MARLlib
v1.0.3
| الأخبار |
|---|
| مارس 2023 ⚓ متحمسون للإعلان عن إصدار تحديث كبير للتو. للحصول على معلومات إصدار مفصلة ، يرجى الرجوع إلى معلومات الإصدار. |
| مايو 2023 أخبار مثيرة! يدعم Marllib الآن خمس مهام أخرى: Mate و Gobigger و Overcooked-AA و MAPDN و Aircombat. جربهم! |
| يونيو 2023 Openai: يتم دمج بيئات إخفاء و SISL في Marllib. |
| أغسطس 2023 ؟ تم قبول مارليب للنشر في JMLR. |
| سبتمبر 2023 أحدث pettingzoo مع صالة الألعاب الرياضية قابلة للتوافق داخل مارليب. |
| نوفمبر 2023 ، نحن بصدد إنشاء كتاب MARL عمليًا ونهدف إلى إصدار المسودة بحلول نهاية عام 2023. |
مكتبة التعلم التعزيز متعددة الوكلاء (Marllib) هي مكتبة MARL التي تستخدم Ray وأحد مجموعات الأدوات RLLIB . إنه يوفر منصة شاملة لتطوير وتدريب واختبار خوارزميات MARL عبر مختلف المهام والبيئات.
إليك مثال على كيفية استخدام Marllib:
from marllib import marl
# prepare env
env = marl . make_env ( environment_name = "mpe" , map_name = "simple_spread" , force_coop = True )
# initialize algorithm with appointed hyper-parameters
mappo = marl . algos . mappo ( hyperparam_source = 'mpe' )
# build agent model based on env + algorithms + user preference
model = marl . build_model ( env , mappo , { "core_arch" : "mlp" , "encode_layer" : "128-256" })
# start training
mappo . fit ( env , model , stop = { 'timesteps_total' : 1000000 }, share_policy = 'group' )نحن هنا نقدم جدولًا لمقارنة Marllib والعمل الحالي.
| مكتبة | المدعومة ENV | خوارزمية | مشاركة المعلمة | نموذج |
|---|---|---|---|---|
| pymarl | 1 التعاونية | 5 | يشارك | جرو |
| pymarl2 | 2 التعاونية | 11 | يشارك | MLP + GRU |
| مؤشر مابو | 4 التعاونية | 1 | مشاركة + منفصلة | MLP + GRU |
| ماليب | 4 اللعب الذاتي | 10 | مشاركة + مجموعة + منفصلة | MLP + LSTM |
| epymarl | 4 التعاونية | 9 | مشاركة + منفصلة | جرو |
| هارل | 8 التعاونية | 9 | مشاركة + منفصلة | MLP + CNN + GRU |
| مارليب | 17 لا يوجد قيود على وضع المهمة | 18 | مشاركة + مجموعة + منفصلة + قابلة للتخصيص | MLP + CNN + GRU + LSTM |
| مكتبة | نجوم جيثب | الوثائق | القضايا مفتوحة | نشاط | التحديث الأخير |
|---|---|---|---|---|---|
| pymarl | |||||
| pymarl2 | |||||
| مؤشر مابو | |||||
| ماليب | |||||
| epymarl | |||||
| هارل * | |||||
| مارليب |
* هارل هي أحدث مكتبة مارل التي تم إصدارها مؤخرًا: Fire:. إذا كانت خوارزميات Marl المتطورة ذات الأداء المتطرف هي هدفك ، فإن Harl يستحق بالتأكيد نظرة!
؟ يقدم Marllib العديد من الميزات الرئيسية التي تجعلها تبرز:
باستخدام Marllib ، يمكنك الاستفادة من الفوائد المختلفة ، مثل:
ملاحظة : يرجى ملاحظة أنه في هذا الوقت ، يكون Marllib متوافقًا فقط مع أنظمة تشغيل Linux.
أولاً ، قم بتثبيت تبعيات Marllib لضمان الاستخدام الأساسي. بعد هذا الدليل ، أخيرًا قم بتثبيت تصحيحات لـ RLLIB.
$ conda create -n marllib python=3.8 # or 3.9
$ conda activate marllib
$ git clone https://github.com/Replicable-MARL/MARLlib.git && cd MARLlib
$ pip install -r requirements.txtيرجى اتباع هذا الدليل.
