MARLlib
v1.0.3
| ❗ Noticias |
|---|
| Marzo de 2023 ⚓ Estamos emocionados de anunciar que se acaba de lanzar una actualización importante. Para obtener información sobre la versión detallada, consulte la información de la versión. |
| ¡Mayo de 2023 ¡Ejecdas noticias! Marllib ahora admite cinco tareas más: Mate, Gobigger, Overcoked-AI, MAPDN y Aircombat. ¡Pruébalos! |
| Junio de 2023 OpenAI: los entornos de Hide and Search y SISL se incorporan a Marllib. |
| Agosto de 2023 ? Marllib ha sido aceptado para su publicación en JMLR. |
| Septiembre 2023 Los últimos Pettingzoo con gimnasio son compatiables dentro de Marllib. |
| Nov 2023, actualmente estamos en el proceso de crear un libro de margas práctico y pretendemos lanzar el borrador a fines de 2023. |
Biblioteca de aprendizaje de refuerzo de múltiples agentes (Marllib) es una biblioteca de margas que utiliza Ray y uno de sus kits de herramientas Rllib . Ofrece una plataforma integral para desarrollar, capacitar y probar algoritmos de marga en varias tareas y entornos.
Aquí hay un ejemplo de cómo se puede usar Marllib:
from marllib import marl
# prepare env
env = marl . make_env ( environment_name = "mpe" , map_name = "simple_spread" , force_coop = True )
# initialize algorithm with appointed hyper-parameters
mappo = marl . algos . mappo ( hyperparam_source = 'mpe' )
# build agent model based on env + algorithms + user preference
model = marl . build_model ( env , mappo , { "core_arch" : "mlp" , "encode_layer" : "128-256" })
# start training
mappo . fit ( env , model , stop = { 'timesteps_total' : 1000000 }, share_policy = 'group' )Aquí proporcionamos una tabla para la comparación de Marllib y el trabajo existente.
| Biblioteca | Envidio compatible | Algoritmo | Intercambio de parámetros | Modelo |
|---|---|---|---|---|
| Pymarl | 1 Cooperativa | 5 | compartir | Gru |
| Pymarl2 | 2 Cooperativas | 11 | compartir | MLP + Gru |
| Punto de referencia de mappo | 4 Cooperativa | 1 | Compartir + separado | MLP + Gru |
| Malib | 4 auto-juego | 10 | Compartir + grupo + separado | MLP + LSTM |
| Epymarl | 4 Cooperativa | 9 | Compartir + separado | Gru |
| Arco | 8 Cooperativa | 9 | Compartir + separado | MLP + CNN + Gru |
| Marllib | 17 sin restricción de modo de tarea | 18 | Share + Group + separado + personalizable | MLP + CNN + GRU + LSTM |
| Biblioteca | Estrellas de Github | Documentación | Problemas abiertos | Actividad | Última actualización |
|---|---|---|---|---|---|
| Pymarl | |||||
| Pymarl2 | |||||
| Punto de referencia de mappo | |||||
| Malib | |||||
| Epymarl | |||||
| Harl * | |||||
| Marllib |
* Harl es la última biblioteca Marl que se ha lanzado recientemente: Fire:. Si los algoritmos MarL de vanguardia con el rendimiento de última generación son su objetivo, ¡vale la pena echarle un vistazo a Harl, definitivamente vale la pena echarle un vistazo!
? Marllib ofrece varias características clave que lo hacen destacar:
Usando Marllib, puede aprovechar varios beneficios, como:
Nota : Tenga en cuenta que en este momento, Marllib solo es compatible con los sistemas operativos de Linux.
Primero, instale Dependencias de Marllib para garantizar el uso básico. Después de esta guía, finalmente instale parches para RLLIB.
$ conda create -n marllib python=3.8 # or 3.9
$ conda activate marllib
$ git clone https://github.com/Replicable-MARL/MARLlib.git && cd MARLlib
$ pip install -r requirements.txtPor favor, siga esta guía.
Nota : Recomendamos la versión del gimnasio alrededor de 0.20.0.
pip install " gym==0.20.0 " Corrige errores de rllib usando parches ejecutando el siguiente comando:
$ cd /Path/To/MARLlib/marllib/patch
$ python add_patch.py -y$ pip install --upgrade pip
$ pip install marllib Proporcionamos un Dockerfile para construir la imagen de Marllib Docker en MARLlib/docker/Dockerfile y una configuración de DevContainer en la carpeta MARLlib/.devcontainer . Si usa el DevContainer, una cosa a tener en cuenta es que es posible que deba personalizar ciertos argumentos en runArgs de devcontainer.json de acuerdo con su hardware, por ejemplo, el argumento --shm-size .
