MARLlib
v1.0.3
| ❗新闻 |
|---|
| 2023年3月⚓我们很高兴地宣布,刚刚发布了重大更新。有关详细版本信息,请参阅版本信息。 |
| 2023年5月令人兴奋的消息! Marllib现在还支持五项任务:伴侣,Gobigger,煮熟的AI,MAPDN和Aircombat。试试看! |
| 2023年6月Openai:隐藏和寻求,SISL环境已纳入Marllib。 |
| 2023年8月?Marllib已被接受在JMLR中出版。 |
| 2023年9月,最新的Pettingzoo与体育馆在Marllib中兼容。 |
| 2023年11月,我们目前正在创建一本动手的Marl书籍,并旨在在2023年底之前发布草案。 |
多代理增强学习库(Marllib)是一个使用Ray及其工具包RLLIB之一的MARL库。它提供了一个综合平台,用于开发,培训和测试各种任务和环境的MARL算法。
这是如何使用Marllib的一个示例:
from marllib import marl
# prepare env
env = marl . make_env ( environment_name = "mpe" , map_name = "simple_spread" , force_coop = True )
# initialize algorithm with appointed hyper-parameters
mappo = marl . algos . mappo ( hyperparam_source = 'mpe' )
# build agent model based on env + algorithms + user preference
model = marl . build_model ( env , mappo , { "core_arch" : "mlp" , "encode_layer" : "128-256" })
# start training
mappo . fit ( env , model , stop = { 'timesteps_total' : 1000000 }, share_policy = 'group' )在这里,我们提供了一个比较马里布和现有工作的表。
| 图书馆 | 支持的环境 | 算法 | 参数共享 | 模型 |
|---|---|---|---|---|
| pymarl | 1合作社 | 5 | 分享 | gru |
| pymarl2 | 2合作社 | 11 | 分享 | MLP + GRU |
| Mappo基准 | 4合作社 | 1 | 共享 +独立 | MLP + GRU |
| 马里布 | 4个自我播放 | 10 | 共享 +组 +独立 | MLP + LSTM |
| Epymarl | 4合作社 | 9 | 共享 +独立 | gru |
| 哈尔 | 8合作社 | 9 | 共享 +独立 | MLP + CNN + GRU |
| 玛莉布 | 17没有任务模式限制 | 18 | 共享 +组 +独立 +可自定义 | MLP + CNN + GRU + LSTM |
| 图书馆 | Github星星 | 文档 | 问题已经开放 | 活动 | 最后更新 |
|---|---|---|---|---|---|
| pymarl | |||||
| pymarl2 | |||||
| Mappo基准 | |||||
| 马里布 | |||||
| Epymarl | |||||
| harl * | |||||
| 玛莉布 |
* Harl是最近发布的最新MARL图书馆:Fire:。如果您的目标是具有最先进的性能的尖端MARL算法,那么Harl绝对值得一看!
