MARLlib
v1.0.3
| ❗ Notícias |
|---|
| Março de 2023 ⚓ Estamos empolgados em anunciar que uma grande atualização acaba de ser lançada. Para obter informações detalhadas da versão, consulte as informações da versão. |
| Maio de 2023 Notícias emocionantes! O Marllib agora suporta mais cinco tarefas: Mate, Gobigger, Cooked-AI, MapDN e Aircombat. Experimente! |
| Junho de 2023 OpenAI: os ambientes de esconderijo e busca e SISL são incorporados ao Marllib. |
| Agosto de 2023 ? Marllib foi aceito para publicação no JMLR. |
| Setting 2023 O mais recente Pettingzoo com ginásio é compatível com Marllib. |
| Nov 2023 Atualmente, estamos criando um livro de Marl e pretendemos lançar o rascunho até o final de 2023. |
A Biblioteca de Aprendizagem de Reforço Multi-Agente (MARLLIB) é uma biblioteca MARL que utiliza Ray e um de seus kits de ferramentas Rllib . Oferece uma plataforma abrangente para o desenvolvimento, treinamento e teste de algoritmos MARL em várias tarefas e ambientes.
Aqui está um exemplo de como o Marllib pode ser usado:
from marllib import marl
# prepare env
env = marl . make_env ( environment_name = "mpe" , map_name = "simple_spread" , force_coop = True )
# initialize algorithm with appointed hyper-parameters
mappo = marl . algos . mappo ( hyperparam_source = 'mpe' )
# build agent model based on env + algorithms + user preference
model = marl . build_model ( env , mappo , { "core_arch" : "mlp" , "encode_layer" : "128-256" })
# start training
mappo . fit ( env , model , stop = { 'timesteps_total' : 1000000 }, share_policy = 'group' )Aqui fornecemos uma tabela para a comparação de Marllib e o trabalho existente.
| Biblioteca | ENV suportado | Algoritmo | Compartilhamento de parâmetros | Modelo |
|---|---|---|---|---|
| PyMarl | 1 Cooperativa | 5 | compartilhar | Gru |
| PyMarl2 | 2 Cooperativa | 11 | compartilhar | MLP + GRU |
| Benchmark Mappo | 4 Cooperativa | 1 | compartilhe + separado | MLP + GRU |
| Malib | 4 Play de auto-auto | 10 | compartilhar + grupo + separado | MLP + LSTM |
| Epymarl | 4 Cooperativa | 9 | compartilhe + separado | Gru |
| Harl | 8 Cooperativa | 9 | compartilhe + separado | MLP + CNN + GRU |
| Marllib | 17 Nenhuma restrição de modo de tarefa | 18 | compartilhar + grupo + separado + personalizável | MLP + CNN + GRU + LSTM |
| Biblioteca | Estrelas do Github | Documentação | Questões abertas | Atividade | Última atualização |
|---|---|---|---|---|---|
| PyMarl | |||||
| PyMarl2 | |||||
| Benchmark Mappo | |||||
| Malib | |||||
| Epymarl | |||||
| Harl * | |||||
| Marllib |
* Harl é a mais recente biblioteca Marl que foi lançada recentemente: Fire:. Se os algoritmos Marl de ponta com desempenho de última geração forem o seu alvo, a Harl definitivamente vale a pena dar uma olhada!
? Marllib oferece vários recursos importantes que o destacam:
Usando o Marllib, você pode aproveitar vários benefícios, como:
Nota : Observe que, neste momento, o Marllib é compatível apenas com os sistemas operacionais Linux.
Primeiro, instale as dependências do MARLLIB para garantir o uso básico. Após este guia, finalmente instale patches para rllib.
$ conda create -n marllib python=3.8 # or 3.9
$ conda activate marllib
$ git clone https://github.com/Replicable-MARL/MARLlib.git && cd MARLlib
$ pip install -r requirements.txtSiga este guia.
Nota : Recomendamos a versão da academia em torno de 0,20.0.
pip install " gym==0.20.0 " Corrija os bugs do rllib usando patches executando o seguinte comando:
$ cd /Path/To/MARLlib/marllib/patch
$ python add_patch.py -y$ pip install --upgrade pip
$ pip install marllib Fornecemos um Dockerfile para a construção da imagem do Marllib Docker em MARLlib/docker/Dockerfile e uma configuração DevContainer na pasta MARLlib/.devcontainer . Se você usar o DevContainer, uma coisa a observar é que pode ser necessário personalizar certos argumentos em runArgs de devcontainer.json de acordo com seu hardware, por exemplo, o argumento --shm-size .
