_product_model | Produto DOT + Resnet | 80ms | 2,6 GB | 36 horas |
Com lotes maiores, a velocidade aumenta consideravelmente. Com o tamanho 8 do lote no modelo otimizado sem velocidade, a latência cai para ~ 40ms.
datasets/arkit_dataset.py . ATUALIZAÇÃO: Agora existe um README DATA_SCRIPTS/IOS_LOGGER_ARKIT_README.MD para como processar e executar uma verificação de inferência Uma verificação iOS usando o script em data_scripts/ios_logger_preprocessing.py . Agora incluímos duas varreduras para as pessoas experimentarem imediatamente com o código. Você pode baixar essas varreduras daqui.
Passos:
hero_model no diretório de pesos.dataset_path em configs/data/vdr_dense.yaml no caminho base da pasta VDR desconfiada.CUDA_VISIBLE_DEVICES=0 python test.py --name HERO_MODEL
--output_base_path OUTPUT_PATH
--config_file configs/models/hero_model.yaml
--load_weights_from_checkpoint weights/hero_model.ckpt
--data_config configs/data/vdr_dense.yaml
--num_workers 8
--batch_size 2
--fast_cost_volume
--run_fusion
--depth_fuser open3d
--fuse_color
--dump_depth_visualization ; Isso produzirá malhas, profundidade rápida e socres quando comparado com a profundidade do LIDAR sob OUTPUT_PATH .
Este comando usa vdr_dense.yaml , que gerará profundidades para cada quadro e os fundem em uma malha. No artigo, relatamos pontuações com os quadros -chave fundidos e você pode executar aqueles que usam vdr_default.yaml . Você também pode usar tuplas dense_offline usando vdr_dense_offline.yaml .
Consulte a seção abaixo sobre teste e avaliação. Certifique -se de usar os sinalizadores de configuração corretos para conjuntos de dados.
Siga as instruções aqui para baixar o conjunto de dados. Esse conjunto de dados é bastante grande (> 2TB); portanto, verifique se você tem espaço suficiente, especialmente para extrair arquivos.
Depois de baixado, use este script para exportar dados de sensores brutos para imagens e arquivos de profundidade.
Escrevemos um tutorial rápido e incluímos scripts modificados para ajudá -lo a fazer download e extrair scannetv2. Você pode encontrá -los em data_scripts/scannet_wrangling_scripts/
Você deve alterar o argumento de configuração dataset_path para configurações de dados Scannetv2 em configs/data/ para corresponder aonde seu conjunto de dados.
A base de código espera que o scannetv2 esteja no seguinte formato:
dataset_path
scans_test (test scans)
scene0707
scene0707_00_vh_clean_2.ply (gt mesh)
sensor_data
frame-000261.pose.txt
frame-000261.color.jpg
frame-000261.color.512.png (optional, image at 512x384)
frame-000261.color.640.png (optional, image at 640x480)
frame-000261.depth.png (full res depth, stored scale *1000)
frame-000261.depth.256.png (optional, depth at 256x192 also
scaled)
scene0707.txt (scan metadata and image sizes)
intrinsic
intrinsic_depth.txt
intrinsic_color.txt
...
scans (val and train scans)
scene0000_00
(see above)
scene0000_01
....
Neste exemplo, scene0707.txt deve conter os metadados da varredura:
colorHeight = 968
colorToDepthExtrinsics = 0.999263 -0.010031 0.037048 ........
colorWidth = 1296
depthHeight = 480
depthWidth = 640
fx_color = 1170.187988
fx_depth = 570.924255
fy_color = 1170.187988
fy_depth = 570.924316
mx_color = 647.750000
mx_depth = 319.500000
my_color = 483.750000
my_depth = 239.500000
numColorFrames = 784
numDepthFrames = 784
numIMUmeasurements = 1632
frame-000261.pose.txt deve conter pose no formulário:
-0.384739 0.271466 -0.882203 4.98152
0.921157 0.0521417 -0.385682 1.46821
-0.0587002 -0.961035 -0.270124 1.51837
frame-000261.color.512.png e frame-000261.color.640.png são versões redimensionadas precaches da imagem original para economizar tempo de carga e calcular o tempo durante o treinamento e o teste. frame-000261.depth.256.png também é uma versão redimensionada precached do mapa de profundidade.