? Marllib提供了几个关键功能,使其脱颖而出:
使用Marllib,您可以利用各种好处,例如:
注意:请注意,目前,Marllib仅与Linux操作系统兼容。
首先,安装Marllib依赖性以保证基本用法。遵循本指南,最后为RLLIB安装补丁。
$ conda create -n marllib python=3.8 # or 3.9
$ conda activate marllib
$ git clone https://github.com/Replicable-MARL/MARLlib.git && cd MARLlib
$ pip install -r requirements.txt请遵循本指南。
注意:我们建议在0.20.0左右的健身版本。
pip install " gym==0.20.0 " 通过运行以下命令使用补丁程序修复RLLIB的错误:
$ cd /Path/To/MARLlib/marllib/patch
$ python add_patch.py -y$ pip install --upgrade pip
$ pip install marllib我们提供了一个用于在MARLlib/docker/Dockerfile和MARLlib/.devcontainer文件夹中构建Marllib Docker图像的Dockerfile。如果您使用devcontainer,请注意的一件事是,您可能需要根据您的硬件来自runArgs devcontainer.json的某些参数,例如--shm-size参数。
配置的四个部分负责整个培训过程。
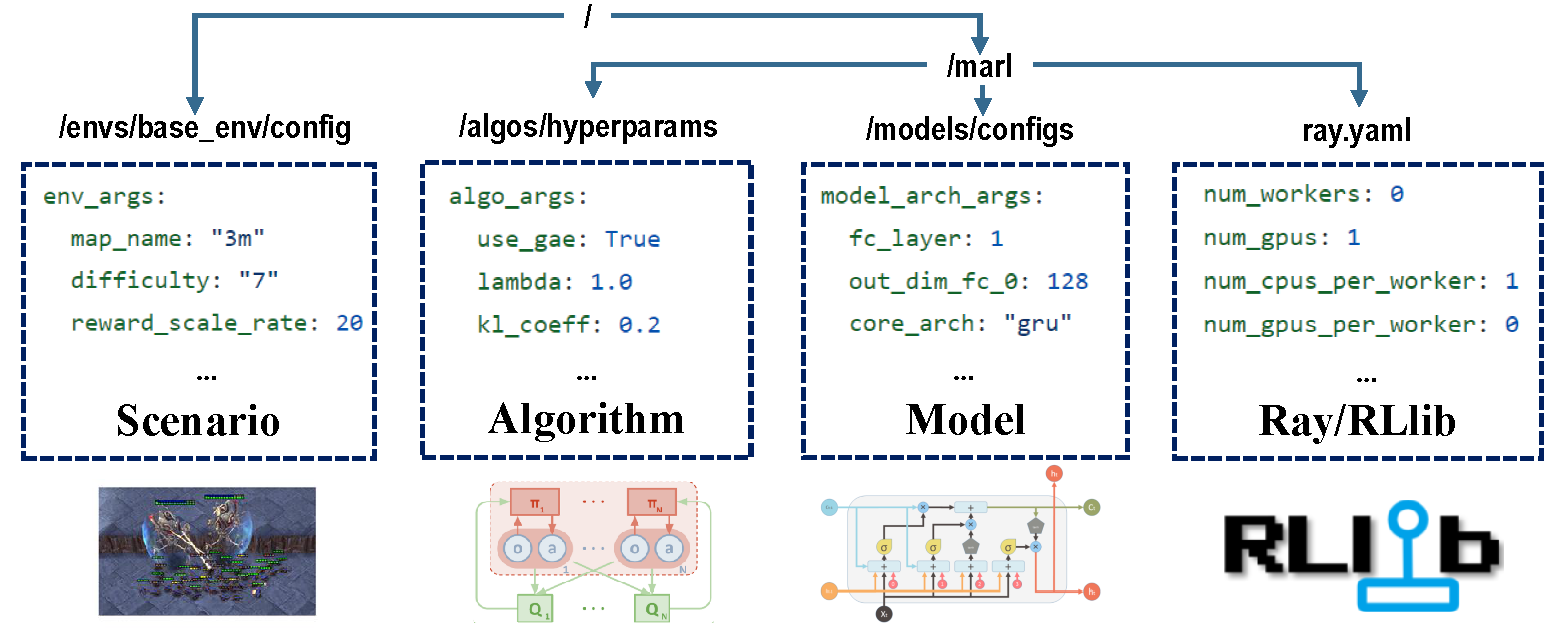
在培训之前,请确保正确设置所有参数,尤其是您不想更改的参数。
注意:您还可以通过Marllib API修改所有预设参数。
确保为您正在运行的环境安装了所有依赖项。否则,请参阅Marllib文档。
| 任务模式 | API示例 |
|---|---|
| 合作 | marl.make_env(environment_name="mpe", map_name="simple_spread", force_coop=True) |
| 协作 | marl.make_env(environment_name="mpe", map_name="simple_spread") |
| 竞争的 | marl.make_env(environment_name="mpe", map_name="simple_adversary") |
| 混合 | marl.make_env(environment_name="mpe", map_name="simple_crypto") |
MARL研究中的大多数流行环境得到了Marllib的支持:
| env名称 | 学习模式 | 可观察性 | 动作空间 | 观察 |
|---|---|---|---|---|
| LBF | 合作 +协作 | 两个都 | 离散的 | 1d |
| Rware | 合作 | 部分的 | 离散的 | 1d |
| MPE | 合作 +协作 +混合 | 两个都 | 两个都 | 1d |
| SISL | 合作 +协作 | 满的 | 两个都 | 1d |
| Smac | 合作 | 部分的 | 离散的 | 1d |
| 元素 | 协作 | 部分的 | 连续的 | 1d |
| 洋红色 | 协作 +混合 | 部分的 | 离散的 | 2d |
| Pommerman | 协作 +竞争性 +混合 | 两个都 | 离散的 | 2d |
| Mamujoco | 合作 | 满的 | 连续的 | 1d |
| grf | 协作 +混合 | 满的 | 离散的 | 2d |
| 哈纳比 | 合作 | 部分的 | 离散的 | 1d |
| 伴侣 | 合作 +混合 | 部分的 | 两个都 | 1d |
| Gobigger | 合作 +混合 | 两个都 | 连续的 | 1d |
| 过度煮熟 | 合作 | 满的 | 离散的 | 1d |
| PDN | 合作 | 部分的 | 连续的 | 1d |
| Aircombat | 合作 +混合 | 部分的 | 多差异 | 1d |
| hideandseek | 竞争性 +混合 | 部分的 | 多差异 | 1d |
每个环境都有一个注册文件,作为此任务的指令,包括ENV设置,安装和重要说明。
| 运行目标 | API示例 |
|---|---|
