MARLlib
v1.0.3
| ❗ News |
|---|
| Mars 2023 ⚓Nous sommes ravis d'annoncer qu'une mise à jour majeure vient d'être publiée. Pour des informations détaillées sur la version, veuillez vous référer aux informations de version. |
| Mai 2023 Nouvelles passionnantes! Marllib prend maintenant en charge cinq autres tâches: Mate, Gobigger, Overcooked-AI, Mapdn et Aircombat. Essayez-les! |
| Juin 2023 Openai: Les environnements masqués et SISL sont incorporés dans Marllib. |
| Août 2023 ? Marllib a été accepté pour publication dans JMLR. |
| Sept 2023 Le dernier Pettingzoo avec le gymnase est compatiable au sein de Marllib. |
| Nov 2023 Nous sommes actuellement en train de créer un livre Marl pratique et de publier le projet d'ici la fin de 2023. |
La bibliothèque d'apprentissage en renforcement multi-agents (Marllib) est une bibliothèque Marl qui utilise Ray et l'une de ses kits d'outils Rllib . Il propose une plate-forme complète pour développer, formation et tester des algorithmes de marl sur diverses tâches et environnements.
Voici un exemple de la façon dont Marllib peut être utilisé:
from marllib import marl
# prepare env
env = marl . make_env ( environment_name = "mpe" , map_name = "simple_spread" , force_coop = True )
# initialize algorithm with appointed hyper-parameters
mappo = marl . algos . mappo ( hyperparam_source = 'mpe' )
# build agent model based on env + algorithms + user preference
model = marl . build_model ( env , mappo , { "core_arch" : "mlp" , "encode_layer" : "128-256" })
# start training
mappo . fit ( env , model , stop = { 'timesteps_total' : 1000000 }, share_policy = 'group' )Ici, nous fournissons un tableau pour la comparaison de Marllib et des travaux existants.
| Bibliothèque | Env soutenu | Algorithme | Partage des paramètres | Modèle |
|---|---|---|---|---|
| Pymarl | 1 coopérative | 5 | partager | Gru |
| PyMarl2 | 2 coopérative | 11 | partager | MLP + GRU |
| Mappo Benchmark | 4 coopérative | 1 | Partager + séparer | MLP + GRU |
| Maline | 4 auto-play | 10 | partager + groupe + séparé | MLP + LSTM |
| Épymarl | 4 coopérative | 9 | Partager + séparer | Gru |
| Harl | 8 coopérative | 9 | Partager + séparer | MLP + CNN + GRU |
| Marllib | 17 Aucune restriction en mode tâche | 18 | partager + groupe + séparé + personnalisable | MLP + CNN + GRU + LSTM |
| Bibliothèque | Étoiles github | Documentation | Les problèmes s'ouvrent | Activité | Dernière mise à jour |
|---|---|---|---|---|---|
| Pymarl | |||||
| PyMarl2 | |||||
| Mappo Benchmark | |||||
| Maline | |||||
| Épymarl | |||||
| Harl * | |||||
| Marllib |
* Harl est la dernière bibliothèque Marl qui a été récemment publiée: Fire:. Si des algorithmes de marl de pointe avec des performances de pointe sont votre cible, Harl vaut vraiment le coup!
? Marllib propose plusieurs fonctionnalités clés qui le distinguent:
En utilisant Marllib, vous pouvez profiter de divers avantages, tels que:
Remarque : veuillez noter qu'à ce moment, Marllib n'est compatible qu'avec les systèmes d'exploitation Linux.
Tout d'abord, installez les dépendances Marllib pour garantir l'utilisation de base. Suivant ce guide, installez enfin des correctifs pour RLIB.
$ conda create -n marllib python=3.8 # or 3.9
$ conda activate marllib
$ git clone https://github.com/Replicable-MARL/MARLlib.git && cd MARLlib
$ pip install -r requirements.txtVeuillez suivre ce guide.
Remarque : Nous recommandons la version gymnologique autour de 0.20.0.
pip install " gym==0.20.0 " Correction des bogues de RLIB à l'aide de correctifs en exécutant la commande suivante:
$ cd /Path/To/MARLlib/marllib/patch
$ python add_patch.py -y$ pip install --upgrade pip
$ pip install marllib Nous fournissons un Dockerfile pour construire l'image Marllib Docker dans MARLlib/docker/Dockerfile et une configuration DevContainer dans le dossier MARLlib/.devcontainer . Si vous utilisez le DevContainer, une chose à noter est que vous devrez peut-être personnaliser certains arguments dans runArgs de devcontainer.json en fonction de votre matériel, par exemple l'argument --shm-size .
