MARLlib
v1.0.3
| ❗ニュース |
|---|
| 2023年3月は、主要なアップデートがリリースされたばかりであることを発表することに興奮しています。詳細なバージョン情報については、バージョン情報を参照してください。 |
| 2023年5月エキサイティングなニュース! Marllibは、Mate、Gobigger、Overcooked-Ai、Mapdn、およびAircombatの5つのタスクをサポートしています。試してみてください! |
| 2023年6月Openai:Hide and Seek and SISL環境はMarllibに組み込まれています。 |
| 2023年8月?MarllibはJMLRに掲載されたことを受け入れました。 |
| 2023年9月、 Gymnasiumを備えた最新のPettingzooは、Marllib内で互換性があります。 |
| 2023年11月私たちは現在、実践的なMarl Bookを作成しており、2023年末までにドラフトをリリースすることを目指しています。 |
Multi-Agent Renection Learning Library(Marllib)は、 RayとそのツールキットRllibの1つを利用するMarlライブラリです。さまざまなタスクや環境でMARLアルゴリズムを開発、トレーニング、テストするための包括的なプラットフォームを提供します。
Marllibを使用する方法の例は次のとおりです。
from marllib import marl
# prepare env
env = marl . make_env ( environment_name = "mpe" , map_name = "simple_spread" , force_coop = True )
# initialize algorithm with appointed hyper-parameters
mappo = marl . algos . mappo ( hyperparam_source = 'mpe' )
# build agent model based on env + algorithms + user preference
model = marl . build_model ( env , mappo , { "core_arch" : "mlp" , "encode_layer" : "128-256" })
# start training
mappo . fit ( env , model , stop = { 'timesteps_total' : 1000000 }, share_policy = 'group' )ここでは、Marllibと既存の作業を比較するためのテーブルを提供します。
| 図書館 | サポートされているenv | アルゴリズム | パラメーター共有 | モデル |
|---|---|---|---|---|
| Pymarl | 1協同組合 | 5 | 共有 | Gru |
| pymarl2 | 2協同組合 | 11 | 共有 | MLP + GRU |
| MAPPOベンチマーク | 4協同組合 | 1 | 共有 +個別 | MLP + GRU |
| マリブ | 4自己プレイ | 10 | 共有 +グループ +個別 | MLP + LSTM |
| epymarl | 4協同組合 | 9 | 共有 +個別 | Gru |
| ハール | 8協同組合 | 9 | 共有 +個別 | MLP + CNN + GRU |
| マルリブ | 17タスクモードの制限なし | 18 | 共有 +グループ +個別 +カスタマイズ可能 | MLP + CNN + GRU + LSTM |
| 図書館 | Github Stars | ドキュメント | 問題が発生します | 活動 | 最後の更新 |
|---|---|---|---|---|---|
| Pymarl | |||||
| pymarl2 | |||||
| MAPPOベンチマーク | |||||
| マリブ | |||||
| epymarl | |||||
| harl * | |||||
| マルリブ |
* Harlは最近リリースされた最新のMarl Libraryです。最先端のパフォーマンスを備えた最先端のMarlアルゴリズムがターゲットである場合、Harlは間違いなく見る価値があります!
