MARLlib
v1.0.3
| ❗ 뉴스 |
|---|
| 2023 년 3 월 ∎ 주요 업데이트가 방금 출시되었다고 발표하게되어 기쁩니다. 자세한 버전 정보는 버전 정보를 참조하십시오. |
| 2023 년 5 월 흥미로운 소식! Marllib은 이제 Mate, Gobigger, Overchooked-Ai, MAPDN 및 AirCombat의 5 가지 작업을 더 지원합니다. 그들에게 시도해보세요! |
| 2023 년 6 월 Openai : 숨기기 및 찾기 및 SISL 환경이 Marllib에 통합됩니다. |
| 2023 년 8 월 ? Marllib은 JMLR에 출판되었다. |
| 2023 년 9 월 체육관이있는 최신 Pettingzoo는 Marllib 내에서 호환됩니다. |
| 2023 년 11 월 우리는 현재 실습 Marl 책을 만들고 있으며 2023 년 말까지 초안을 발표하는 것을 목표로하고 있습니다. |
MARLLIB (Multi-Agent Infercement Learning Library)는 Ray 와 툴킷 Rllib 중 하나를 사용하는 Marl 라이브러리 입니다. 다양한 작업 및 환경에서 Marl 알고리즘을 개발, 교육 및 테스트하기위한 포괄적 인 플랫폼을 제공합니다.
다음은 Marllib을 사용하는 방법의 예입니다.
from marllib import marl
# prepare env
env = marl . make_env ( environment_name = "mpe" , map_name = "simple_spread" , force_coop = True )
# initialize algorithm with appointed hyper-parameters
mappo = marl . algos . mappo ( hyperparam_source = 'mpe' )
# build agent model based on env + algorithms + user preference
model = marl . build_model ( env , mappo , { "core_arch" : "mlp" , "encode_layer" : "128-256" })
# start training
mappo . fit ( env , model , stop = { 'timesteps_total' : 1000000 }, share_policy = 'group' )여기서 우리는 marllib과 기존 작업을 비교하기위한 테이블을 제공합니다.
| 도서관 | 지원 대상 | 연산 | 매개 변수 공유 | 모델 |
|---|---|---|---|---|
| Pymarl | 1 협동 조합 | 5 | 공유하다 | 그루 |
| pymarl2 | 2 협동 조합 | 11 | 공유하다 | MLP + GRU |
| Mappo 벤치 마크 | 4 협동 조합 | 1 | 공유 + 별도 | MLP + GRU |
| 말리브 | 4 자체 플레이 | 10 | 공유 + 그룹 + 별도 | MLP + LSTM |
| Epymarl | 4 협동 조합 | 9 | 공유 + 별도 | 그루 |
| 할 | 8 협동 조합 | 9 | 공유 + 별도 | MLP + CNN + GRU |
| marllib | 17 작업 모드 제한이 없습니다 | 18 | 공유 + 그룹 + 별도 + 사용자 정의 가능 | MLP + CNN + GRU + LSTM |
| 도서관 | Github 스타 | 선적 서류 비치 | 문제가 열려 있습니다 | 활동 | 마지막 업데이트 |
|---|---|---|---|---|---|
| Pymarl | |||||
| pymarl2 | |||||
| Mappo 벤치 마크 | |||||
| 말리브 | |||||
| Epymarl | |||||
| 할 * | |||||
| marllib |
* Harl은 최근 발표 된 최신 Marl 라이브러리입니다. Fire :. 최첨단 성능을 가진 최첨단 말 알고리즘이 목표라면 Harl은 확실히 가치가 있습니다!
? Marllib은 눈에 띄는 몇 가지 주요 기능을 제공합니다.
Marllib을 사용하면 다음과 같은 다양한 이점을 활용할 수 있습니다.
참고 : 현재 Marllib은 Linux 운영 체제 와만 호환됩니다.
먼저, 기본 사용을 보장하기 위해 marllib 종속성을 설치하십시오. 이 안내서를 따라 마침내 rllib 용 패치를 설치하십시오.