ملاحظة : نوصي إصدار الصالة الرياضية بحوالي 0.20.0.
pip install " gym==0.20.0 " إصلاح الأخطاء من RLLIB باستخدام تصحيحات عن طريق تشغيل الأمر التالي:
$ cd /Path/To/MARLlib/marllib/patch
$ python add_patch.py -y$ pip install --upgrade pip
$ pip install marllib نحن نقدم Dockerfile لبناء صورة Marllib Docker في MARLlib/docker/Dockerfile وإعداد DevContainer في مجلد MARLlib/.devcontainer . إذا كنت تستخدم DevContainer ، فإن هناك شيء واحد يجب ملاحظته هو أنك قد تحتاج إلى تخصيص وسيطات معينة في runArgs of devcontainer.json وفقًا لأجهزةك ، على سبيل المثال --shm-size .
هناك أربعة أجزاء من التكوينات التي تتولى مسؤولية عملية التدريب بأكملها.
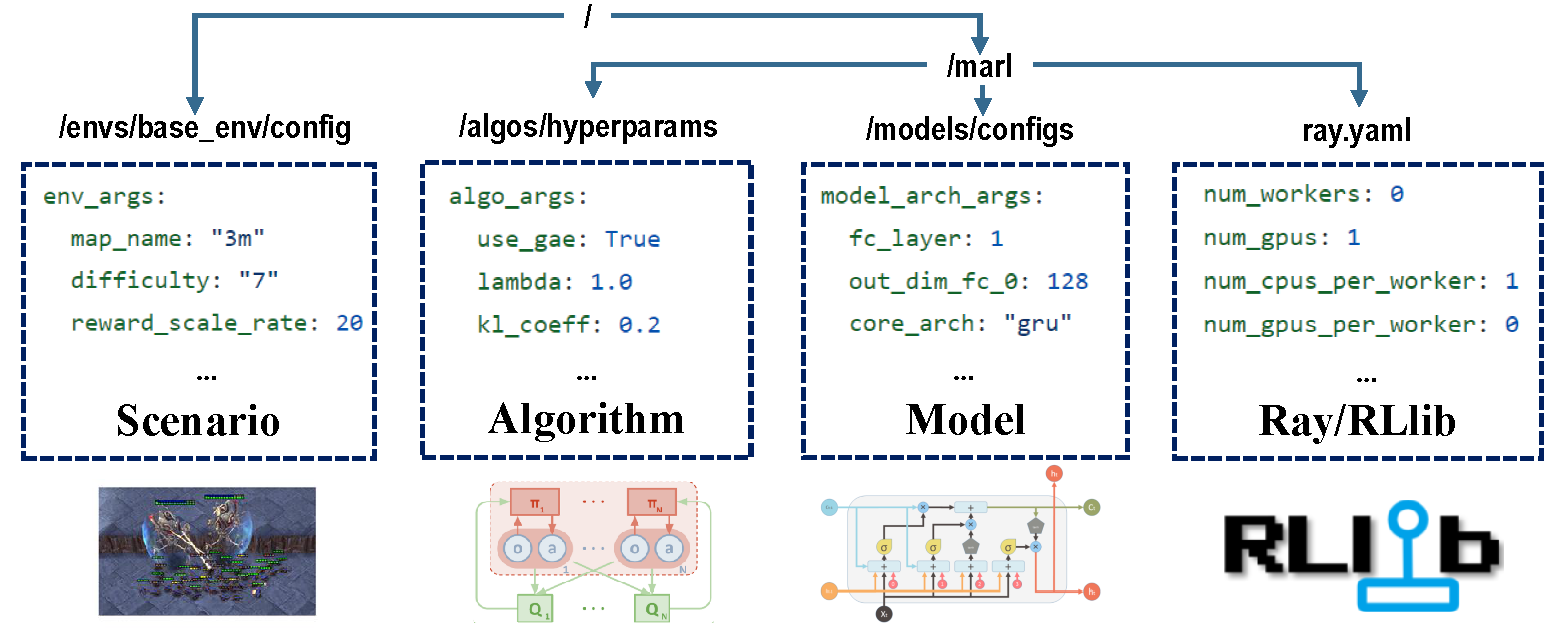
قبل التدريب ، تأكد من تعيين جميع المعلمات بشكل صحيح ، خاصة تلك التي لا تريد تغييرها.