Todas as versões precaches redimensionadas de profundidade e imagens são boas de ter, mas não são necessárias. Se eles não existirem, as versões de resolução completa serão carregadas e diminuíram a mosca.
Por padrão, estimamos um mapa de profundidade para cada quadro -chave em uma varredura. Usamos a heurística do DeepVideOMVs para a separação do quadro -chave e construímos tuplas para corresponder. Usamos os mapas de profundidade nesses quadros -chave para fusão de profundidade. Para cada quadro -chave, associamos uma lista de quadros de origem que serão usados para criar o volume de custo. Também usamos tuplas densas, onde prevemos um mapa de profundidade para cada quadro nos dados, e não apenas em quadros -chave específicos; Estes são usados principalmente para visualização.
Geramos e exportamos uma lista de tuplas em todas as varreduras que atuam como os elementos do conjunto de dados. Nós pré -computamos essas listas e elas estão disponíveis em data_splits sob a divisão de cada conjunto de dados. Para as varreduras de teste do Scannet, eles estão em data_splits/ScanNetv2/standard_split . Nossos números de profundidade do núcleo são calculados usando data_splits/ScanNetv2/standard_split/test_eight_view_deepvmvs.txt .
Aqui está uma taxonamia rápida do tipo de tuplas para teste:
default : uma tupla para cada quadro -chave seguindo DeepVideOMVs, onde todos os quadros de origem estão no passado. Usado para toda a avaliação de profundidade e malha, a menos que seja declarado o contrário. Para scannet, use data_splits/ScanNetv2/standard_split/test_eight_view_deepvmvs.txt .offline : uma tupla para cada quadro na varredura onde os quadros de origem podem ser no passado e no futuro em relação ao quadro atual. Isso é útil quando uma cena é capturada offline e você deseja a melhor precisão possível. Com tuplas on -line, o volume de custos conterá regiões vazias à medida que a câmera se afasta e todos os quadros de origem ficam para trás; No entanto, com tuplas offline, o volume de custo está cheio nas duas extremidades, levando a uma estimativa de melhor escala (e métrica).dense : uma tupla on -line (como padrão) para cada quadro da varredura onde todos os quadros de origem estão no passado. Para scannet, isso seria data_splits/ScanNetv2/standard_split/test_eight_view_deepvmvs_dense.txt .offline : uma tupla offline para cada quadro -chave para cada quadro de chave na varredura.Para os conjuntos de trem e validação, seguimos a mesma estratégia de aumento da tupla que em DeepVideOMVs e usamos o mesmo script de geração principal.
Se você quiser gerar essas tuplas, poderá usar os scripts em data_scripts/generate_train_tuples.py para treinar tuplas e data_scripts/generate_test_tuples.py para testar tuplos. Eles seguem o mesmo formato de configuração que test.py e usarão qualquer classe do conjunto de dados que você criar para ler Pose InformAton.
Exemplo para teste:
# default tuples
python ./data_scripts/generate_test_tuples.py
--data_config configs/data/scannet_default_test.yaml
--num_workers 16
# dense tuples
python ./data_scripts/generate_test_tuples.py
--data_config configs/data/scannet_dense_test.yaml
--num_workers 16Exemplos para trem:
# train
python ./data_scripts/generate_train_tuples.py
--data_config configs/data/scannet_default_train.yaml
--num_workers 16
# val
python ./data_scripts/generate_val_tuples.py
--data_config configs/data/scannet_default_val.yaml
--num_workers 16 Esses scripts primeiro verificarão cada quadro no conjunto de dados para garantir que ele tenha um quadro RGB existente, um quadro de profundidade existente (se apropriado para o conjunto de dados) e também um arquivo de pose existente e válido. Ele salvará esses valid_frames em um arquivo de texto na pasta de cada varredura, mas se o diretório for apenas leitura, ele ignorará a economia de um arquivo valid_frames e gerará tuplas de qualquer maneira.
Você pode usar test.py para inferir e avaliar mapas de profundidade e malhas de fusão.
Todos os resultados serão armazenados em uma pasta de resultados básicos (Resultados_path) em:
opts.output_base_path/opts.name/opts.dataset/opts.frame_tuple_type/
Onde OPTS é a classe options . Por exemplo, quando opts.output_base_path é ./results , opts.name é HERO_MODEL , opts.dataset é scannet e opts.frame_tuple_type é default , o diretório de saída será
./results/HERO_MODEL/scannet/default/
Certifique -se de definir --opts.output_base_path para um diretório adequado para você armazenar resultados.