? Marllibは、際立っているいくつかの重要な機能を提供しています。
Marllibを使用して、次のようなさまざまな利点を利用できます。
注:現時点では、MarllibはLinuxオペレーティングシステムとのみ互換性があることに注意してください。
まず、Marllib依存関係をインストールして、基本的な使用法を保証します。このガイドに従って、最後にRLLIBのパッチをインストールします。
$ conda create -n marllib python=3.8 # or 3.9
$ conda activate marllib
$ git clone https://github.com/Replicable-MARL/MARLlib.git && cd MARLlib
$ pip install -r requirements.txtこのガイドに従ってください。
注:0.20.0前後のジムバージョンをお勧めします。
pip install " gym==0.20.0 " 次のコマンドを実行して、パッチを使用してrllibのバグを修正します。
$ cd /Path/To/MARLlib/marllib/patch
$ python add_patch.py -y$ pip install --upgrade pip
$ pip install marllibMARLlib/docker/DockerfileにMarllib docker画像を構築するためのDockerfileと、 MARLlib/.devcontainerフォルダーにdevcontainerセットアップを提供します。 DevContainerを使用する場合、注意すべきことの1つは、ハードウェアに従ってdevcontainer.jsonのrunArgsで特定--shm-size引数をカスタマイズする必要があるかもしれないということです。
トレーニングプロセス全体を担当する構成には4つの部分があります。
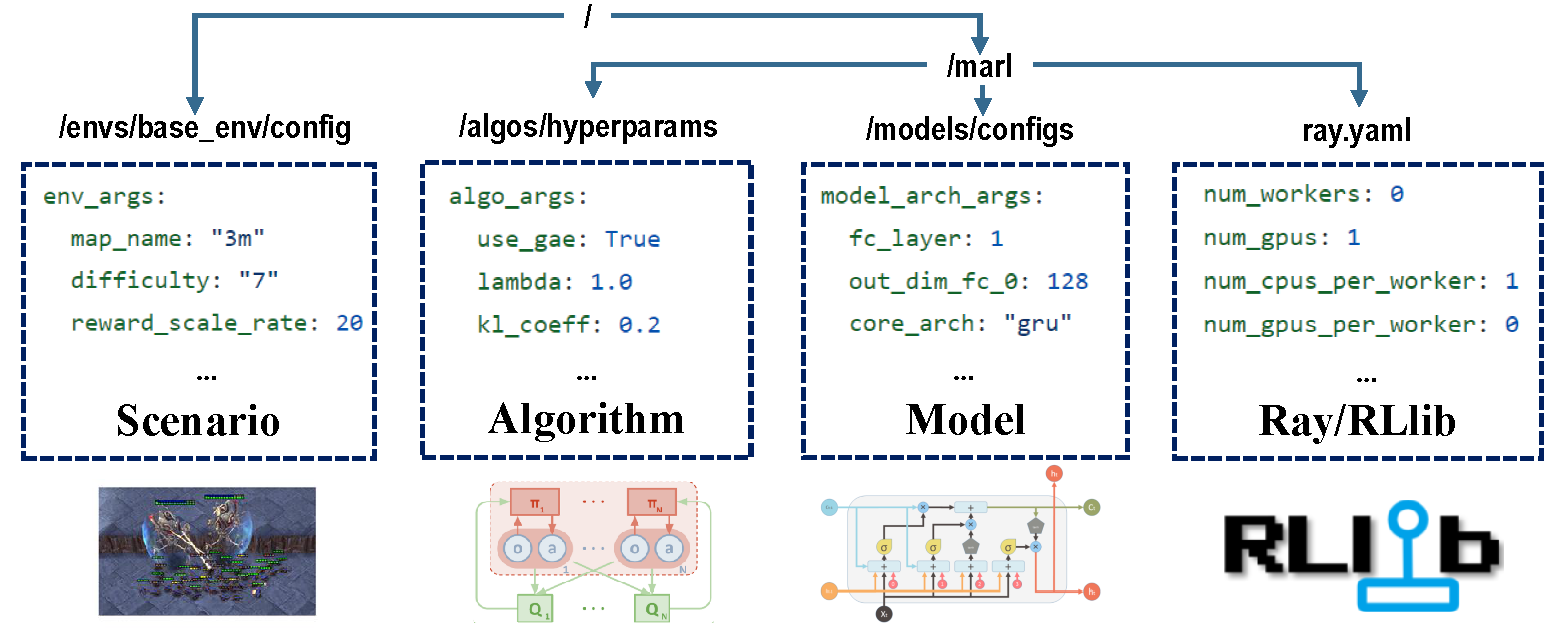
トレーニング前に、すべてのパラメーターが正しく設定されていることを確認します。特に変更したくないパラメーター。
注:Marllib APIを介してすべての事前セットパラメーターを変更することもできます。
実行中の環境にすべての依存関係がインストールされていることを確認してください。それ以外の場合は、Marllibのドキュメントを参照してください。
| タスクモード | APIの例 |
|---|---|
| 協同組合 | marl.make_env(environment_name="mpe", map_name="simple_spread", force_coop=True) |
| 共同 | marl.make_env(environment_name="mpe", map_name="simple_spread") |
| 競争力 | marl.make_env(environment_name="mpe", map_name="simple_adversary") |
| 混合 | marl.make_env(environment_name="mpe", map_name="simple_crypto") |
Marl Researchで人気のある環境のほとんどは、Marllibによってサポートされています。
| env名 | 学習モード | 観察可能性 | アクションスペース | 観察 |
|---|---|---|---|---|
| LBF | 協同組合 +共同 | 両方 | 離散 | 1d |
| rware | 協同組合 | 部分的 | 離散 | 1d |
| MPE | 協同組合 +共同 +混合 | 両方 | 両方 | 1d |
| SISL | 協同組合 +共同 | 満杯 | 両方 | 1d |
| SMAC | 協同組合 | 部分的 | 離散 | 1d |
| メタドライブ | 共同 | 部分的 | 連続 | 1d |
| 魔法 | 共同 +混合 | 部分的 | 離散 | 2d |
| ポンマルマン | 共同 +競争力 +ミックス | 両方 | 離散 | 2d |
| マムホコ | 協同組合 | 満杯 | 連続 | 1d |
| GRF | 共同 +混合 | 満杯 | 離散 | 2d |
| ハナビ | 協同組合 | 部分的 | 離散 | 1d |
| メイト | 協同組合 +混合 | 部分的 | 両方 | 1d |
| ゴビガー | 協同組合 +混合 | 両方 | 連続 | 1d |
| 過剰調理済み | 協同組合 | 満杯 | 離散 | 1d |
| pdn | 協同組合 | 部分的 | 連続 | 1d |
| aircombat | 協同組合 +混合 | 部分的 | 多分割 | 1d |
| かくれんぼ | 競争力 +ミックス | 部分的 | 多分割 | 1d |
各環境には、ENVの設定、インストール、重要なメモなど、このタスクの指示として立っているREADMEファイルがあります。
| 実行ターゲット | APIの例 |
