MARLlib
v1.0.3
| ❗ News |
|---|
| March 2023 ⚓We are excited to announce that a major update has just been released. For detailed version information, please refer to the version info. |
| May 2023 Exciting news! MARLlib now supports five more tasks: MATE, GoBigger, Overcooked-AI, MAPDN, and AirCombat. Give them a try! |
| June 2023 OpenAI: Hide and Seek and SISL environments are incorporated into MARLlib. |
| Aug 2023 ?MARLlib has been accepted for publication in JMLR. |
| Sept 2023 Latest PettingZoo with Gymnasium are compatiable within MARLlib. |
| Nov 2023 We are currently in the process of creating a hands-on MARL book and aim to release the draft by the end of 2023. |
Multi-agent Reinforcement Learning Library (MARLlib) is a MARL library that utilizes Ray and one of its toolkits RLlib. It offers a comprehensive platform for developing, training, and testing MARL algorithms across various tasks and environments.
Here's an example of how MARLlib can be used:
from marllib import marl
# prepare env
env = marl.make_env(environment_name="mpe", map_name="simple_spread", force_coop=True)
# initialize algorithm with appointed hyper-parameters
mappo = marl.algos.mappo(hyperparam_source='mpe')
# build agent model based on env + algorithms + user preference
model = marl.build_model(env, mappo, {"core_arch": "mlp", "encode_layer": "128-256"})
# start training
mappo.fit(env, model, stop={'timesteps_total': 1000000}, share_policy='group')Here we provide a table for the comparison of MARLlib and existing work.
| Library | Supported Env | Algorithm | Parameter Sharing | Model |
|---|---|---|---|---|
| PyMARL | 1 cooperative | 5 | share | GRU |
| PyMARL2 | 2 cooperative | 11 | share | MLP + GRU |
| MAPPO Benchmark | 4 cooperative | 1 | share + separate | MLP + GRU |
| MAlib | 4 self-play | 10 | share + group + separate | MLP + LSTM |
| EPyMARL | 4 cooperative | 9 | share + separate | GRU |
| HARL | 8 cooperative | 9 | share + separate | MLP + CNN + GRU |
| MARLlib | 17 no task mode restriction | 18 | share + group + separate + customizable | MLP + CNN + GRU + LSTM |
| Library | Github Stars | Documentation | Issues Open | Activity | Last Update |
|---|---|---|---|---|---|
| PyMARL | |||||
| PyMARL2 | |||||
| MAPPO Benchmark | |||||
| MAlib | |||||
| EPyMARL | |||||
| HARL* | |||||
| MARLlib |
* HARL is the latest MARL library that has been recently released:fire:. If cutting-edge MARL algorithms with state-of-the-art performance are your target, HARL is definitely worth a look!
? MARLlib offers several key features that make it stand out:
Using MARLlib, you can take advantage of various benefits, such as:
Note: Please note that at this time, MARLlib is only compatible with Linux operating systems.
First, install MARLlib dependencies to guarantee basic usage. following this guide, finally install patches for RLlib.
$ conda create -n marllib python=3.8 # or 3.9
$ conda activate marllib
$ git clone https://github.com/Replicable-MARL/MARLlib.git && cd MARLlib
$ pip install -r requirements.txtPlease follow this guide.
Note: We recommend the gym version around 0.20.0.
pip install "gym==0.20.0"Fix bugs of RLlib using patches by running the following command:
$ cd /Path/To/MARLlib/marllib/patch
$ python add_patch.py -y$ pip install --upgrade pip
$ pip install marllibWe provide a Dockerfile for building the MARLlib docker image in MARLlib/docker/Dockerfile and a devcontainer setup in MARLlib/.devcontainer folder. If you use the devcontainer, one thing to note is that you may need to customise certain arguments in runArgs of devcontainer.json according to your hardware, for example the --shm-size argument.
There are four parts of configurations that take charge of the whole training process.