Il y a quatre parties de configurations qui prennent en charge l'ensemble du processus de formation.
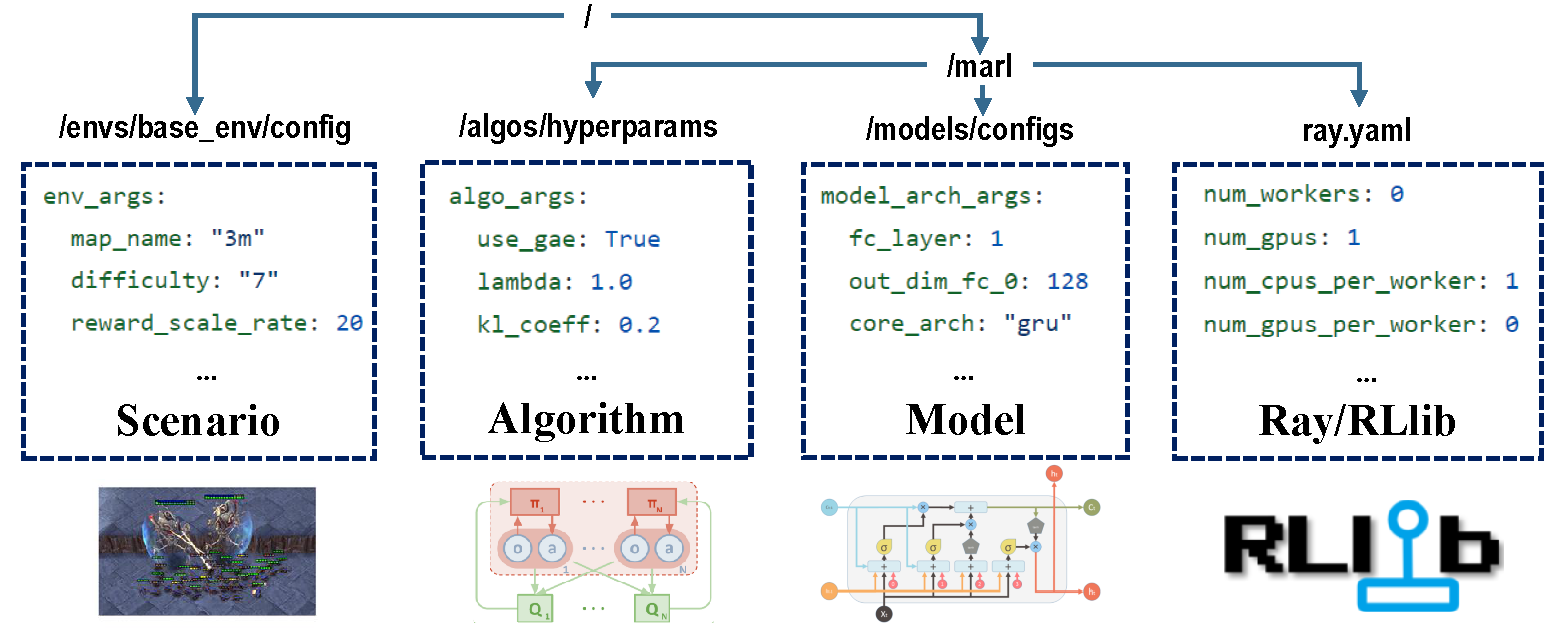
Avant l'entraînement, assurez-vous que tous les paramètres sont réglés correctement, en particulier ceux que vous ne voulez pas changer.