--frame_tuple_type é o tipo de tupla de imagem usada para MVS. Uma seleção deve ser fornecida no arquivo data_config que você usou.
Por padrão, test.py tentará calcular as pontuações de profundidade para cada quadro e fornecerá a média do quadro e as métricas médias da cena. O script salvará essas pontuações (por cena e totais) em results_path/scores .
Fizemos o possível para garantir que um bug em lote de tocha através do codificador correspondente seja corrigido para testes precisos (<10^-4), desativando o lote de imagem por meio desse codificador. Run --batch_size 4 No máximo, em caso de dúvida, e se você deseja ficar o mais estável possível e evitar o Pytorch Gremlins, use --batch_size 1 para comparação.
Se você deseja usar isso para velocidade, defina --fast_cost_volume como true. Isso permitirá o lote através do codificador correspondente e permitirá um volume de recursos otimizado do Einops.
# Example command to just compute scores
CUDA_VISIBLE_DEVICES=0 python test.py --name HERO_MODEL
--output_base_path OUTPUT_PATH
--config_file configs/models/hero_model.yaml
--load_weights_from_checkpoint weights/hero_model.ckpt
--data_config configs/data/scannet_default_test.yaml
--num_workers 8
--batch_size 4 ;
# If you'd like to get a super fast version use:
CUDA_VISIBLE_DEVICES=0 python test.py --name HERO_MODEL
--output_base_path OUTPUT_PATH
--config_file configs/models/hero_model.yaml
--load_weights_from_checkpoint weights/hero_model.ckpt
--data_config configs/data/scannet_default_test.yaml
--num_workers 8
--fast_cost_volume
--batch_size 2 ;Este script também pode ser usado para executar algumas tarefas auxiliares diferentes, incluindo:
TSDF Fusion
Para executar o TSDF Fusion, forneça o sinalizador --run_fusion . Você tem duas opções para os fusores
--depth_fuser ours (padrão) usará nosso fusor, cujas malhas são usadas na maioria das visualizações e para as pontuações. Este fusor não suporta cor. Fornecemos uma filial personalizada da Scikit-Image com nossa implementação personalizada de measure.matching_cubes . Usamos malhas de parede única para avaliação. Se isso não for importante para você, você pode definir o export_single_mesh como False para chamada para export_mesh em test.py--depth_fuser open3d usará o fusor de profundidade do Open3D. Este fusor suporta a cor e você pode ativar isso usando o sinalizador --fuse_color . Por padrão, os mapas de profundidade serão presos a 3m para fusão e uma resolução TSDF de 0,04m 3 será usada, mas você pode alterar isso alterando os dois --max_fusion_depth e --fusion_resolution
Você pode opção, solicitar que as profundidades previstas usadas para a fusão sejam mascaradas quando não existam informações do VAIID MVS usando --mask_pred_depths . Isso não está ativado por padrão.
Você também pode fundir as melhores profundidades de adivinhação do volume de custos antes do codificador de volume de custo que introduz uma imagem forte antes. Você pode fazer isso usando --fusion_use_raw_lowest_cost .
As malhas serão armazenadas em results_path/meshes/ .
# Example command to fuse depths to get meshes
CUDA_VISIBLE_DEVICES=0 python test.py --name HERO_MODEL
--output_base_path OUTPUT_PATH
--config_file configs/models/hero_model.yaml
--load_weights_from_checkpoint weights/hero_model.ckpt
--data_config configs/data/scannet_default_test.yaml
--num_workers 8
--run_fusion
--batch_size 8 ;Profundidades de cache
Opcionalmente, você pode armazenar profundidades, fornecendo o sinalizador --cache_depths . Eles serão armazenados em results_path/depths .