Hay cuatro partes de las configuraciones que se hacen cargo de todo el proceso de capacitación.
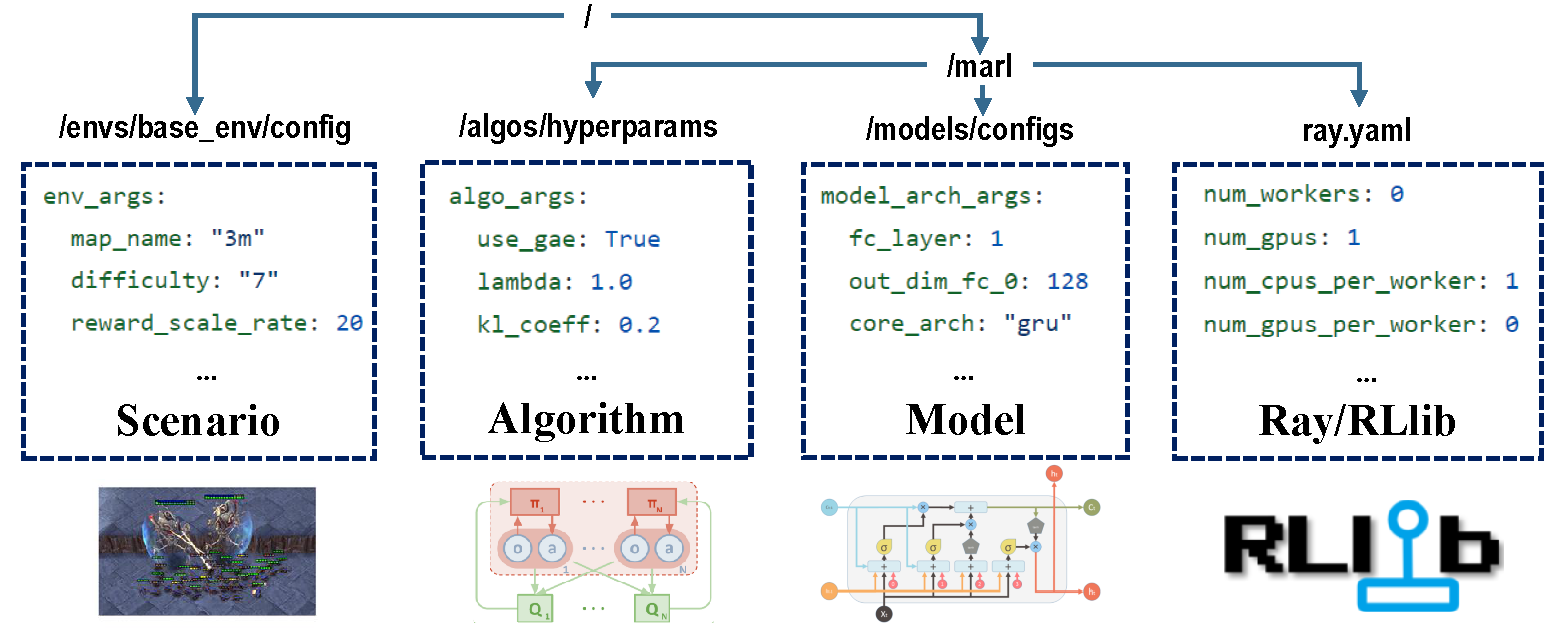
Antes de la capacitación, asegúrese de que todos los parámetros estén configurados correctamente, especialmente aquellos que no desea cambiar.