|---|---|
| 列車&Finetune | marl.algos.mappo(hyperparam_source=$ENV) |
| 開発とデバッグ | marl.algos.mappo(hyperparam_source="test") |
| サードパーティenv | marl.algos.mappo(hyperparam_source="common") |
各アルゴリズムの特性を説明するチャートが次のとおりです。
| アルゴリズム | サポートタスクモード | 離散アクション | 継続的なアクション | ポリシータイプ |
|---|---|---|---|---|
| IQL * | 4つすべて | ✔✔️ | オフポリシー | |
| pg | 4つすべて | ✔✔️ | ✔✔️ | オンポリシー |
| A2c | 4つすべて | ✔✔️ | ✔✔️ | オンポリシー |
| DDPG | 4つすべて | ✔✔️ | オフポリシー | |
| TRPO | 4つすべて | ✔✔️ | ✔✔️ | オンポリシー |
| PPO | 4つすべて | ✔✔️ | ✔✔️ | オンポリシー |
| コマ | 4つすべて | ✔✔️ | オンポリシー | |
| maddpg | 4つすべて | ✔✔️ | オフポリシー | |
| maa2c * | 4つすべて | ✔✔️ | ✔✔️ | オンポリシー |
| matrpo * | 4つすべて | ✔✔️ | ✔✔️ | オンポリシー |
| MAPPO | 4つすべて | ✔✔️ | ✔✔️ | オンポリシー |
| hatrpo | 協同組合 | ✔✔️ | ✔✔️ | オンポリシー |
| happo | 協同組合 | ✔✔️ | ✔✔️ | オンポリシー |
| vdn | 協同組合 | ✔✔️ | オフポリシー | |
| Qmix | 協同組合 | ✔✔️ | オフポリシー | |
| FACMAC | 協同組合 | ✔✔️ | オフポリシー | |
| VDAC | 協同組合 | ✔✔️ | ✔✔️ | オンポリシー |
| vdppo * | 協同組合 | ✔✔️ | ✔✔️ | オンポリシー |
* 4つすべて:協力的な共同競争的混合
IQLはQ Learningのマルチエージェントバージョンです。 MAA2CとMATRPOは、A2CとTRPOの集中バージョンです。 VDPPOは、PPOの値分解バージョンです。
エージェントモデルは、 encoderとcore arch 2つの部分で構成されています。 encoder観測スペースに従ってMarllibによって構築されます。完全なモデルを構築するのが好きなので、 mlp 、 gru 、またはlstmを選択してください。
| モデルアーチ | APIの例 |
|---|---|
| MLP | marl.build_model(env, algo, {"core_arch": "mlp") |
| Gru | marl.build_model(env, algo, {"core_arch": "gru"}) |
| LSTM | marl.build_model(env, algo, {"core_arch": "lstm"}) |
| エンコーダーアーチ | marl.build_model(env, algo, {"core_arch": "gru", "encode_layer": "128-256"}) |
| 設定 | APIの例 |
|---|---|
| 電車 | algo.fit(env, model) |
| デバッグ | algo.fit(env, model, local_mode=True) |
| 停止状態 | algo.fit(env, model, stop={'episode_reward_mean': 2000, 'timesteps_total': 10000000}) |
| ポリシー共有 | algo.fit(env, model, share_policy='all') # or 'group' / 'individual' |
| モデルを保存します | algo.fit(env, model, checkpoint_freq=100, checkpoint_end=True) |
| GPU加速 | algo.fit(env, model, local_mode=False, num_gpus=1) |
| CPU加速 | algo.fit(env, model, local_mode=False, num_workers=5) |
from marllib import marl
# prepare env
env = marl . make_env ( environment_name = "smac" , map_name = "5m_vs_6m" )
# initialize algorithm with appointed hyper-parameters
mappo = marl . algos . mappo ( hyperparam_source = "smac" )
