MARLlib
v1.0.3
| ❗新聞 |
|---|
| 2023年3月⚓我們很高興地宣布,剛剛發布了重大更新。有關詳細版本信息,請參閱版本信息。 |
| 2023年5月令人興奮的消息! Marllib現在還支持五項任務:伴侶,Gobigger,煮熟的AI,MAPDN和Aircombat。試試看! |
| 2023年6月Openai:隱藏和尋求,SISL環境已納入Marllib。 |
| 2023年8月? Marllib已被接受在JMLR中出版。 |
| 2023年9月,最新的Pettingzoo與體育館在Marllib中兼容。 |
| 2023年11月,我們目前正在創建一本動手的Marl書籍,並旨在在2023年底之前發布草案。 |
多代理增強學習庫(Marllib)是一個使用Ray及其工具包RLLIB之一的MARL庫。它提供了一個綜合平台,用於開發,培訓和測試各種任務和環境的MARL算法。
這是如何使用Marllib的一個示例:
from marllib import marl
# prepare env
env = marl . make_env ( environment_name = "mpe" , map_name = "simple_spread" , force_coop = True )
# initialize algorithm with appointed hyper-parameters
mappo = marl . algos . mappo ( hyperparam_source = 'mpe' )
# build agent model based on env + algorithms + user preference
model = marl . build_model ( env , mappo , { "core_arch" : "mlp" , "encode_layer" : "128-256" })
# start training
mappo . fit ( env , model , stop = { 'timesteps_total' : 1000000 }, share_policy = 'group' )在這裡,我們提供了一個比較馬里布和現有工作的表。
| 圖書館 | 支持的環境 | 演算法 | 參數共享 | 模型 |
|---|---|---|---|---|
| pymarl | 1合作社 | 5 | 分享 | gru |
| pymarl2 | 2合作社 | 11 | 分享 | MLP + GRU |
| Mappo基準 | 4合作社 | 1 | 共享 +獨立 | MLP + GRU |
| 馬里布 | 4個自我播放 | 10 | 共享 +組 +獨立 | MLP + LSTM |
| Epymarl | 4合作社 | 9 | 共享 +獨立 | gru |
| 哈爾 | 8合作社 | 9 | 共享 +獨立 | MLP + CNN + GRU |
| 瑪莉布 | 17沒有任務模式限制 | 18 | 共享 +組 +獨立 +可自定義 | MLP + CNN + GRU + LSTM |
| 圖書館 | Github星星 | 文件 | 問題已經開放 | 活動 | 最後更新 |
|---|---|---|---|---|---|
| pymarl | |||||
| pymarl2 | |||||
| Mappo基準 | |||||
| 馬里布 | |||||
| Epymarl | |||||
| harl * | |||||
| 瑪莉布 |
* Harl是最近發布的最新MARL圖書館:Fire:。如果您的目標是具有最先進的性能的尖端MARL算法,那麼Harl絕對值得一看!