| 火车和芬太尼 | marl.algos.mappo(hyperparam_source=$ENV) |
| 开发和调试 | marl.algos.mappo(hyperparam_source="test") |
| 第三方 | marl.algos.mappo(hyperparam_source="common") |
这是描述每种算法的特征的图表:
| 算法 | 支持任务模式 | 离散动作 | 连续行动 | 策略类型 |
|---|---|---|---|---|
| IQL * | 全部四个 | ✔️ | 非政策 | |
| pg | 全部四个 | ✔️ | ✔️ | 上政策 |
| A2C | 全部四个 | ✔️ | ✔️ | 上政策 |
| DDPG | 全部四个 | ✔️ | 非政策 | |
| trpo | 全部四个 | ✔️ | ✔️ | 上政策 |
| PPO | 全部四个 | ✔️ | ✔️ | 上政策 |
| 昏迷 | 全部四个 | ✔️ | 上政策 | |
| maddpg | 全部四个 | ✔️ | 非政策 | |
| MAA2C * | 全部四个 | ✔️ | ✔️ | 上政策 |
| Matrpo * | 全部四个 | ✔️ | ✔️ | 上政策 |
| Mappo | 全部四个 | ✔️ | ✔️ | 上政策 |
| Hatrpo | 合作 | ✔️ | ✔️ | 上政策 |
| 霍普 | 合作 | ✔️ | ✔️ | 上政策 |
| VDN | 合作 | ✔️ | 非政策 | |
| QMIX | 合作 | ✔️ | 非政策 | |
| FACMAC | 合作 | ✔️ | 非政策 | |
| vdac | 合作 | ✔️ | ✔️ | 上政策 |
| vdppo * | 合作 | ✔️ | ✔️ | 上政策 |
*所有四个:合作协作竞争的混合
IQL是Q学习的多代理版本。 MAA2C和MATRPO是A2C和TRPO的集中版本。 VDPPO是PPO的值分解版。
代理模型由两个部分组成: encoder和core arch 。 encoder将根据观察空间由Marllib构建。根据您喜欢构建完整的模型,选择mlp , gru或lstm 。
| 模型拱 | API示例 |
|---|---|
| MLP | marl.build_model(env, algo, {"core_arch": "mlp") |
| gru | marl.build_model(env, algo, {"core_arch": "gru"}) |
| LSTM | marl.build_model(env, algo, {"core_arch": "lstm"}) |
| 编码器拱门 | marl.build_model(env, algo, {"core_arch": "gru", "encode_layer": "128-256"}) |
| 环境 | API示例 |
|---|---|
| 火车 | algo.fit(env, model) |
| 调试 | algo.fit(env, model, local_mode=True) |
| 停止条件 | algo.fit(env, model, stop={'episode_reward_mean': 2000, 'timesteps_total': 10000000}) |
| 政策共享 | algo.fit(env, model, share_policy='all') # or 'group' / 'individual' |
| 保存模型 | algo.fit(env, model, checkpoint_freq=100, checkpoint_end=True) |
| GPU加速 | algo.fit(env, model, local_mode=False, num_gpus=1) |
| CPU加速 | algo.fit(env, model, local_mode=False, num_workers=5) |
from marllib import marl
# prepare env
env = marl . make_env ( environment_name = "smac" , map_name = "5m_vs_6m" )
# initialize algorithm with appointed hyper-parameters
mappo = marl . algos . mappo ( hyperparam_source = "smac" )