$ conda create -n marllib python=3.8 # or 3.9
$ conda activate marllib
$ git clone https://github.com/Replicable-MARL/MARLlib.git && cd MARLlib
$ pip install -r requirements.txt이 안내서를 따르십시오.
참고 : 체육관 버전은 약 0.20.0을 권장합니다.
pip install " gym==0.20.0 " 다음 명령을 실행하여 패치를 사용하여 rllib의 버그를 수정하십시오.
$ cd /Path/To/MARLlib/marllib/patch
$ python add_patch.py -y$ pip install --upgrade pip
$ pip install marllib MARLlib/docker/Dockerfile 에서 Marllib Docker 이미지를 구축하기위한 Dockerfile과 MARLlib/.devcontainer 폴더에서 DevContainer 설정을 제공합니다. DevContainer를 사용하는 경우, 주목해야 할 한 가지는 하드웨어에 따라 devcontainer.json 의 runArgs 에서 특정 인수를 --shm-size 정의해야 할 수도 있다는 것입니다.
전체 교육 과정을 담당하는 구성의 네 부분이 있습니다.
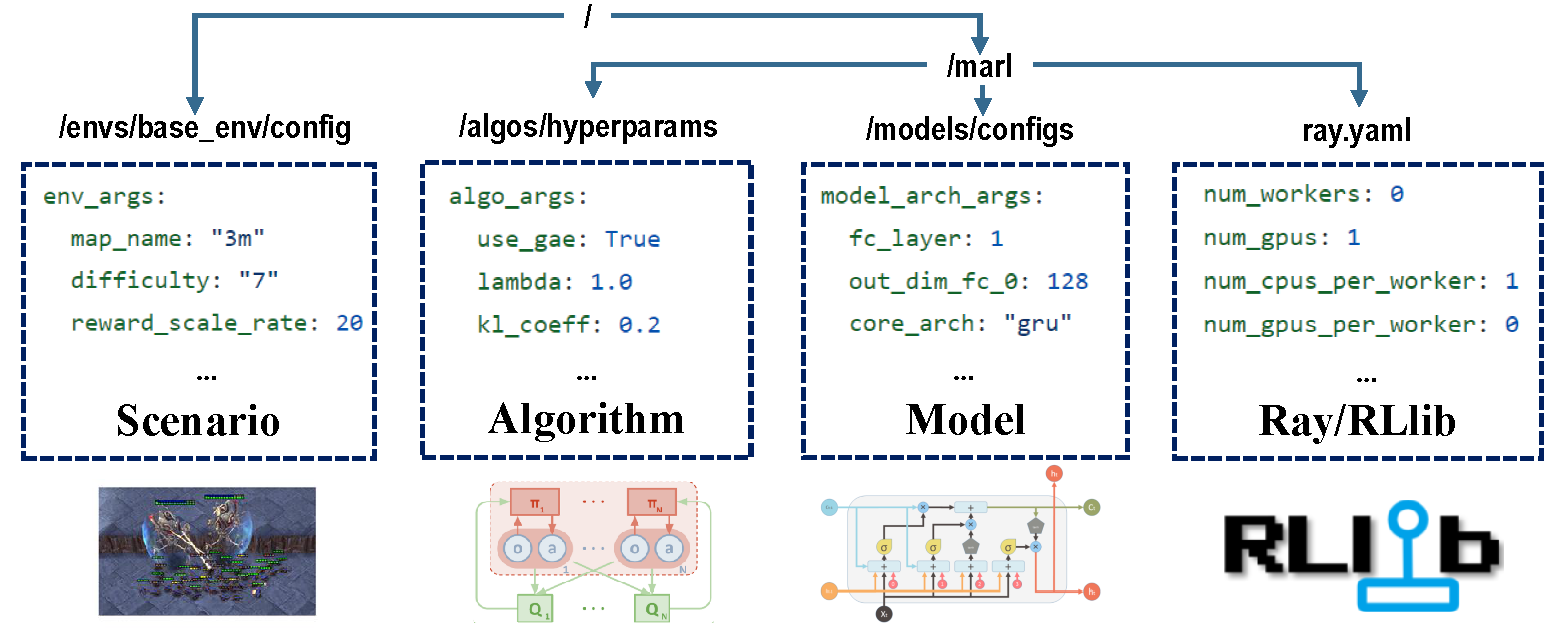
훈련하기 전에 모든 매개 변수, 특히 변경하고 싶지 않은 매개 변수를 올바르게 설정해야합니다.