Nota : También puede modificar todos los parámetros preestablecidos a través de la API Marllib.*
Asegúrese de que todas las dependencias estén instaladas para el entorno con el que está ejecutando. De lo contrario, consulte la documentación de Marllib.
| modo de tarea | Ejemplo de API |
|---|---|
| cooperativa | marl.make_env(environment_name="mpe", map_name="simple_spread", force_coop=True) |
| colaborativo | marl.make_env(environment_name="mpe", map_name="simple_spread") |
| competitivo | marl.make_env(environment_name="mpe", map_name="simple_adversary") |
| mezclado | marl.make_env(environment_name="mpe", map_name="simple_crypto") |
La mayoría de los entornos populares en la investigación de Marl son apoyados por Marllib:
| Envidia | Modo de aprendizaje | Observabilidad | Espacio de acción | Observaciones |
|---|---|---|---|---|
| LBF | cooperativa + colaborativa | Ambos | Discreto | 1D |
| Rware | cooperativa | Parcial | Discreto | 1D |
| MPE | Cooperativa + colaborativa + mixta | Ambos | Ambos | 1D |
| Sisl | cooperativa + colaborativa | Lleno | Ambos | 1D |
| Smac | cooperativa | Parcial | Discreto | 1D |
| Metadrive | colaborativo | Parcial | Continuo | 1D |
| Espléndido | colaborativo + mixto | Parcial | Discreto | 2D |
| Pommerman | colaborativo + competitivo + mixto | Ambos | Discreto | 2D |
| Mamujoco | cooperativa | Lleno | Continuo | 1D |
| GRF | colaborativo + mixto | Lleno | Discreto | 2D |
| Hanabí | cooperativa | Parcial | Discreto | 1D |
| COMPAÑERO | Cooperativa + mixto | Parcial | Ambos | 1D |
| Chorro | Cooperativa + mixto | Ambos | Continuo | 1D |
| Demasiado cocido | cooperativa | Lleno | Discreto | 1D |
| PDN | cooperativa | Parcial | Continuo | 1D |
| Aircombat | Cooperativa + mixto | Parcial | Multidiscreto | 1D |
| Al escondite | competitivo + mixto | Parcial | Multidiscreto | 1D |
Cada entorno tiene un archivo ReadMe, de pie como instrucción para esta tarea, incluida la configuración de ENV, la instalación y las notas importantes.
| Target en ejecución | Ejemplo de API |
|---|---|
| Train & Finetune | marl.algos.mappo(hyperparam_source=$ENV) |
| desarrollar y depurar | marl.algos.mappo(hyperparam_source="test") |
| Envir de terceros | marl.algos.mappo(hyperparam_source="common") |
Aquí hay un gráfico que describe las características de cada algoritmo:
| algoritmo | Modo de tarea de soporte | acción discreta | acción continua | Tipo de política |
|---|---|---|---|---|
| IQL * | los cuatro | ✔️ | desconocido | |
| Pg | los cuatro | ✔️ | ✔️ | en la política |
| A2C | los cuatro | ✔️ | ✔️ | en la política |
| Ddpg | los cuatro | ✔️ | desconocido | |
| Trpo | los cuatro | ✔️ | ✔️ | en la política |
| PPO | los cuatro | ✔️ | ✔️ | en la política |
| COMA | los cuatro | ✔️ | en la política | |
| Maddpg | los cuatro | ✔️ | desconocido | |
| MAA2C * | los cuatro | ✔️ | ✔️ | en la política |
| Matrpo * | los cuatro | ✔️ | ✔️ | en la política |
| Mappo | los cuatro | ✔️ | ✔️ | en la política |
| Hatrpo | cooperativa | ✔️ | ✔️ | en la política |
| Happo | cooperativa | ✔️ | ✔️ | en la política |
| VDN | cooperativa | ✔️ | desconocido | |
| Qmix | cooperativa | ✔️ | desconocido | |
| FACMAC | cooperativa | ✔️ | desconocido | |
| VDAC | cooperativa | ✔️ | ✔️ | en la política |
| VDPPO * | cooperativa | ✔️ | ✔️ | en la política |
* Los cuatro : cooperativo colaborativo competitivo mixto
IQL es la versión de múltiples agentes de Q Learning. MAA2C y MATRPO son la versión centralizada de A2C y TRPO. VDPPO es la versión de descomposición de valor de PPO.