# build agent model based on env + algorithms + user preference
model = marl . build_model ( env , mappo , { "core_arch" : "gru" , "encode_layer" : "128-256" })
# start training
mappo . fit (
env , model ,
stop = { "timesteps_total" : 1000000 },
checkpoint_freq = 100 ,
share_policy = "group"
)
# rendering
mappo . render (
env , model ,
local_mode = True ,
restore_path = { 'params_path' : "checkpoint/params.json" ,
'model_path' : "checkpoint/checkpoint-10" }
)在当前的工作目录下,您可以找到所有培训数据(日志记录和张量文件)以及保存的模型。为了可视化学习曲线,您可以使用张板。请按照以下步骤操作:
pip install tensorboardtensorboard --logdir .另外,您可以参考本教程以获取更详细的说明。
对于所有现有结果的列表,您可以访问此链接。请注意,这些结果是从较旧版本的Marllib获得的,与当前结果相比,这可能会导致不一致。
Marllib提供了一些实用的例子供您参考。
ray.tune进行政策/模型性能。 在Google Colagoratory上尝试MPE + MAPPO示例!这里提供更多教程文档。
提供了多代理增强学习(MARL)的研究和评论论文。这些论文是根据其发布日期和对相应环境的评估进行组织的。
算法:环境:
| 渠道 | 关联 |
|---|---|
| 问题 | Github问题 |
未来版本的路线图可在Roadmap.md中找到。
我们是一支有关多机构增强学习的小团队,我们将获得我们能获得的所有帮助!如果您想参与其中,以下是有关贡献指南以及如何在本地测试代码的信息。
您可以通过多种方式,例如报告错误,编写或翻译文档,审查或重构代码,请求或实施新功能等。
如果您在研究中使用Marllib,请引用Marllib纸。
@article{hu2022marllib,
author = {Siyi Hu and Yifan Zhong and Minquan Gao and Weixun Wang and Hao Dong and Xiaodan Liang and Zhihui Li and Xiaojun Chang and Yaodong Yang},
title = {MARLlib: A Scalable and Efficient Multi-agent Reinforcement Learning Library},
journal = {Journal of Machine Learning Research},
year = {2023},
}基于或与Marllib <link>紧密合作的作品
@InProceedings{hu2022policy,
title={Policy Diagnosis via Measuring Role Diversity in Cooperative Multi-agent {RL}},
author={Hu, Siyi and Xie, Chuanlong and Liang, Xiaodan and Chang, Xiaojun},
booktitle={Proceedings of the 39th International Conference on Machine Learning},
year={2022},
}
@misc{zhong2023heterogeneousagent,
title={Heterogeneous-Agent Reinforcement Learning},
author={Yifan Zhong and Jakub Grudzien Kuba and Siyi Hu and Jiaming Ji and Yaodong Yang},
archivePrefix={arXiv},
year={2023},
}