? Marllib提供了幾個關鍵功能,使其脫穎而出:
使用Marllib,您可以利用各種好處,例如:
注意:請注意,目前,Marllib僅與Linux操作系統兼容。
首先,安裝Marllib依賴性以保證基本用法。遵循本指南,最後為RLLIB安裝補丁。
$ conda create -n marllib python=3.8 # or 3.9
$ conda activate marllib
$ git clone https://github.com/Replicable-MARL/MARLlib.git && cd MARLlib
$ pip install -r requirements.txt請遵循本指南。
注意:我們建議在0.20.0左右的健身版本。
pip install " gym==0.20.0 " 通過運行以下命令使用補丁程序修復RLLIB的錯誤:
$ cd /Path/To/MARLlib/marllib/patch
$ python add_patch.py -y$ pip install --upgrade pip
$ pip install marllib我們提供了一個用於在MARLlib/docker/Dockerfile和MARLlib/.devcontainer文件夾中構建Marllib Docker圖像的Dockerfile。如果您使用devcontainer,請注意的一件事是,您可能需要根據您的硬件來自runArgs devcontainer.json的某些參數,例如--shm-size參數。
配置的四個部分負責整個培訓過程。
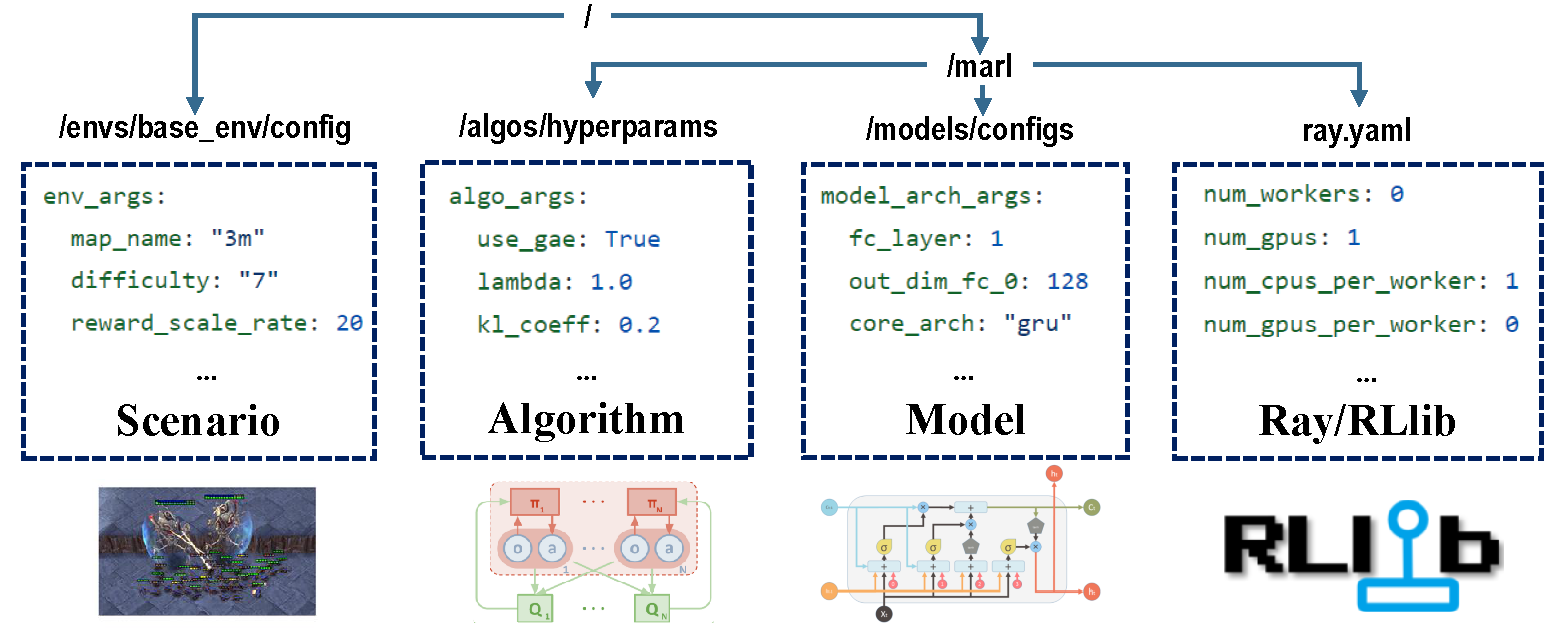
在培訓之前,請確保正確設置所有參數,尤其是您不想更改的參數。
注意:您還可以通過Marllib API修改所有預設參數。
確保為您正在運行的環境安裝了所有依賴項。否則,請參閱Marllib文檔。
| 任務模式 | API示例 |
|---|---|
| 合作 | marl.make_env(environment_name="mpe", map_name="simple_spread", force_coop=True) |
| 協作 | marl.make_env(environment_name="mpe", map_name="simple_spread") |
| 競爭的 | marl.make_env(environment_name="mpe", map_name="simple_adversary") |
| 混合 | marl.make_env(environment_name="mpe", map_name="simple_crypto") |
MARL研究中的大多數流行環境得到了Marllib的支持:
| env名稱 | 學習模式 | 可觀察性 | 動作空間 | 觀察 |
|---|---|---|---|---|
| LBF | 合作 +協作 | 兩個都 | 離散的 | 1d |
| Rware | 合作 | 部分的 | 離散的 | 1d |
| MPE | 合作 +協作 +混合 | 兩個都 | 兩個都 | 1d |
| SISL | 合作 +協作 | 滿的 | 兩個都 | 1d |
| Smac | 合作 | 部分的 | 離散的 | 1d |
| 元素 | 協作 | 部分的 | 連續的 | 1d |
| 洋紅色 | 協作 +混合 | 部分的 | 離散的 | 2d |
| Pommerman | 協作 +競爭性 +混合 | 兩個都 | 離散的 | 2d |
| Mamujoco | 合作 | 滿的 | 連續的 | 1d |
| grf | 協作 +混合 | 滿的 | 離散的 | 2d |
| 哈納比 | 合作 | 部分的 | 離散的 | 1d |
| 伴侶 | 合作 +混合 | 部分的 | 兩個都 | 1d |
| Gobigger | 合作 +混合 | 兩個都 | 連續的 | 1d |
| 過度煮熟 | 合作 | 滿的 | 離散的 | 1d |
| PDN | 合作 | 部分的 | 連續的 | 1d |
| Aircombat | 合作 +混合 | 部分的 | 多差異 | 1d |
| hideandseek | 競爭性 +混合 | 部分的 | 多差異 | 1d |
每個環境都有一個註冊文件,作為此任務的指令,包括ENV設置,安裝和重要說明。
| 運行目標 | API示例 |
|---|---|