Existem quatro partes de configurações que se encarregam de todo o processo de treinamento.
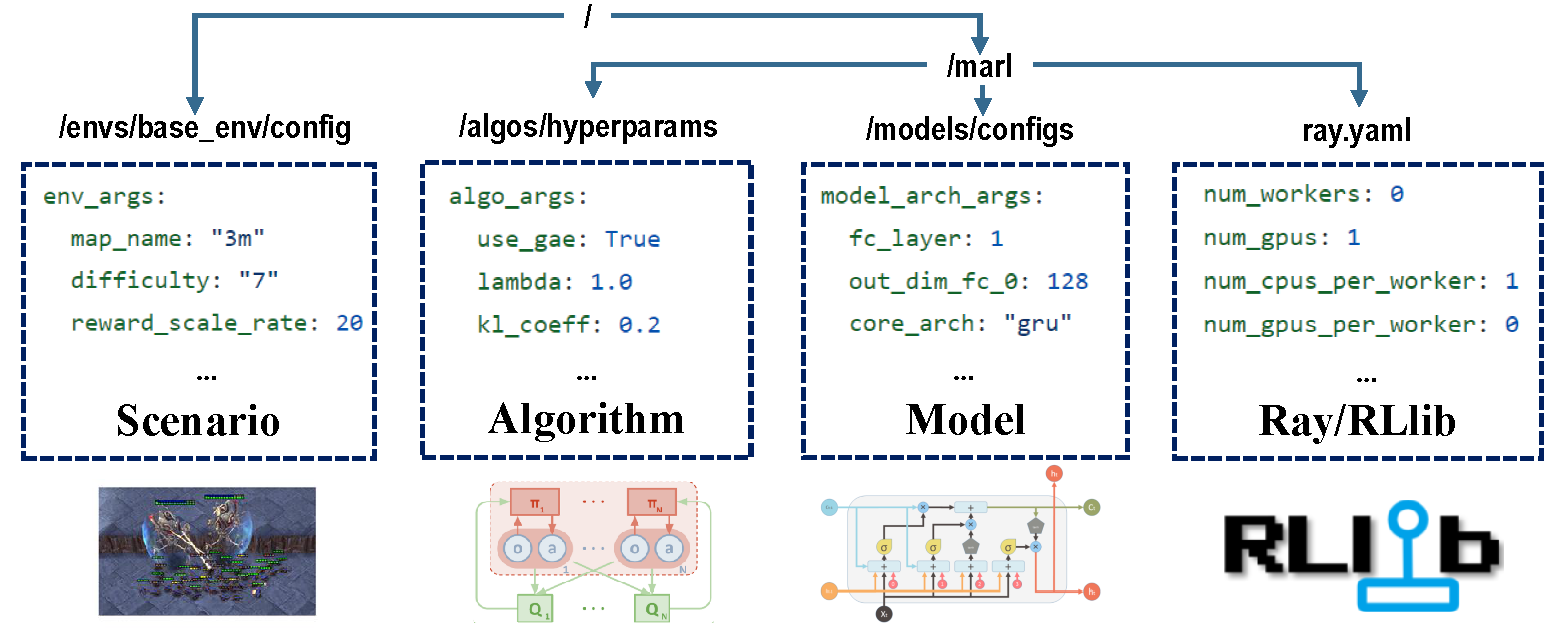
Antes do treinamento, verifique se todos os parâmetros estão definidos corretamente, especialmente aqueles que você não deseja alterar.