Remarque : vous pouvez également modifier tous les paramètres prédéfinis via l'API Marllib. *
Assurez-vous que toutes les dépendances sont installées pour l'environnement avec lequel vous exécutez. Sinon, veuillez vous référer à la documentation Marllib.
| mode tâche | Exemple API |
|---|---|
| coopérative | marl.make_env(environment_name="mpe", map_name="simple_spread", force_coop=True) |
| collaboratif | marl.make_env(environment_name="mpe", map_name="simple_spread") |
| compétitif | marl.make_env(environment_name="mpe", map_name="simple_adversary") |
| mixte | marl.make_env(environment_name="mpe", map_name="simple_crypto") |
La plupart des environnements populaires de la recherche Marl sont soutenus par Marllib:
| Nom env | Mode d'apprentissage | Observabilité | Espace d'action | Observations |
|---|---|---|---|---|
| Lbf | coopérative + collaborative | Les deux | Discret | 1D |
| Rware | coopérative | Partiel | Discret | 1D |
| MPE | coopérative + collaborative + mixte | Les deux | Les deux | 1D |
| Sisl | coopérative + collaborative | Complet | Les deux | 1D |
| Smac | coopérative | Partiel | Discret | 1D |
| Métadrive | collaboratif | Partiel | Continu | 1D |
| Magent | collaboratif + mixte | Partiel | Discret | 2d |
| Pomimer | collaboratif + compétitif + mixte | Les deux | Discret | 2d |
| Mamujoco | coopérative | Complet | Continu | 1D |
| Grf | collaboratif + mixte | Complet | Discret | 2d |
| Hanabi | coopérative | Partiel | Discret | 1D |
| COPAIN | coopérative + mixte | Partiel | Les deux | 1D |
| Gobigger | coopérative + mixte | Les deux | Continu | 1D |
| Trop cuit-cuit | coopérative | Complet | Discret | 1D |
| PDN | coopérative | Partiel | Continu | 1D |
| Aérodrome | coopérative + mixte | Partiel | Béton multidisque | 1D |
| Hideandseek | compétitif + mixte | Partiel | Béton multidisque | 1D |
Chaque environnement a un fichier ReadMe, debout comme instruction de cette tâche, y compris les paramètres Env, l'installation et les notes importantes.
| cible de course | Exemple API |
|---|---|
| Train et Finetune | marl.algos.mappo(hyperparam_source=$ENV) |
| développer et déboguer | marl.algos.mappo(hyperparam_source="test") |
| Tiers env | marl.algos.mappo(hyperparam_source="common") |
Voici un graphique décrivant les caractéristiques de chaque algorithme:
| algorithme | Mode de tâche de support | action discrète | action continue | type de politique |
|---|---|---|---|---|
| Iql * | les quatre | ✔️ | éteint | |
| P. | les quatre | ✔️ | ✔️ | politique |
| A2C | les quatre | ✔️ | ✔️ | politique |
| Ddpg | les quatre | ✔️ | éteint | |
| Trpo | les quatre | ✔️ | ✔️ | politique |
| PPO | les quatre | ✔️ | ✔️ | politique |
| COMA | les quatre | ✔️ | politique | |
| Maddpg | les quatre | ✔️ | éteint | |
| Maa2c * | les quatre | ✔️ | ✔️ | politique |
| Matrpo * | les quatre | ✔️ | ✔️ | politique |
| Mappo | les quatre | ✔️ | ✔️ | politique |
| Hatrpo | coopérative | ✔️ | ✔️ | politique |
| Happo | coopérative | ✔️ | ✔️ | politique |
| Vdn | coopérative | ✔️ | éteint | |
| Qmix | coopérative | ✔️ | éteint | |
| Facmac | coopérative | ✔️ | éteint | |
| Vdac | coopérative | ✔️ | ✔️ | politique |
| Vdppo * | coopérative | ✔️ | ✔️ | politique |
* tous les quatre : coopérative collaborative compétitive mixte
IQL est la version multi-agents de Q Learning. MAA2C et Matrpo sont la version centralisée de A2C et TRPO. VDPPO est la version de décomposition de valeur de PPO.
Un modèle d'agent se compose de deux parties, encoder et core arch . encoder sera construit par Marllib en fonction de l'espace d'observation. Choisissez mlp , gru ou lstm comme vous aimez construire le modèle complet.