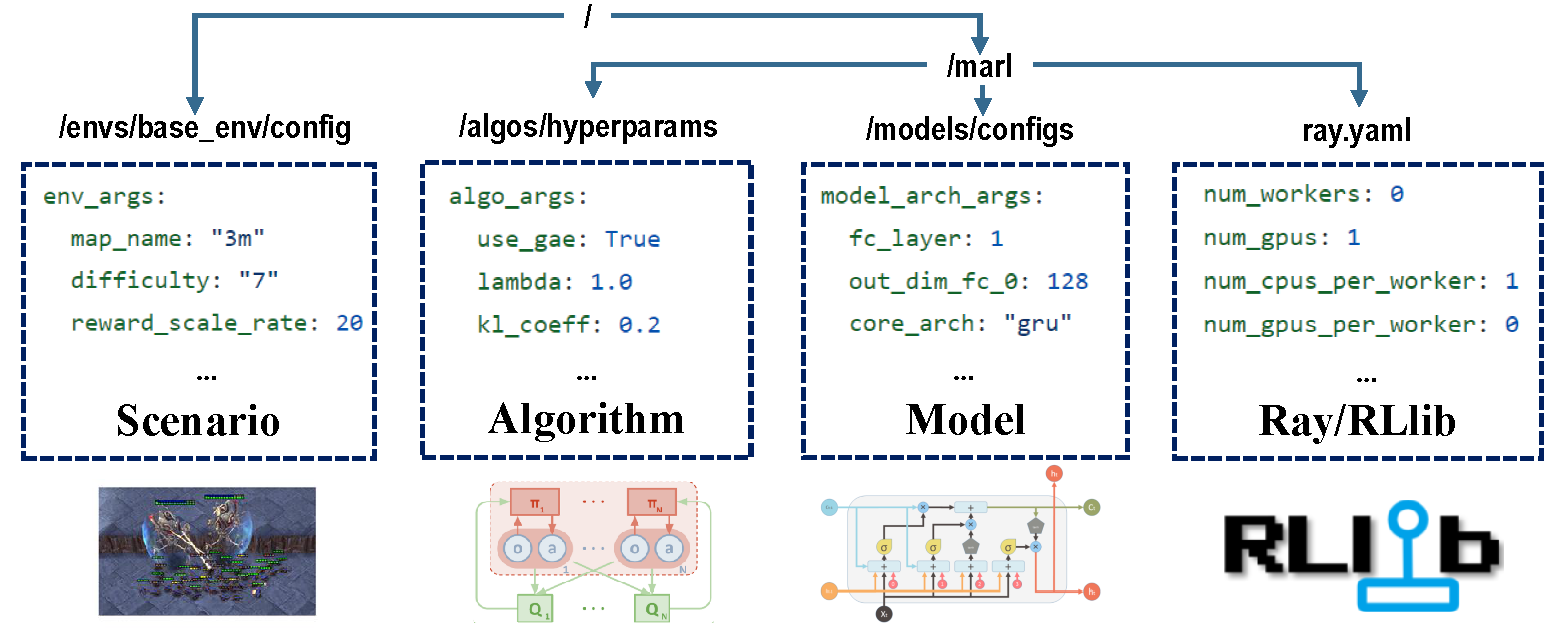
Before training, ensure all the parameters are set correctly, especially those you don't want to change.
Note: You can also modify all the pre-set parameters via MARLLib API.*
Ensure all the dependencies are installed for the environment you are running with. Otherwise, please refer to MARLlib documentation.
| task mode | api example |
|---|---|
| cooperative | marl.make_env(environment_name="mpe", map_name="simple_spread", force_coop=True) |
| collaborative | marl.make_env(environment_name="mpe", map_name="simple_spread") |
| competitive | marl.make_env(environment_name="mpe", map_name="simple_adversary") |
| mixed | marl.make_env(environment_name="mpe", map_name="simple_crypto") |
Most of the popular environments in MARL research are supported by MARLlib:
| Env Name | Learning Mode | Observability | Action Space | Observations |
|---|---|---|---|---|
| LBF | cooperative + collaborative | Both | Discrete | 1D |
| RWARE | cooperative | Partial | Discrete | 1D |
| MPE | cooperative + collaborative + mixed | Both | Both | 1D |
| SISL | cooperative + collaborative | Full | Both | 1D |
| SMAC | cooperative | Partial | Discrete | 1D |
| MetaDrive | collaborative | Partial | Continuous | 1D |
| MAgent | collaborative + mixed | Partial | Discrete | 2D |
| Pommerman | collaborative + competitive + mixed | Both | Discrete | 2D |
| MAMuJoCo | cooperative | Full | Continuous | 1D |
| GRF | collaborative + mixed | Full | Discrete | 2D |
| Hanabi | cooperative | Partial | Discrete | 1D |
| MATE | cooperative + mixed | Partial | Both | 1D |
| GoBigger | cooperative + mixed | Both | Continuous | 1D |
| Overcooked-AI | cooperative | Full | Discrete | 1D |
| PDN | cooperative | Partial | Continuous | 1D |
| AirCombat | cooperative + mixed | Partial | MultiDiscrete | 1D |
| HideAndSeek | competitive + mixed | Partial | MultiDiscrete | 1D |
Each environment has a readme file, standing as the instruction for this task, including env settings, installation, and important notes.
| running target | api example |
|---|---|
| train & finetune | marl.algos.mappo(hyperparam_source=$ENV) |
| develop & debug | marl.algos.mappo(hyperparam_source="test") |
| 3rd party env | marl.algos.mappo(hyperparam_source="common") |
Here is a chart describing the characteristics of each algorithm:
| algorithm | support task mode | discrete action | continuous action | policy type |
|---|---|---|---|---|
| IQL* | all four | ✔️ | off-policy | |
| PG | all four | ✔️ | ✔️ | on-policy |
| A2C | all four | ✔️ | ✔️ | on-policy |
| DDPG | all four | ✔️ | off-policy | |
| TRPO | all four | ✔️ | ✔️ | on-policy |
| PPO | all four | ✔️ | ✔️ | on-policy |
| COMA | all four | ✔️ | on-policy | |
| MADDPG | all four | ✔️ | off-policy | |
| MAA2C* | all four | ✔️ | ✔️ | on-policy |
| MATRPO* | all four | ✔️ | ✔️ | on-policy |
| MAPPO | all four | ✔️ | ✔️ | on-policy |
| HATRPO | cooperative | ✔️ | ✔️ | on-policy |
| HAPPO | cooperative | ✔️ | ✔️ | on-policy |
| VDN | cooperative | ✔️ | off-policy | |
| QMIX | cooperative | ✔️ | off-policy | |
| FACMAC | cooperative | ✔️ | off-policy | |
| VDAC | cooperative | ✔️ | ✔️ | on-policy |
| VDPPO* | cooperative | ✔️ | ✔️ | on-policy |
*all four: cooperative collaborative competitive mixed
IQL is the multi-agent version of Q learning. MAA2C and MATRPO are the centralized version of A2C and TRPO. VDPPO is the value decomposition version of PPO.