# Example command to compute scores and cache depths
CUDA_VISIBLE_DEVICES=0 python test.py --name HERO_MODEL
--output_base_path OUTPUT_PATH
--config_file configs/models/hero_model.yaml
--load_weights_from_checkpoint weights/hero_model.ckpt
--data_config configs/data/scannet_default_test.yaml
--num_workers 8
--cache_depths
--batch_size 8 ;
# Example command to fuse depths to get color meshes
CUDA_VISIBLE_DEVICES=0 python test.py --name HERO_MODEL
--output_base_path OUTPUT_PATH
--config_file configs/models/hero_model.yaml
--load_weights_from_checkpoint weights/hero_model.ckpt
--data_config configs/data/scannet_default_test.yaml
--num_workers 8
--run_fusion
--depth_fuser open3d
--fuse_color
--batch_size 4 ;Rápido viz
Existem outros scripts para visualizações mais profundas de profundidades de saída e fusão, mas para a exportação rápida da visualização do mapa de profundidade que você pode usar --dump_depth_visualization . As visualizações serão armazenadas em results_path/viz/quick_viz/ .
# Example command to output quick depth visualizations
CUDA_VISIBLE_DEVICES=0 python test.py --name HERO_MODEL
--output_base_path OUTPUT_PATH
--config_file configs/models/hero_model.yaml
--load_weights_from_checkpoint weights/hero_model.ckpt
--data_config configs/data/scannet_default_test.yaml
--num_workers 8
--dump_depth_visualization
--batch_size 4 ; Também permitimos a fusão da nuvem de pontos de mapas de profundidade usando o fusor do repositório da 3DVNET.
# Example command to fuse depths into point clouds.
CUDA_VISIBLE_DEVICES=0 python pc_fusion.py --name HERO_MODEL
--output_base_path OUTPUT_PATH
--config_file configs/models/hero_model.yaml
--load_weights_from_checkpoint weights/hero_model.ckpt
--data_config configs/data/scannet_dense_test.yaml
--num_workers 8
--batch_size 4 ; Alterar configs/data/scannet_dense_test.yaml para configs/data/scannet_default_test.yaml para usar os quadros -chave apenas se você não quiser esperar muito.
Utilizamos a avaliação de malha do Transformerfusion para nossa tabela de resultados principais, mas defina a semente como um valor fixo para consistência ao amostrar aleatoriamente malhas. Também relatamos métricas de malha usando a avaliação do Neuralrecon no material suplementar.
Para avaliação da nuvem de pontos, usamos o código do Transformerfusion, mas carregamos em uma nuvem de pontos no lugar da amostragem da superfície de uma malha.
Por padrão, modelos e arquivos de eventos de tensorboard são salvos para ~/tmp/tensorboard/<model_name> . Isso pode ser alterado com o sinalizador --log_dir .
Treinamos com um batch_size de 16 com precisão de 16 bits em dois A100s na divisão do scannetv2 padrão.
Exemplo de comando para treinar com duas GPUs:
CUDA_VISIBLE_DEVICES=0,1 python train.py --name HERO_MODEL
--log_dir logs
--config_file configs/models/hero_model.yaml
--data_config configs/data/scannet_default_train.yaml
--gpus 2
--batch_size 16 ; O código suporta qualquer número de GPUs para treinamento. Você pode especificar quais GPUs usar com o ambiente CUDA_VISIBLE_DEVICES .
Todas as nossas execuções de treinamento foram realizadas em dois NVIDIA A100s.
Diferente conjunto de dados
Você pode treinar em um conjunto de dados MVS personalizado escrevendo uma nova classe Dataloader que herda do GenericMVSDataset em datasets/generic_mvs_dataset.py . Consulte a classe ScannetDataset em datasets/scannet_dataset.py ou qualquer outra classe nos datasets por exemplo.
Para Finetune, carregue um ponto de verificação simples (não retomar!) E treine a partir daí:
CUDA_VISIBLE_DEVICES=0 python train.py --config configs/models/hero_model.yaml
--data_config configs/data/scannet_default_train.yaml
--load_weights_from_checkpoint weights/hero_model.ckptAltere as configurações de dados para qualquer conjunto de dados para o qual você deseja o Finetune.
Consulte options.py para o intervalo de outras opções de treinamento, como taxas de aprendizado e configurações de ablação e opções de teste.
Além da visualização rápida de profundidade no script test.py , existem dois scripts para visualizar a saída de profundidade.