| arche modèle | Exemple API |
|---|---|
| MLP | marl.build_model(env, algo, {"core_arch": "mlp") |
| Gru | marl.build_model(env, algo, {"core_arch": "gru"}) |
| LSTM | marl.build_model(env, algo, {"core_arch": "lstm"}) |
| Encodeur | marl.build_model(env, algo, {"core_arch": "gru", "encode_layer": "128-256"}) |
| paramètre | Exemple API |
|---|---|
| former | algo.fit(env, model) |
| déboguer | algo.fit(env, model, local_mode=True) |
| état d'arrêt | algo.fit(env, model, stop={'episode_reward_mean': 2000, 'timesteps_total': 10000000}) |
| Partage des politiques | algo.fit(env, model, share_policy='all') # or 'group' / 'individual' |
| SAVER MODÈLE | algo.fit(env, model, checkpoint_freq=100, checkpoint_end=True) |
| GPU accélérer | algo.fit(env, model, local_mode=False, num_gpus=1) |
| CPU accélérer | algo.fit(env, model, local_mode=False, num_workers=5) |
from marllib import marl
# prepare env
env = marl . make_env ( environment_name = "smac" , map_name = "5m_vs_6m" )
# initialize algorithm with appointed hyper-parameters
mappo = marl . algos . mappo ( hyperparam_source = "smac" )
# build agent model based on env + algorithms + user preference
model = marl . build_model ( env , mappo , { "core_arch" : "gru" , "encode_layer" : "128-256" })
# start training
mappo . fit (
env , model ,
stop = { "timesteps_total" : 1000000 },
checkpoint_freq = 100 ,
share_policy = "group"
)
# rendering
mappo . render (
env , model ,
local_mode = True ,
restore_path = { 'params_path' : "checkpoint/params.json" ,
'model_path' : "checkpoint/checkpoint-10" }
)Dans le cadre du répertoire de travail actuel, vous pouvez trouver toutes les données de formation (enregistrement et fichiers TensorFlow) ainsi que les modèles enregistrés. Pour visualiser la courbe d'apprentissage, vous pouvez utiliser Tensorboard. Suivez les étapes ci-dessous:
pip install tensorboardtensorboard --logdir .Alternativement, vous pouvez vous référer à ce tutoriel pour des instructions plus détaillées.
Pour une liste de tous les résultats existants, vous pouvez visiter ce lien. Veuillez noter que ces résultats ont été obtenus à partir d'une ancienne version de Marllib, ce qui peut entraîner des incohérences par rapport aux résultats actuels.
Marllib fournit quelques exemples pratiques auxquels vous pouvez vous référer.
ray.tune . Essayez des exemples MPE + MAPPO sur Google Colaboratory! Plus de documents de tutoriel sont disponibles ici.
Une collection d'articles de recherche et de revue de l'apprentissage en renforcement multi-agents (MARL) est disponible. Les articles ont été organisés en fonction de leur date de publication et de leur évaluation des environnements correspondants.
Algorithmes: Environnements:
| Canal | Lien |
|---|---|
| Problèmes | Problèmes de github |
La feuille de route vers la future version est disponible dans la feuille de route.md.
Nous sommes une petite équipe sur l'apprentissage du renforcement multi-agents, et nous prendrons toute l'aide que nous pouvons obtenir! Si vous souhaitez vous impliquer, voici des informations sur les directives de contribution et comment tester le code localement.
Vous pouvez contribuer de multiples façons, par exemple, signaler des bogues, écrire ou traduire la documentation, examiner ou refactoriser le code, demander ou implémenter de nouvelles fonctionnalités, etc.
Si vous utilisez Marllib dans vos recherches, veuillez citer le papier Marllib.
@article{hu2022marllib,
author = {Siyi Hu and Yifan Zhong and Minquan Gao and Weixun Wang and Hao Dong and Xiaodan Liang and Zhihui Li and Xiaojun Chang and Yaodong Yang},
title = {MARLlib: A Scalable and Efficient Multi-agent Reinforcement Learning Library},
journal = {Journal of Machine Learning Research},
year = {2023},
}Des œuvres qui sont basées sur ou collaborent étroitement avec Marllib <ink>
@InProceedings{hu2022policy,
title={Policy Diagnosis via Measuring Role Diversity in Cooperative Multi-agent {RL}},
author={Hu, Siyi and Xie, Chuanlong and Liang, Xiaodan and Chang, Xiaojun},
booktitle={Proceedings of the 39th International Conference on Machine Learning},
year={2022},
}
@misc{zhong2023heterogeneousagent,
title={Heterogeneous-Agent Reinforcement Learning},
author={Yifan Zhong and Jakub Grudzien Kuba and Siyi Hu and Jiaming Ji and Yaodong Yang},
archivePrefix={arXiv},
year={2023},
}