ملاحظة : يمكنك أيضًا تعديل جميع المعلمات المسبقة عبر Marllib API.*
تأكد من تثبيت جميع التبعيات للبيئة التي تعمل بها. خلاف ذلك ، يرجى الرجوع إلى وثائق Marllib.
| وضع المهمة | مثال API |
|---|---|
| التعاونية | marl.make_env(environment_name="mpe", map_name="simple_spread", force_coop=True) |
| التعاون | marl.make_env(environment_name="mpe", map_name="simple_spread") |
| تنافسي | marl.make_env(environment_name="mpe", map_name="simple_adversary") |
| مختلط | marl.make_env(environment_name="mpe", map_name="simple_crypto") |
يتم دعم معظم البيئات الشائعة في MARL Research بواسطة Marllib:
| اسم البيئة | وضع التعلم | قابلية الملاحظة | مساحة العمل | الملاحظات |
|---|---|---|---|---|
| LBF | تعاونية + تعاونية | كلاهما | منفصلة | 1D |
| rware | التعاونية | جزئي | منفصلة | 1D |
| MPE | تعاونية + تعاونية + مختلطة | كلاهما | كلاهما | 1D |
| سيسل | تعاونية + تعاونية | ممتلىء | كلاهما | 1D |
| سماك | التعاونية | جزئي | منفصلة | 1D |
| مفصل | التعاون | جزئي | مستمر | 1D |
| أرجواني | تعاونية + مختلطة | جزئي | منفصلة | 2D |
| Pommerman | تعاون + تنافسي + مختلط | كلاهما | منفصلة | 2D |
| ماموجوكو | التعاونية | ممتلىء | مستمر | 1D |
| GRF | تعاونية + مختلطة | ممتلىء | منفصلة | 2D |
| حنابي | التعاونية | جزئي | منفصلة | 1D |
| رَفِيق | تعاونية + مختلطة | جزئي | كلاهما | 1D |
| gobigger | تعاونية + مختلطة | كلاهما | مستمر | 1D |
| overcooked-ai | التعاونية | ممتلىء | منفصلة | 1D |
| PDN | التعاونية | جزئي | مستمر | 1D |
| aircombat | تعاونية + مختلطة | جزئي | multidiscrete | 1D |
| الغميضة | تنافسية + مختلطة | جزئي | multidiscrete | 1D |
تحتوي كل بيئة على ملف readme ، يقف كتعليم لهذه المهمة ، بما في ذلك إعدادات ENV والتثبيت والملاحظات المهمة.
| تشغيل الهدف | مثال API |
|---|---|
| قطار و finetune | marl.algos.mappo(hyperparam_source=$ENV) |
| تطوير وتصحيح | marl.algos.mappo(hyperparam_source="test") |
| الحزب الثالث ENV | marl.algos.mappo(hyperparam_source="common") |
فيما يلي مخطط يصف خصائص كل خوارزمية:
| خوارزمية | دعم مهمة المهمة | عمل منفصل | عمل مستمر | نوع السياسة |
|---|---|---|---|---|
| IQL * | الأربعة | ✔ | خارج السياسة | |
| ص | الأربعة | ✔ | ✔ | على السياسة |
| A2C | الأربعة | ✔ | ✔ | على السياسة |
| DDPG | الأربعة | ✔ | خارج السياسة | |
| trpo | الأربعة | ✔ | ✔ | على السياسة |
| PPO | الأربعة | ✔ | ✔ | على السياسة |
| غيبوبة | الأربعة | ✔ | على السياسة | |
| MADDPG | الأربعة | ✔ | خارج السياسة | |
| MAA2C * | الأربعة | ✔ | ✔ | على السياسة |
| matrpo * | الأربعة | ✔ | ✔ | على السياسة |
| مابو | الأربعة | ✔ | ✔ | على السياسة |
| هاتربو | التعاونية | ✔ | ✔ | على السياسة |
| هابو | التعاونية | ✔ | ✔ | على السياسة |
| vdn | التعاونية | ✔ | خارج السياسة | |
| Qmix | التعاونية | ✔ | خارج السياسة | |
| Facmac | التعاونية | ✔ | خارج السياسة | |
| VDAC | التعاونية | ✔ | ✔ | على السياسة |
| VDPPO * | التعاونية | ✔ | ✔ | على السياسة |
* الأربعة : مختلط تعاوني تنافسي مختلط
IQL هي النسخة متعددة الوكلاء من Q Learning. MAA2C و MATRPO هي النسخة المركزية من A2C و TRPO. VDPPO هو نسخة تحلل القيمة من PPO.
يتكون نموذج الوكيل من جزأين ، encoder والقوس core arch . سيتم بناء encoder بواسطة Marllib وفقًا لمساحة المراقبة. اختر mlp أو gru أو lstm كما ترغب في إنشاء النموذج الكامل.