# build agent model based on env + algorithms + user preference
model = marl . build_model ( env , mappo , { "core_arch" : "gru" , "encode_layer" : "128-256" })
# start training
mappo . fit (
env , model ,
stop = { "timesteps_total" : 1000000 },
checkpoint_freq = 100 ,
share_policy = "group"
)
# rendering
mappo . render (
env , model ,
local_mode = True ,
restore_path = { 'params_path' : "checkpoint/params.json" ,
'model_path' : "checkpoint/checkpoint-10" }
)現在の作業ディレクトリの下では、すべてのトレーニングデータ(ロギングおよびTensorFlowファイル)と保存されたモデルを見つけることができます。学習曲線を視覚化するには、テンソルボードを使用できます。以下の手順に従ってください。
pip install tensorboardtensorboard --logdir .または、より詳細な手順については、このチュートリアルを参照してください。
既存のすべての結果のリストについては、このリンクにアクセスできます。これらの結果は、現在の結果と比較した場合、矛盾につながる可能性があるMarllibの古いバージョンから得られたことに注意してください。
Marllibは、あなたが参照するためのいくつかの実用的な例を提供します。
ray.tuneでのポリシー/モデルのパフォーマンス。 Google ColaboratoryでMPE + MAPPOの例をお試しください!その他のチュートリアルドキュメントはこちらからご覧いただけます。
マルチエージェント補強学習(MARL)の研究とレビュー論文のコレクションが利用可能です。論文は、出版日と対応する環境の評価に基づいて組織されています。
アルゴリズム:環境:
| チャネル | リンク |
|---|---|
| 問題 | githubの問題 |
将来のリリースへのロードマップは、roadmap.mdで入手できます。
私たちはマルチエージェントの補強学習の小さなチームであり、私たちが得ることができるすべての助けを借ります!参加したい場合は、貢献ガイドラインとコードをローカルでテストする方法に関する情報を以下に示します。
バグの報告、ドキュメントの書き込みまたは翻訳、コードのレビューまたはリファクタリング、新しい機能の要求または実装など、複数の方法で貢献できます。
研究でMarllibを使用している場合は、Marllibの論文を引用してください。
@article{hu2022marllib,
author = {Siyi Hu and Yifan Zhong and Minquan Gao and Weixun Wang and Hao Dong and Xiaodan Liang and Zhihui Li and Xiaojun Chang and Yaodong Yang},
title = {MARLlib: A Scalable and Efficient Multi-agent Reinforcement Learning Library},
journal = {Journal of Machine Learning Research},
year = {2023},
}Marllib <link>に基づいている、または密接に協力している作品
@InProceedings{hu2022policy,
title={Policy Diagnosis via Measuring Role Diversity in Cooperative Multi-agent {RL}},
author={Hu, Siyi and Xie, Chuanlong and Liang, Xiaodan and Chang, Xiaojun},
booktitle={Proceedings of the 39th International Conference on Machine Learning},
year={2022},
}
@misc{zhong2023heterogeneousagent,
title={Heterogeneous-Agent Reinforcement Learning},
author={Yifan Zhong and Jakub Grudzien Kuba and Siyi Hu and Jiaming Ji and Yaodong Yang},
archivePrefix={arXiv},
year={2023},
}