O primeiro é visualization_scripts/visualize_scene_depth_output.py . Isso produzirá um vídeo com imagens coloridas dos quadros de referência e fonte, previsão de profundidade, estimativa de volume de custo, profundidade de GT e normais estimados a partir da profundidade. O script pressupõe que você tenha uma saída de profundidade em cache usando test.py e aceita o mesmo formato de modelo de comando que test.py :
# Example command to get visualizations for dense frames
CUDA_VISIBLE_DEVICES=0 python ./visualization_scripts/visualize_scene_depth_output.py --name HERO_MODEL
--output_base_path OUTPUT_PATH
--data_config configs/data/scannet_dense_test.yaml
--num_workers 8 ; onde OUTPUT_PATH é o diretório de resultados da base para o SimpleReCon (o que você usou para o teste para começar). Opcionalmente, você pode executar .visualization_scripts/generate_gt_min_max_cache.py antes deste script para obter uma média de cena para os valores de profundidade MIN e MAX usados para colorirping; Se eles não estiverem disponíveis, o script usará 0M e 5M para colomapping min e max.
O segundo permite uma visualização ao vivo da malha. Esse script usará mapas de profundidade em cache, se disponível, caso contrário, ele usará o modelo para prever -os antes da fusão. O script carregará iterativamente em um mapa de profundidade, fundi -lo, salvará um arquivo de malha nesta etapa e renderizar essa malha ao lado de um marcador de câmera para o vídeo de Birdseye e do ponto de vista da câmera para o vídeo FPV.
# Example command to get live visualizations for mesh reconstruction
CUDA_VISIBLE_DEVICES=0 python visualize_live_meshing.py --name HERO_MODEL
--output_base_path OUTPUT_PATH
--config_file configs/models/hero_model.yaml
--load_weights_from_checkpoint weights/hero_model.ckpt
--data_config configs/data/scannet_dense_test.yaml
--num_workers 8 ; Por padrão, o script salvará malhas em um local intermediário e você pode opcionalmente carregar essas malhas para economizar tempo ao visualizar as mesmas malhas novamente passando --use_precomputed_partial_meshes . Todas as malhas intermediárias terão que ser calculadas na execução anterior para que isso funcione.
Tl; dr: world_T_cam == world_from_cam
Este repositório usa a notação "CAM_T_WORLD" para denotar uma transformação do mundo para os pontos da câmera (extrínsecos). A intenção é fazê -lo para que os nomes de quadros de coordenadas correspondam em ambos os lados da variável quando usados na multiplicação da direita para a esquerda :
cam_points = cam_T_world @ world_points
world_T_cam denota a pose da câmera (de came para coordenados mundiais). ref_T_src indica uma transformação de uma fonte para uma exibição de referência.
Finalmente, essa notação permite representar rotações e traduções como: world_R_cam e world_t_cam
Este repositório é voltado para o scannet; portanto, embora sua funcionalidade deva permitir qualquer sistema de coordenadas (sinalizado por meio de sinalizadores de entrada), os pesos do modelo que fornecemos assumem um sistema de coordenadas de scannet. Isso é importante, pois incluímos informações de raios como parte dos metadados. Outros conjuntos de dados usados com esses pesos devem ser transformados no sistema scannet. As classes do conjunto de dados que incluímos executarão as transformações apropriadas.
Existem alguns bugs abordados nesta atualização, você precisará atualizar seus garfos e usar novos pesos da tabela perto do início deste ReadMe. Você também precisará garantir que você tenha os arquivos intrinsics corretos extraídos usando o leitor.
Graças a todos aqueles que apontaram e foram pacientes enquanto trabalhamos em correções.