| نموذج القوس | مثال API |
|---|---|
| MLP | marl.build_model(env, algo, {"core_arch": "mlp") |
| جرو | marl.build_model(env, algo, {"core_arch": "gru"}) |
| LSTM | marl.build_model(env, algo, {"core_arch": "lstm"}) |
| تشفير القوس | marl.build_model(env, algo, {"core_arch": "gru", "encode_layer": "128-256"}) |
| جلسة | مثال API |
|---|---|
| يدرب | algo.fit(env, model) |
| تصحيح | algo.fit(env, model, local_mode=True) |
| توقف | algo.fit(env, model, stop={'episode_reward_mean': 2000, 'timesteps_total': 10000000}) |
| تبادل السياسة | algo.fit(env, model, share_policy='all') # or 'group' / 'individual' |
| حفظ النموذج | algo.fit(env, model, checkpoint_freq=100, checkpoint_end=True) |
| GPU تسارع | algo.fit(env, model, local_mode=False, num_gpus=1) |
| وحدة المعالجة المركزية تسريع | algo.fit(env, model, local_mode=False, num_workers=5) |
from marllib import marl
# prepare env
env = marl . make_env ( environment_name = "smac" , map_name = "5m_vs_6m" )
# initialize algorithm with appointed hyper-parameters
mappo = marl . algos . mappo ( hyperparam_source = "smac" )
# build agent model based on env + algorithms + user preference
model = marl . build_model ( env , mappo , { "core_arch" : "gru" , "encode_layer" : "128-256" })
# start training
mappo . fit (
env , model ,
stop = { "timesteps_total" : 1000000 },
checkpoint_freq = 100 ,
share_policy = "group"
)
# rendering
mappo . render (
env , model ,
local_mode = True ,
restore_path = { 'params_path' : "checkpoint/params.json" ,
'model_path' : "checkpoint/checkpoint-10" }
)ضمن دليل العمل الحالي ، يمكنك العثور على جميع بيانات التدريب (ملفات التسجيل وملفات TensorFlow) بالإضافة إلى النماذج المحفوظة. لتصور منحنى التعلم ، يمكنك استخدام Tensorboard. اتبع الخطوات أدناه:
pip install tensorboardtensorboard --logdir .بدلاً من ذلك ، يمكنك الرجوع إلى هذا البرنامج التعليمي للحصول على المزيد من التعليمات التفصيلية.
للحصول على قائمة بجميع النتائج الحالية ، يمكنك زيارة هذا الرابط. يرجى ملاحظة أنه تم الحصول على هذه النتائج من نسخة أقدم من Marllib ، والتي قد تؤدي إلى تناقضات عند مقارنتها بالنتائج الحالية.
يوفر Marllib بعض الأمثلة العملية لتشير إليها.
ray.tune . جرب أمثلة MPE + MAPPO على google colaboratory! المزيد من الوثائق التعليمية متوفرة هنا.
تتوفر مجموعة من أوراق الأبحاث والمراجعة للتعلم التعزيز متعدد الوكلاء (MARL). تم تنظيم الأوراق بناءً على تاريخ نشرها وتقييمها للبيئات المقابلة.
الخوارزميات: البيئات:
| قناة | وصلة |
|---|---|
| مشاكل | قضايا جيثب |
تتوفر خارطة الطريق إلى الإصدار المستقبلي في Roadmap.md.
نحن فريق صغير في تعلم التعزيز متعدد الوكلاء ، وسوف نأخذ كل المساعدة التي يمكننا الحصول عليها! إذا كنت ترغب في المشاركة ، فإليك معلومات حول إرشادات المساهمة وكيفية اختبار الكود محليًا.
يمكنك المساهمة بطرق متعددة ، على سبيل المثال ، الإبلاغ عن الأخطاء أو كتابة أو ترجمة الوثائق أو مراجعة أو إعادة تمثيل التعليمات البرمجية أو طلب ميزات جديدة أو تنفيذها ، إلخ.
إذا كنت تستخدم Marllib في بحثك ، فيرجى الاستشهاد بورق Marllib.
@article{hu2022marllib,
author = {Siyi Hu and Yifan Zhong and Minquan Gao and Weixun Wang and Hao Dong and Xiaodan Liang and Zhihui Li and Xiaojun Chang and Yaodong Yang},
title = {MARLlib: A Scalable and Efficient Multi-agent Reinforcement Learning Library},
journal = {Journal of Machine Learning Research},
year = {2023},
}الأعمال التي تستند إلى أو تتعاون بشكل وثيق مع Marllib <link>
@InProceedings{hu2022policy,
title={Policy Diagnosis via Measuring Role Diversity in Cooperative Multi-agent {RL}},
author={Hu, Siyi and Xie, Chuanlong and Liang, Xiaodan and Chang, Xiaojun},
booktitle={Proceedings of the 39th International Conference on Machine Learning},
year={2022},
}
@misc{zhong2023heterogeneousagent,
title={Heterogeneous-Agent Reinforcement Learning},
author={Yifan Zhong and Jakub Grudzien Kuba and Siyi Hu and Jiaming Ji and Yaodong Yang},
archivePrefix={arXiv},
year={2023},
}

