MARLlib
v1.0.3
| ❗ข่าว |
|---|
| มีนาคม 2566 ⚓เรารู้สึกตื่นเต้นที่จะประกาศว่าการอัปเดตครั้งใหญ่เพิ่งเปิดตัว สำหรับข้อมูลเวอร์ชันโดยละเอียดโปรดดูข้อมูลเวอร์ชัน |
| พฤษภาคม 2023 ข่าวที่น่าตื่นเต้น! ตอนนี้ Marllib รองรับงานอีกห้างาน: Mate, Gobigger, Overcooked-AI, MAPDN และ Aircombat ลองพวกเขา! |
| มิถุนายน 2023 Openai: ซ่อนและค้นหาและสภาพแวดล้อม SISL ถูกรวมเข้ากับ Marllib |
| ส.ค. 2023 ? Marllib ได้รับการยอมรับสำหรับการตีพิมพ์ใน JMLR |
| ก.ย. 2023 Pettingzoo ล่าสุดที่มีโรงยิมสามารถใช้งานได้ภายใน Marllib |
| พ.ย. 2023 ขณะนี้เราอยู่ในขั้นตอนการสร้างหนังสือ Marl บนมือและตั้งเป้าหมายที่จะปล่อยร่างภายในสิ้นปี 2566 |
ห้องสมุดการเรียนรู้การเสริมแรงแบบหลายตัวแทน (Marllib) เป็น ห้องสมุด Marl ที่ใช้ Ray และหนึ่งในชุดเครื่องมือ RLLIB มันมีแพลตฟอร์มที่ครอบคลุมสำหรับการพัฒนาฝึกอบรมและทดสอบอัลกอริทึม Marl ในงานและสภาพแวดล้อมที่หลากหลาย
นี่คือตัวอย่างของวิธีการใช้ marllib:
from marllib import marl
# prepare env
env = marl . make_env ( environment_name = "mpe" , map_name = "simple_spread" , force_coop = True )
# initialize algorithm with appointed hyper-parameters
mappo = marl . algos . mappo ( hyperparam_source = 'mpe' )
# build agent model based on env + algorithms + user preference
model = marl . build_model ( env , mappo , { "core_arch" : "mlp" , "encode_layer" : "128-256" })
# start training
mappo . fit ( env , model , stop = { 'timesteps_total' : 1000000 }, share_policy = 'group' )ที่นี่เรามีตารางสำหรับการเปรียบเทียบ Marllib และงานที่มีอยู่
| ห้องสมุด | Env ที่รองรับ | อัลกอริทึม | การแชร์พารามิเตอร์ | แบบอย่าง |
|---|---|---|---|---|
| พิสมาร์ล | 1 สหกรณ์ | 5 | แบ่งปัน | กรุ |
| Pymarl2 | 2 สหกรณ์ | 11 | แบ่งปัน | MLP + Gru |
| เกณฑ์มาตรฐาน Mappo | 4 สหกรณ์ | 1 | แบ่งปัน + แยกกัน | MLP + Gru |
| มาลิบ | 4 เล่นเอง | 10 | แบ่งปัน + กลุ่ม + แยกกัน | MLP + LSTM |
| Epymarl | 4 สหกรณ์ | 9 | แบ่งปัน + แยกกัน | กรุ |
| อ่าว | 8 สหกรณ์ | 9 | แบ่งปัน + แยกกัน | MLP + CNN + GRU |
| การแต่งงาน | 17 ไม่มีการ จำกัด โหมดงาน | 18 | แบ่งปัน + กลุ่ม + แยก + ปรับแต่งได้ | MLP + CNN + GRU + LSTM |
| ห้องสมุด | GitHub Stars | เอกสาร | ปัญหาเปิดออก | กิจกรรม | อัปเดตล่าสุด |
|---|---|---|---|---|---|
| พิสมาร์ล | |||||
| Pymarl2 | |||||
| เกณฑ์มาตรฐาน Mappo | |||||
| มาลิบ | |||||
| Epymarl | |||||
| Harl * | |||||
| การแต่งงาน |
* Harl เป็นห้องสมุด Marl ล่าสุดที่เพิ่งเปิดตัว: Fire: หากอัลกอริทึม Marl ที่ทันสมัยพร้อมการแสดงที่ล้ำสมัยเป็นเป้าหมายของคุณ Harl ก็คุ้มค่าที่จะดู!