Nota : Você também pode modificar todos os parâmetros predefinidos via API Marllib.*
Verifique se todas as dependências estão instaladas para o ambiente com o qual você está executando. Caso contrário, consulte a documentação de Marllib.
| modo de tarefa | Exemplo de API |
|---|---|
| Cooperativa | marl.make_env(environment_name="mpe", map_name="simple_spread", force_coop=True) |
| Colaborativo | marl.make_env(environment_name="mpe", map_name="simple_spread") |
| competitivo | marl.make_env(environment_name="mpe", map_name="simple_adversary") |
| misturado | marl.make_env(environment_name="mpe", map_name="simple_crypto") |
A maioria dos ambientes populares da Marl Research é apoiada por Marllib:
| Env Nome | Modo de aprendizado | Observabilidade | Espaço de ação | Observações |
|---|---|---|---|---|
| Lbf | Cooperativo + Colaborativo | Ambos | Discreto | 1d |
| Rware | Cooperativa | Parcial | Discreto | 1d |
| MPE | Cooperativo + Colaborativo + Misto | Ambos | Ambos | 1d |
| Sisl | Cooperativo + Colaborativo | Completo | Ambos | 1d |
| SMAC | Cooperativa | Parcial | Discreto | 1d |
| Metadrive | Colaborativo | Parcial | Contínuo | 1d |
| Magent | colaborativo + misto | Parcial | Discreto | 2d |
| Pommerman | colaborativo + competitivo + misto | Ambos | Discreto | 2d |
| Mamujoco | Cooperativa | Completo | Contínuo | 1d |
| Grf | colaborativo + misto | Completo | Discreto | 2d |
| Hanabi | Cooperativa | Parcial | Discreto | 1d |
| AMIGO | Cooperativa + Misto | Parcial | Ambos | 1d |
| Gobigger | Cooperativa + Misto | Ambos | Contínuo | 1d |
| Overos-cozido-AI | Cooperativa | Completo | Discreto | 1d |
| Pdn | Cooperativa | Parcial | Contínuo | 1d |
| Aircombat | Cooperativa + Misto | Parcial | Multidiscreto | 1d |
| Hideandseek | competitivo + misto | Parcial | Multidiscreto | 1d |
Cada ambiente possui um arquivo ReadMe, em pé como a instrução para esta tarefa, incluindo configurações Env, instalação e notas importantes.
| alvo em execução | Exemplo de API |
|---|---|
| Trem e Finetune | marl.algos.mappo(hyperparam_source=$ENV) |
| desenvolver e depurar | marl.algos.mappo(hyperparam_source="test") |
| 3ª parte Env | marl.algos.mappo(hyperparam_source="common") |
Aqui está um gráfico que descreve as características de cada algoritmo:
| algoritmo | Modo de tarefa de suporte | ação discreta | ação contínua | Tipo de política |
|---|---|---|---|---|
| IQL * | todos os quatro | ✔️ | fora da política | |
| Pág | todos os quatro | ✔️ | ✔️ | na política |
| A2C | todos os quatro | ✔️ | ✔️ | na política |
| Ddpg | todos os quatro | ✔️ | fora da política | |
| TRPO | todos os quatro | ✔️ | ✔️ | na política |
| PPO | todos os quatro | ✔️ | ✔️ | na política |
| COMA | todos os quatro | ✔️ | na política | |
| Maddpg | todos os quatro | ✔️ | fora da política | |
| Maa2c * | todos os quatro | ✔️ | ✔️ | na política |
| Matrpo * | todos os quatro | ✔️ | ✔️ | na política |
| Mappo | todos os quatro | ✔️ | ✔️ | na política |
| Hatrpo | Cooperativa | ✔️ | ✔️ | na política |
| Happo | Cooperativa | ✔️ | ✔️ | na política |
| Vdn | Cooperativa | ✔️ | fora da política | |
| Qmix | Cooperativa | ✔️ | fora da política | |
| FACMAC | Cooperativa | ✔️ | fora da política | |
| Vdac | Cooperativa | ✔️ | ✔️ | na política |
| Vdppo * | Cooperativa | ✔️ | ✔️ | na política |
* Todos os quatro : Cooperativo Colaborativo Competitivo Misto
O IQL é a versão multi-agente do Q Learning. MAA2C e MATRPO são a versão centralizada do A2C e TRPO. VDPPO é a versão de decomposição do valor do PPO.