An agent model consists of two parts, encoder and core arch.
encoder will be constructed by MARLlib according to the observation space.
Choose mlp, gru, or lstm as you like to build the complete model.
| model arch | api example |
|---|---|
| MLP | marl.build_model(env, algo, {"core_arch": "mlp") |
| GRU | marl.build_model(env, algo, {"core_arch": "gru"}) |
| LSTM | marl.build_model(env, algo, {"core_arch": "lstm"}) |
| Encoder Arch | marl.build_model(env, algo, {"core_arch": "gru", "encode_layer": "128-256"}) |
| setting | api example |
|---|---|
| train | algo.fit(env, model) |
| debug | algo.fit(env, model, local_mode=True) |
| stop condition | algo.fit(env, model, stop={'episode_reward_mean': 2000, 'timesteps_total': 10000000}) |
| policy sharing | algo.fit(env, model, share_policy='all') # or 'group' / 'individual' |
| save model | algo.fit(env, model, checkpoint_freq=100, checkpoint_end=True) |
| GPU accelerate | algo.fit(env, model, local_mode=False, num_gpus=1) |
| CPU accelerate | algo.fit(env, model, local_mode=False, num_workers=5) |
from marllib import marl
# prepare env
env = marl.make_env(environment_name="smac", map_name="5m_vs_6m")
# initialize algorithm with appointed hyper-parameters
mappo = marl.algos.mappo(hyperparam_source="smac")
# build agent model based on env + algorithms + user preference
model = marl.build_model(env, mappo, {"core_arch": "gru", "encode_layer": "128-256"})
# start training
mappo.fit(
env, model,
stop={"timesteps_total": 1000000},
checkpoint_freq=100,
share_policy="group"
)
# rendering
mappo.render(
env, model,
local_mode=True,
restore_path={'params_path': "checkpoint/params.json",
'model_path': "checkpoint/checkpoint-10"}
)Under the current working directory, you can find all the training data (logging and TensorFlow files) as well as the saved models. To visualize the learning curve, you can use Tensorboard. Follow the steps below:
pip install tensorboardtensorboard --logdir .Alternatively, you can refer to this tutorial for more detailed instructions.
For a list of all the existing results, you can visit this link. Please note that these results were obtained from an older version of MARLlib, which may lead to inconsistencies when compared to the current results.
MARLlib provides some practical examples for you to refer to.
ray.tune.Try MPE + MAPPO examples on Google Colaboratory! More tutorial documentations are available here.
A collection of research and review papers of multi-agent reinforcement learning (MARL) is available. The papers have been organized based on their publication date and their evaluation of the corresponding environments.
Algorithms: Environments:
| Channel | Link |
|---|---|
| Issues | GitHub Issues |
The roadmap to the future release is available in ROADMAP.md.
We are a small team on multi-agent reinforcement learning, and we will take all the help we can get! If you would like to get involved, here is information on contribution guidelines and how to test the code locally.
You can contribute in multiple ways, e.g., reporting bugs, writing or translating documentation, reviewing or refactoring code, requesting or implementing new features, etc.
If you use MARLlib in your research, please cite the MARLlib paper.
@article{hu2022marllib,
author = {Siyi Hu and Yifan Zhong and Minquan Gao and Weixun Wang and Hao Dong and Xiaodan Liang and Zhihui Li and Xiaojun Chang and Yaodong Yang},
title = {MARLlib: A Scalable and Efficient Multi-agent Reinforcement Learning Library},
journal = {Journal of Machine Learning Research},
year = {2023},
}Works that are based on or closely collaborate with MARLlib <link>
@InProceedings{hu2022policy,
title={Policy Diagnosis via Measuring Role Diversity in Cooperative Multi-agent {RL}},
author={Hu, Siyi and Xie, Chuanlong and Liang, Xiaodan and Chang, Xiaojun},
booktitle={Proceedings of the 39th International Conference on Machine Learning},
year={2022},
}
@misc{zhong2023heterogeneousagent,
title={Heterogeneous-Agent Reinforcement Learning},
author={Yifan Zhong and Jakub Grudzien Kuba and Siyi Hu and Jiaming Ji and Yaodong Yang},
archivePrefix={arXiv},
year={2023},
}