Todas as pontuações melhoram com essas correções e os pesos associados são enviados aqui. Para pontuações antigas, código e pesos, verifique este compromisso hash: 7de5b451e340f9a11c7fd67bd0c42204d0b009a9
Pontuações completas para modelos com correções de bug:
Profundidade
--config | ABS DIFF ∞ | ABS REL ↓ | SQ Rel ↓ | Rmse ∞ | Log RMSE ∞ | delta <1,05 ↑ | delta <1,10 ↑ |
|---|---|---|---|---|---|---|---|
hero_model.yaml , metadata + resnet | 0,0868 | 0,0428 | 0,0127 | 0,1472 | 0,0681 | 74.26 | 90.88 |
dot_product_model.yaml , produto de ponto + resnet | 0,0910 | 0,0453 | 0,0134 | 0.1509 | 0,0704 | 71.90 | 89,75 |
Fusão de malha
--config | ACC ↓ | Comp ↓ | Chanfro ↓ | RECORTE ↑ | Precisão ↑ | F-score ↑ |
|---|---|---|---|---|---|---|
hero_model.yaml , metadata + resnet | 5.41 | 5.98 | 5.69 | 0,695 | 0,668 | 0,680 |
dot_product_model.yaml , produto de ponto + resnet | 5.66 | 6.18 | 5.92 | 0,682 | 0,655 | 0,667 |
Comparação:
--config | Modelo | ABS DIFF ∞ | SQ Rel ↓ | delta <1,05 ↑ | Chanfro ↓ | F-score ↑ |
|---|---|---|---|---|---|---|
hero_model.yaml | Metadados + Resnet correspondência | 0,0868 | 0,0127 | 74.26 | 5.69 | 0,680 |
Old hero_model.yaml | Metadados + Resnet correspondência | 0,0885 | 0,0125 | 73.16 | 5.81 | 0,671 |
dot_product_model.yaml | DOT PRODUTO + COMPRIMENTO DE RESNET | 0,0910 | 0,0134 | 71.90 | 5.92 | 0,667 |
Antigo dot_product_model.yaml | DOT PRODUTO + COMPRIMENTO DE RESNET | 0,0941 | 0,0139 | 70.48 | 6.29 | 0,642 |
Inicialmente, esse repo cuspiu arquivos de tupla para quadros de chave de estilo DVMVS padrão com 9 quadros extras de 25599 para o conjunto de testes Scannetv2. Houve um pequeno bug ao lidar com o rastreamento perdido que agora está corrigido. Este repositório deve agora imitar exatamente o buffer DVMVS Keyframe, com 25590 quadros -chave para teste. O único efeito que esse bug teve foi a inclusão de 9 quadros extras, todas as outras tuplas eram exatamente as mesmas que as DVMVs. Os quadros ofensivos estão nessas varreduras
scan previous count new count
--------------------------------------
scene0711_00 393 392
scene0727_00 209 208
scene0736_00 1023 1022
scene0737_00 408 407
scene0751_00 165 164
scene0775_00 220 219
scene0791_00 227 226
scene0794_00 141 140
scene0795_00 102 101
Os arquivos de tupla para teste padrão foram atualizados. Como essa é uma diferença pequena (~ 3E-4) nos quadros extras pontuados, as pontuações permanecem inalteradas.
Tl; dr: escala suas poses e corte suas imagens.
Fornecemos um Dataloader para carregar imagens de uma reconstrução escassa de Colmap. Para que isso funcione com o SimplereCon, você precisará cortar suas imagens para combinar com o FOV do scannet (aproximadamente semelhante ao FOV de um iPhone no modo de vídeo) e escalar a localização da sua pose usando medições conhecidas do mundo real. Se essas etapas não forem tomadas, o volume de custo não será construído corretamente e a rede não estimará a profundidade corretamente.
Agradecemos a Aljažič de Transformerfusion, Jiaming Sun of Neural Recon e Arda Düzçeker da DeepVideOMVs por fornecer rapidamente informações úteis para ajudar nas linhas de base e a disponibilizar suas bases de código, especialmente em curto prazo.
Os scripts de geração de tupla fazem uso pesado de uma versão modificada do buffer de quadro de Keyframe do DeepVideOMVS (obrigado novamente Arda e Co!).
O módulo Pytorch Point Cloud Fusion em torch_point_cloud_fusion Código é emprestado do repo do 3DVNET. Obrigado Alexander Rich!
Também gostaríamos de agradecer à equipe de infraestrutura da Niantic por ações rápidas quando precisávamos delas. Obrigado pessoal!
Mohamed é financiado por uma bolsa de doutorado da Microsoft Research (MRL 2018-085).
Se você achar nosso trabalho útil em sua pesquisa, considere citar nosso artigo:
@inproceedings{sayed2022simplerecon,
title={SimpleRecon: 3D Reconstruction Without 3D Convolutions},
author={Sayed, Mohamed and Gibson, John and Watson, Jamie and Prisacariu, Victor and Firman, Michael and Godard, Cl{'e}ment},
booktitle={Proceedings of the European Conference on Computer Vision (ECCV)},
year={2022},
}
Copyright © Niantic, Inc. 2022. Patente pendente. Todos os direitos reservados. Consulte o arquivo de licença para termos.