Un modelo de agente consta de dos partes, encoder y core arch . encoder será construido por Marllib de acuerdo con el espacio de observación. Elija mlp , gru o lstm como desee construir el modelo completo.
| arco modelo | Ejemplo de API |
|---|---|
| MLP | marl.build_model(env, algo, {"core_arch": "mlp") |
| Gru | marl.build_model(env, algo, {"core_arch": "gru"}) |
| LSTM | marl.build_model(env, algo, {"core_arch": "lstm"}) |
| Arco de codificador | marl.build_model(env, algo, {"core_arch": "gru", "encode_layer": "128-256"}) |
| configuración | Ejemplo de API |
|---|---|
| tren | algo.fit(env, model) |
| depurar | algo.fit(env, model, local_mode=True) |
| condición de parada | algo.fit(env, model, stop={'episode_reward_mean': 2000, 'timesteps_total': 10000000}) |
| intercambio de políticas | algo.fit(env, model, share_policy='all') # or 'group' / 'individual' |
| Guardar modelo | algo.fit(env, model, checkpoint_freq=100, checkpoint_end=True) |
| GPU acelerar | algo.fit(env, model, local_mode=False, num_gpus=1) |
| CPU acelerar | algo.fit(env, model, local_mode=False, num_workers=5) |
from marllib import marl
# prepare env
env = marl . make_env ( environment_name = "smac" , map_name = "5m_vs_6m" )
# initialize algorithm with appointed hyper-parameters
mappo = marl . algos . mappo ( hyperparam_source = "smac" )
# build agent model based on env + algorithms + user preference
model = marl . build_model ( env , mappo , { "core_arch" : "gru" , "encode_layer" : "128-256" })
# start training
mappo . fit (
env , model ,
stop = { "timesteps_total" : 1000000 },
checkpoint_freq = 100 ,
share_policy = "group"
)
# rendering
mappo . render (
env , model ,
local_mode = True ,
restore_path = { 'params_path' : "checkpoint/params.json" ,
'model_path' : "checkpoint/checkpoint-10" }
)En el directorio de trabajo actual, puede encontrar todos los datos de capacitación (archivos de registro y flujo de tensor), así como los modelos guardados. Para visualizar la curva de aprendizaje, puede usar TensorBoard. Siga los pasos a continuación:
pip install tensorboardtensorboard --logdir .Alternativamente, puede consultar este tutorial para obtener instrucciones más detalladas.
Para una lista de todos los resultados existentes, puede visitar este enlace. Tenga en cuenta que estos resultados se obtuvieron de una versión anterior de Marllib, lo que puede conducir a inconsistencias en comparación con los resultados actuales.
Marllib proporciona algunos ejemplos prácticos para que pueda referirse.
ray.tune . ¡Pruebe los ejemplos MPE + MAPPO en Google Colaboratory! Aquí hay más documentos de tutoriales disponibles.
Está disponible una colección de documentos de investigación y revisión de aprendizaje de refuerzo de múltiples agentes (MARL). Los documentos se han organizado en función de su fecha de publicación y su evaluación de los entornos correspondientes.
Algoritmos: entornos:
| Canal | Enlace |
|---|---|
| Asuntos | Problemas de Github |
El lanzamiento de la hoja de ruta para el futuro está disponible en Roadmap.md.
Somos un equipo pequeño en aprendizaje de refuerzo de múltiples agentes, ¡y tomaremos toda la ayuda que podamos obtener! Si desea involucrarse, aquí hay información sobre las pautas de contribución y cómo probar el código localmente.
Puede contribuir de múltiples maneras, por ejemplo, informar errores, escribir o traducir documentación, revisar o refactorizar código, solicitar o implementar nuevas funciones, etc.
Si usa Marllib en su investigación, cite el documento de Marllib.
@article{hu2022marllib,
author = {Siyi Hu and Yifan Zhong and Minquan Gao and Weixun Wang and Hao Dong and Xiaodan Liang and Zhihui Li and Xiaojun Chang and Yaodong Yang},
title = {MARLlib: A Scalable and Efficient Multi-agent Reinforcement Learning Library},
journal = {Journal of Machine Learning Research},
year = {2023},
}Obras que se basan o colaboran estrechamente con Marllib <ink>
@InProceedings{hu2022policy,
title={Policy Diagnosis via Measuring Role Diversity in Cooperative Multi-agent {RL}},
author={Hu, Siyi and Xie, Chuanlong and Liang, Xiaodan and Chang, Xiaojun},
booktitle={Proceedings of the 39th International Conference on Machine Learning},
year={2022},
}
@misc{zhong2023heterogeneousagent,
title={Heterogeneous-Agent Reinforcement Learning},
author={Yifan Zhong and Jakub Grudzien Kuba and Siyi Hu and Jiaming Ji and Yaodong Yang},
archivePrefix={arXiv},
year={2023},
}