- Marllib มีคุณสมบัติสำคัญหลายประการที่ทำให้โดดเด่น:
การใช้ marllib คุณสามารถใช้ประโยชน์จากผลประโยชน์ต่าง ๆ เช่น:
หมายเหตุ : โปรดทราบว่าในเวลานี้ Marllib เข้ากันได้กับระบบปฏิบัติการ Linux เท่านั้น
ขั้นแรกให้ติดตั้งการพึ่งพา marllib เพื่อรับประกันการใช้งานขั้นพื้นฐาน ตามคำแนะนำนี้ในที่สุดก็ติดตั้งแพตช์สำหรับ rllib
$ conda create -n marllib python=3.8 # or 3.9
$ conda activate marllib
$ git clone https://github.com/Replicable-MARL/MARLlib.git && cd MARLlib
$ pip install -r requirements.txtโปรดทำตามคำแนะนำนี้
หมายเหตุ : เราขอแนะนำรุ่นยิมประมาณ 0.20.0
pip install " gym==0.20.0 " แก้ไขข้อบกพร่องของ RLLIB โดยใช้โปรแกรมแก้ไขโดยเรียกใช้คำสั่งต่อไปนี้:
$ cd /Path/To/MARLlib/marllib/patch
$ python add_patch.py -y$ pip install --upgrade pip
$ pip install marllib เราให้บริการ DockerFile สำหรับการสร้างภาพ Marllib Docker ใน MARLlib/docker/Dockerfile และการตั้งค่า devContainer ในโฟลเดอร์ MARLlib/.devcontainer หากคุณใช้ devContainer สิ่งหนึ่งที่ควรทราบคือคุณอาจต้องปรับแต่งอาร์กิวเมนต์บางอย่างใน runArgs ของ devcontainer.json ตามฮาร์ดแวร์ของคุณเช่นอาร์กิวเมนต์ --shm-size
มีสี่ส่วนของการกำหนดค่าที่รับผิดชอบกระบวนการฝึกอบรมทั้งหมด
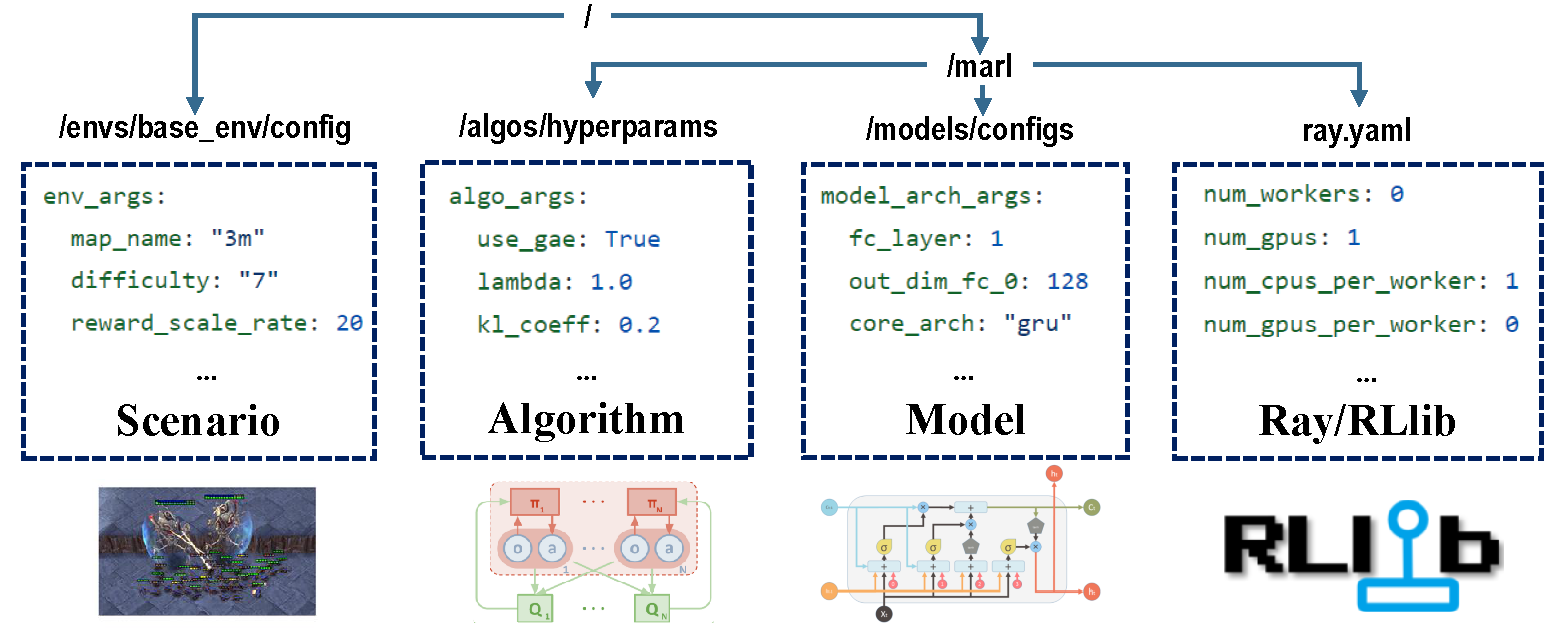
ก่อนการฝึกอบรมให้แน่ใจว่ามีการตั้งค่าพารามิเตอร์ทั้งหมดอย่างถูกต้องโดยเฉพาะอย่างยิ่งที่คุณไม่ต้องการเปลี่ยนแปลง
หมายเหตุ : คุณยังสามารถแก้ไขพารามิเตอร์ที่ตั้งค่าไว้ล่วงหน้าทั้งหมดผ่าน Marllib API*
ตรวจสอบให้แน่ใจว่ามีการติดตั้งการพึ่งพาทั้งหมดสำหรับสภาพแวดล้อมที่คุณใช้งาน มิฉะนั้นโปรดดูเอกสาร Marllib
| โหมดงาน | ตัวอย่าง API |
|---|---|
| สหกรณ์ | marl.make_env(environment_name="mpe", map_name="simple_spread", force_coop=True) |
| ร่วมกัน | marl.make_env(environment_name="mpe", map_name="simple_spread") |
| การแข่งขัน | marl.make_env(environment_name="mpe", map_name="simple_adversary") |
| ผสมกัน | marl.make_env(environment_name="mpe", map_name="simple_crypto") |
สภาพแวดล้อมที่ได้รับความนิยมส่วนใหญ่ในการวิจัย Marl ได้รับการสนับสนุนโดย Marllib:
| ชื่อ env | โหมดการเรียนรู้ | ความสังเกตได้ | พื้นที่ดำเนินการ | การสังเกตการณ์ |
|---|---|---|---|---|
| LBF | สหกรณ์ + การทำงานร่วมกัน | ทั้งคู่ | ไม่ต่อเนื่อง | 1d |