Um modelo de agente consiste em duas partes, encoder e core arch . encoder será construído por Marllib de acordo com o espaço de observação. Escolha mlp , gru ou lstm como você deseja criar o modelo completo.
| Modelo Arch | Exemplo de API |
|---|---|
| MLP | marl.build_model(env, algo, {"core_arch": "mlp") |
| Gru | marl.build_model(env, algo, {"core_arch": "gru"}) |
| LSTM | marl.build_model(env, algo, {"core_arch": "lstm"}) |
| Arco do codificador | marl.build_model(env, algo, {"core_arch": "gru", "encode_layer": "128-256"}) |
| contexto | Exemplo de API |
|---|---|
| trem | algo.fit(env, model) |
| depurar | algo.fit(env, model, local_mode=True) |
| pare a condição | algo.fit(env, model, stop={'episode_reward_mean': 2000, 'timesteps_total': 10000000}) |
| compartilhamento de políticas | algo.fit(env, model, share_policy='all') # or 'group' / 'individual' |
| salvar modelo | algo.fit(env, model, checkpoint_freq=100, checkpoint_end=True) |
| GPU acelera | algo.fit(env, model, local_mode=False, num_gpus=1) |
| CPU acelera | algo.fit(env, model, local_mode=False, num_workers=5) |
from marllib import marl
# prepare env
env = marl . make_env ( environment_name = "smac" , map_name = "5m_vs_6m" )
# initialize algorithm with appointed hyper-parameters
mappo = marl . algos . mappo ( hyperparam_source = "smac" )
# build agent model based on env + algorithms + user preference
model = marl . build_model ( env , mappo , { "core_arch" : "gru" , "encode_layer" : "128-256" })
# start training
mappo . fit (
env , model ,
stop = { "timesteps_total" : 1000000 },
checkpoint_freq = 100 ,
share_policy = "group"
)
# rendering
mappo . render (
env , model ,
local_mode = True ,
restore_path = { 'params_path' : "checkpoint/params.json" ,
'model_path' : "checkpoint/checkpoint-10" }
)No diretório de trabalho atual, você pode encontrar todos os dados de treinamento (arquivos de log e tensorflow), bem como os modelos salvos. Para visualizar a curva de aprendizado, você pode usar o Tensorboard. Siga as etapas abaixo:
pip install tensorboardtensorboard --logdir .Como alternativa, você pode consultar este tutorial para obter instruções mais detalhadas.
Para uma lista de todos os resultados existentes, você pode visitar este link. Observe que esses resultados foram obtidos de uma versão mais antiga do Marllib, que pode levar a inconsistências quando comparado aos resultados atuais.
Marllib fornece alguns exemplos práticos para você se referir.
ray.tune . Experimente os exemplos MPE + MAPPO no Google Colaboratory! Mais documentações tutoriais estão disponíveis aqui.
Uma coleção de trabalhos de pesquisa e revisão de aprendizado de reforço multi-agente (MARL) está disponível. Os artigos foram organizados com base na data da publicação e na avaliação dos ambientes correspondentes.
Algoritmos: Ambientes:
| Canal | Link |
|---|---|
| Problemas | Questões do Github |
O roteiro para o lançamento futuro está disponível em roteiro.md.
Somos uma pequena equipe com aprendizado de reforço multi-agente, e levaremos toda a ajuda que podemos obter! Se você deseja se envolver, aqui estão as informações sobre diretrizes de contribuição e como testar o código localmente.
Você pode contribuir de várias maneiras, por exemplo, relatar bugs, escrever ou traduzir documentação, revisar ou refatorar código, solicitar ou implementar novos recursos, etc.
Se você usar o Marllib em sua pesquisa, cite o artigo Marllib.
@article{hu2022marllib,
author = {Siyi Hu and Yifan Zhong and Minquan Gao and Weixun Wang and Hao Dong and Xiaodan Liang and Zhihui Li and Xiaojun Chang and Yaodong Yang},
title = {MARLlib: A Scalable and Efficient Multi-agent Reinforcement Learning Library},
journal = {Journal of Machine Learning Research},
year = {2023},
}Trabalhos baseados ou colaboram de perto com Marllib <Link>
@InProceedings{hu2022policy,
title={Policy Diagnosis via Measuring Role Diversity in Cooperative Multi-agent {RL}},
author={Hu, Siyi and Xie, Chuanlong and Liang, Xiaodan and Chang, Xiaojun},
booktitle={Proceedings of the 39th International Conference on Machine Learning},
year={2022},
}
@misc{zhong2023heterogeneousagent,
title={Heterogeneous-Agent Reinforcement Learning},
author={Yifan Zhong and Jakub Grudzien Kuba and Siyi Hu and Jiaming Ji and Yaodong Yang},
archivePrefix={arXiv},
year={2023},
}