| 火車和芬太尼 | marl.algos.mappo(hyperparam_source=$ENV) |
| 開發和調試 | marl.algos.mappo(hyperparam_source="test") |
| 第三方 | marl.algos.mappo(hyperparam_source="common") |
這是描述每種算法的特徵的圖表:
| 演算法 | 支持任務模式 | 離散動作 | 連續行動 | 策略類型 |
|---|---|---|---|---|
| IQL * | 全部四個 | ✔️ | 非政策 | |
| pg | 全部四個 | ✔️ | ✔️ | 上政策 |
| A2C | 全部四個 | ✔️ | ✔️ | 上政策 |
| DDPG | 全部四個 | ✔️ | 非政策 | |
| trpo | 全部四個 | ✔️ | ✔️ | 上政策 |
| PPO | 全部四個 | ✔️ | ✔️ | 上政策 |
| 昏迷 | 全部四個 | ✔️ | 上政策 | |
| maddpg | 全部四個 | ✔️ | 非政策 | |
| MAA2C * | 全部四個 | ✔️ | ✔️ | 上政策 |
| Matrpo * | 全部四個 | ✔️ | ✔️ | 上政策 |
| Mappo | 全部四個 | ✔️ | ✔️ | 上政策 |
| Hatrpo | 合作 | ✔️ | ✔️ | 上政策 |
| 霍普 | 合作 | ✔️ | ✔️ | 上政策 |
| VDN | 合作 | ✔️ | 非政策 | |
| QMIX | 合作 | ✔️ | 非政策 | |
| FACMAC | 合作 | ✔️ | 非政策 | |
| vdac | 合作 | ✔️ | ✔️ | 上政策 |
| vdppo * | 合作 | ✔️ | ✔️ | 上政策 |
*所有四個:合作協作競爭的混合
IQL是Q學習的多代理版本。 MAA2C和MATRPO是A2C和TRPO的集中版本。 VDPPO是PPO的值分解版。
代理模型由兩個部分組成: encoder和core arch 。 encoder將根據觀察空間由Marllib構建。根據您喜歡構建完整的模型,選擇mlp , gru或lstm 。
| 模型拱 | API示例 |
|---|---|
| MLP | marl.build_model(env, algo, {"core_arch": "mlp") |
| gru | marl.build_model(env, algo, {"core_arch": "gru"}) |
| LSTM | marl.build_model(env, algo, {"core_arch": "lstm"}) |
| 編碼器拱門 | marl.build_model(env, algo, {"core_arch": "gru", "encode_layer": "128-256"}) |
| 環境 | API示例 |
|---|---|
| 火車 | algo.fit(env, model) |
| 偵錯 | algo.fit(env, model, local_mode=True) |
| 停止條件 | algo.fit(env, model, stop={'episode_reward_mean': 2000, 'timesteps_total': 10000000}) |
| 政策共享 | algo.fit(env, model, share_policy='all') # or 'group' / 'individual' |
| 保存模型 | algo.fit(env, model, checkpoint_freq=100, checkpoint_end=True) |
| GPU加速 | algo.fit(env, model, local_mode=False, num_gpus=1) |
| CPU加速 | algo.fit(env, model, local_mode=False, num_workers=5) |
from marllib import marl
# prepare env
env = marl . make_env ( environment_name = "smac" , map_name = "5m_vs_6m" )
# initialize algorithm with appointed hyper-parameters
mappo = marl . algos . mappo ( hyperparam_source = "smac" )