| เครื่องรูด | สหกรณ์ | บางส่วน | ไม่ต่อเนื่อง | 1d |
| MPE | สหกรณ์ + การทำงานร่วมกัน + ผสม | ทั้งคู่ | ทั้งคู่ | 1d |
| SISL | สหกรณ์ + การทำงานร่วมกัน | เต็ม | ทั้งคู่ | 1d |
| smac | สหกรณ์ | บางส่วน | ไม่ต่อเนื่อง | 1d |
| ข้อมูลเมตา | ร่วมกัน | บางส่วน | ต่อเนื่อง | 1d |
| เวทมนตร์ | การทำงานร่วมกัน + ผสม | บางส่วน | ไม่ต่อเนื่อง | 2d |
| ชาวบ้านพักคนชรา | การทำงานร่วมกัน + การแข่งขัน + ผสม | ทั้งคู่ | ไม่ต่อเนื่อง | 2d |
| Mamujoco | สหกรณ์ | เต็ม | ต่อเนื่อง | 1d |
| GRF | การทำงานร่วมกัน + ผสม | เต็ม | ไม่ต่อเนื่อง | 2d |
| ฮานาบิ | สหกรณ์ | บางส่วน | ไม่ต่อเนื่อง | 1d |
| เพื่อน | สหกรณ์ + ผสม | บางส่วน | ทั้งคู่ | 1d |
| Gobigger | สหกรณ์ + ผสม | ทั้งคู่ | ต่อเนื่อง | 1d |
| ปรุงสุกมากเกินไป | สหกรณ์ | เต็ม | ไม่ต่อเนื่อง | 1d |
| PDN | สหกรณ์ | บางส่วน | ต่อเนื่อง | 1d |
| เครื่องราง | สหกรณ์ + ผสม | บางส่วน | มัลติดิสเครท | 1d |
| hedeandseek | การแข่งขัน + ผสม | บางส่วน | มัลติดิสเครท | 1d |
แต่ละสภาพแวดล้อมมีไฟล์ readme ยืนเป็นคำสั่งสำหรับงานนี้รวมถึงการตั้งค่า ENV การติดตั้งและบันทึกสำคัญ
| กำลังเรียกใช้เป้าหมาย | ตัวอย่าง API |
|---|---|
| รถไฟและ Finetune | marl.algos.mappo(hyperparam_source=$ENV) |
| พัฒนาและดีบัก | marl.algos.mappo(hyperparam_source="test") |
| env ของบุคคลที่สาม | marl.algos.mappo(hyperparam_source="common") |
นี่คือแผนภูมิที่อธิบายถึงลักษณะของอัลกอริทึมแต่ละตัว:
| อัลกอริทึม | สนับสนุนโหมดงาน | การกระทำที่ไม่ต่อเนื่อง | การกระทำอย่างต่อเนื่อง | ประเภทนโยบาย |
|---|---|---|---|---|
| iql * | ทั้งสี่ | นอกนโยบาย | ||
| หน้า | ทั้งสี่ | ตามนโยบาย | ||
| A2C | ทั้งสี่ | ตามนโยบาย | ||
| DDPG | ทั้งสี่ | นอกนโยบาย | ||
| TRPO | ทั้งสี่ | ตามนโยบาย | ||
| PPO | ทั้งสี่ | ตามนโยบาย | ||
| อาการโคม่า | ทั้งสี่ | ตามนโยบาย | ||
| MADDPG | ทั้งสี่ | นอกนโยบาย | ||
| maa2c * | ทั้งสี่ | ตามนโยบาย | ||
| matrpo * | ทั้งสี่ | ตามนโยบาย | ||
| ม็อกโป | ทั้งสี่ | ตามนโยบาย | ||
| hatrpo | สหกรณ์ | ตามนโยบาย | ||
| มีความสุข | สหกรณ์ | ตามนโยบาย | ||
| VDN | สหกรณ์ | นอกนโยบาย | ||
| QMIX | สหกรณ์ | นอกนโยบาย | ||
| FACMAC | สหกรณ์ | นอกนโยบาย | ||
| VDAC | สหกรณ์ | ตามนโยบาย | ||