# build agent model based on env + algorithms + user preference
model = marl . build_model ( env , mappo , { "core_arch" : "gru" , "encode_layer" : "128-256" })
# start training
mappo . fit (
env , model ,
stop = { "timesteps_total" : 1000000 },
checkpoint_freq = 100 ,
share_policy = "group"
)
# rendering
mappo . render (
env , model ,
local_mode = True ,
restore_path = { 'params_path' : "checkpoint/params.json" ,
'model_path' : "checkpoint/checkpoint-10" }
)在當前的工作目錄下,您可以找到所有培訓數據(日誌記錄和張量文件)以及保存的模型。為了可視化學習曲線,您可以使用張板。請按照以下步驟操作:
pip install tensorboardtensorboard --logdir .另外,您可以參考本教程以獲取更詳細的說明。
對於所有現有結果的列表,您可以訪問此鏈接。請注意,這些結果是從較舊版本的Marllib獲得的,與當前結果相比,這可能會導致不一致。
Marllib提供了一些實用的例子供您參考。
ray.tune進行政策/模型性能。 在Google Colagoratory上嘗試MPE + MAPPO示例!這裡提供更多教程文檔。
提供了多代理增強學習(MARL)的研究和評論論文。這些論文是根據其發布日期和對相應環境的評估進行組織的。
算法:環境:
| 渠道 | 關聯 |
|---|---|
| 問題 | Github問題 |
未來版本的路線圖可在Roadmap.md中找到。
我們是一支有關多機構增強學習的小團隊,我們將獲得我們能獲得的所有幫助!如果您想參與其中,以下是有關貢獻指南以及如何在本地測試代碼的信息。
您可以通過多種方式,例如報告錯誤,編寫或翻譯文檔,審查或重構代碼,請求或實施新功能等。
如果您在研究中使用Marllib,請引用Marllib紙。
@article{hu2022marllib,
author = {Siyi Hu and Yifan Zhong and Minquan Gao and Weixun Wang and Hao Dong and Xiaodan Liang and Zhihui Li and Xiaojun Chang and Yaodong Yang},
title = {MARLlib: A Scalable and Efficient Multi-agent Reinforcement Learning Library},
journal = {Journal of Machine Learning Research},
year = {2023},
}基於或與Marllib <link>緊密合作的作品
@InProceedings{hu2022policy,
title={Policy Diagnosis via Measuring Role Diversity in Cooperative Multi-agent {RL}},
author={Hu, Siyi and Xie, Chuanlong and Liang, Xiaodan and Chang, Xiaojun},
booktitle={Proceedings of the 39th International Conference on Machine Learning},
year={2022},
}
@misc{zhong2023heterogeneousagent,
title={Heterogeneous-Agent Reinforcement Learning},
author={Yifan Zhong and Jakub Grudzien Kuba and Siyi Hu and Jiaming Ji and Yaodong Yang},
archivePrefix={arXiv},
year={2023},
}