| vdppo * | สหกรณ์ | ตามนโยบาย |
* ทั้งสี่ : การแข่งขันแบบร่วมมือกันผสมผสาน
IQL เป็นรุ่นที่หลากหลายของการเรียนรู้ Q MAA2C และ MATRPO เป็นรุ่นกลางของ A2C และ TRPO VDPPO เป็นเวอร์ชันการสลายตัวของ PPO
โมเดลตัวแทนประกอบด้วยสองส่วนคือ encoder และ core arch encoder จะถูกสร้างขึ้นโดย Marllib ตามพื้นที่สังเกตการณ์ เลือก mlp , gru หรือ lstm ตามที่คุณต้องการสร้างโมเดลที่สมบูรณ์
| โมเดลซุ้มประตู | ตัวอย่าง API |
|---|---|
| MLP | marl.build_model(env, algo, {"core_arch": "mlp") |
| กรุ | marl.build_model(env, algo, {"core_arch": "gru"}) |
| LSTM | marl.build_model(env, algo, {"core_arch": "lstm"}) |
| chonder arch | marl.build_model(env, algo, {"core_arch": "gru", "encode_layer": "128-256"}) |
| การตั้งค่า | ตัวอย่าง API |
|---|---|
| รถไฟ | algo.fit(env, model) |
| การดีบัก | algo.fit(env, model, local_mode=True) |
| หยุดสภาพ | algo.fit(env, model, stop={'episode_reward_mean': 2000, 'timesteps_total': 10000000}) |
| การแบ่งปันนโยบาย | algo.fit(env, model, share_policy='all') # or 'group' / 'individual' |
| บันทึกโมเดล | algo.fit(env, model, checkpoint_freq=100, checkpoint_end=True) |
| GPU เร่งความเร็ว | algo.fit(env, model, local_mode=False, num_gpus=1) |
| CPU เร่งความเร็ว | algo.fit(env, model, local_mode=False, num_workers=5) |
from marllib import marl
# prepare env
env = marl . make_env ( environment_name = "smac" , map_name = "5m_vs_6m" )
# initialize algorithm with appointed hyper-parameters
mappo = marl . algos . mappo ( hyperparam_source = "smac" )
# build agent model based on env + algorithms + user preference
model = marl . build_model ( env , mappo , { "core_arch" : "gru" , "encode_layer" : "128-256" })
# start training
mappo . fit (
env , model ,
stop = { "timesteps_total" : 1000000 },
checkpoint_freq = 100 ,
share_policy = "group"
)
# rendering
mappo . render (
env , model ,
local_mode = True ,
restore_path = { 'params_path' : "checkpoint/params.json" ,
'model_path' : "checkpoint/checkpoint-10" }
)ภายใต้ไดเรกทอรีการทำงานปัจจุบันคุณสามารถค้นหาข้อมูลการฝึกอบรมทั้งหมด (การบันทึกและไฟล์ TensorFlow) รวมถึงรุ่นที่บันทึกไว้ ในการมองเห็นเส้นโค้งการเรียนรู้คุณสามารถใช้ Tensorboard ทำตามขั้นตอนด้านล่าง:
pip install tensorboardtensorboard --logdir .หรือคุณสามารถอ้างถึงบทช่วยสอนนี้สำหรับคำแนะนำโดยละเอียดเพิ่มเติม
สำหรับรายการผลลัพธ์ที่มีอยู่ทั้งหมดคุณสามารถเยี่ยมชมลิงค์นี้ โปรดทราบว่าผลลัพธ์เหล่านี้ได้มาจาก Marllib รุ่นเก่าซึ่งอาจนำไปสู่ความไม่สอดคล้องกันเมื่อเปรียบเทียบกับผลลัพธ์ปัจจุบัน
Marllib ให้ตัวอย่างที่เป็นประโยชน์เพื่อให้คุณอ้างถึง
ray.tune ลองตัวอย่าง MPE + MAPPO บน Google Colaboratory! มีเอกสารการสอนเพิ่มเติมที่นี่
มีการรวบรวมเอกสารการวิจัยและทบทวนเอกสารการเรียนรู้การเสริมแรงแบบหลายตัวแทน (MARL) เอกสารได้รับการจัดระเบียบตามวันที่ตีพิมพ์และการประเมินสภาพแวดล้อมที่สอดคล้องกัน
อัลกอริทึม: สภาพแวดล้อม:
| ช่อง | การเชื่อมโยง |
|---|---|
| ปัญหา | ปัญหา GitHub |
แผนงานสู่การเปิดตัวในอนาคตมีอยู่ใน Roadmap.md
เราเป็นทีมเล็ก ๆ ในการเรียนรู้การเสริมแรงแบบหลายตัวแทนและเราจะใช้ความช่วยเหลือทั้งหมดที่เราจะได้รับ! หากคุณต้องการมีส่วนร่วมนี่คือข้อมูลเกี่ยวกับแนวทางการสนับสนุนและวิธีการทดสอบรหัสในพื้นที่
คุณสามารถมีส่วนร่วมได้หลายวิธีเช่นการรายงานข้อบกพร่องการเขียนหรือการแปลเอกสารการตรวจสอบหรือปรับโครงสร้างรหัสการร้องขอหรือนำคุณสมบัติใหม่มาใช้ ฯลฯ
หากคุณใช้ Marllib ในการวิจัยของคุณโปรดอ้างอิงกระดาษ Marllib
@article{hu2022marllib,
author = {Siyi Hu and Yifan Zhong and Minquan Gao and Weixun Wang and Hao Dong and Xiaodan Liang and Zhihui Li and Xiaojun Chang and Yaodong Yang},
title = {MARLlib: A Scalable and Efficient Multi-agent Reinforcement Learning Library},
journal = {Journal of Machine Learning Research},
year = {2023},
}งานที่อิงกับหรือร่วมมืออย่างใกล้ชิดกับ Marllib <Link>
@InProceedings{hu2022policy,
title={Policy Diagnosis via Measuring Role Diversity in Cooperative Multi-agent {RL}},
author={Hu, Siyi and Xie, Chuanlong and Liang, Xiaodan and Chang, Xiaojun},
booktitle={Proceedings of the 39th International Conference on Machine Learning},
year={2022},
}
@misc{zhong2023heterogeneousagent,
title={Heterogeneous-Agent Reinforcement Learning},
author={Yifan Zhong and Jakub Grudzien Kuba and Siyi Hu and Jiaming Ji and Yaodong Yang},
archivePrefix={arXiv},
year={2023},
}