참고 : Marllib API를 통해 모든 사전 설정된 매개 변수를 수정할 수도 있습니다.*
실행중인 환경에 대한 모든 종속성이 설치되어 있는지 확인하십시오. 그렇지 않으면 Marllib 문서를 참조하십시오.
| 작업 모드 | API 예제 |
|---|---|
| 협동 조합 | marl.make_env(environment_name="mpe", map_name="simple_spread", force_coop=True) |
| 공동 작업 | marl.make_env(environment_name="mpe", map_name="simple_spread") |
| 경쟁력 있는 | marl.make_env(environment_name="mpe", map_name="simple_adversary") |
| 혼합 | marl.make_env(environment_name="mpe", map_name="simple_crypto") |
Marl Research에서 인기있는 환경의 대부분은 Marllib에 의해 지원됩니다.
| Env 이름 | 학습 모드 | 관찰 가능성 | 액션 공간 | 관찰 |
|---|---|---|---|---|
| LBF | 협력 + 협력 | 둘 다 | 이산 | 1d |
| rware | 협동 조합 | 부분적 | 이산 | 1d |
| MPE | 협력 + 협력 + 혼합 | 둘 다 | 둘 다 | 1d |
| SISL | 협력 + 협력 | 가득한 | 둘 다 | 1d |
| SMAC | 협동 조합 | 부분적 | 이산 | 1d |
| MetAdrive | 공동 작업 | 부분적 | 마디 없는 | 1d |
| 배가 | 협업 + 혼합 | 부분적 | 이산 | 2d |
| Pommerman | 협업 + 경쟁 + 혼합 | 둘 다 | 이산 | 2d |
| 마무조코 | 협동 조합 | 가득한 | 마디 없는 | 1d |
| grf | 협업 + 혼합 | 가득한 | 이산 | 2d |
| 하나비 | 협동 조합 | 부분적 | 이산 | 1d |
| 친구 | 협력 + 혼합 | 부분적 | 둘 다 | 1d |
| gobigger | 협력 + 혼합 | 둘 다 | 마디 없는 | 1d |
| 지나치게 익힌 -AI | 협동 조합 | 가득한 | 이산 | 1d |
| PDN | 협동 조합 | 부분적 | 마디 없는 | 1d |
| AirCombat | 협력 + 혼합 | 부분적 | 다중 시크레 | 1d |
| Hideandseek | 경쟁 + 혼합 | 부분적 | 다중 시크레 | 1d |
각 환경에는 ENV 설정, 설치 및 중요한 메모를 포함 하여이 작업의 명령어로 표시되는 README 파일이 있습니다.
| 실행되는 대상 | API 예제 |
|---|---|
| 기차 및 양정 | marl.algos.mappo(hyperparam_source=$ENV) |
| 개발 및 디버그 | marl.algos.mappo(hyperparam_source="test") |
| 제 3 자 env | marl.algos.mappo(hyperparam_source="common") |
다음은 각 알고리즘의 특성을 설명하는 차트입니다.
| 연산 | 작업 모드를 지원합니다 | 불연속 조치 | 연속적인 행동 | 정책 유형 |
|---|---|---|---|---|
| iql * | 네 가지 모두 | ✔️ | 정책을 벗어났습니다 | |
| pg | 네 가지 모두 | ✔️ | ✔️ | 정책 |
| A2C | 네 가지 모두 | ✔️ | ✔️ | 정책 |
| DDPG | 네 가지 모두 | ✔️ | 정책을 벗어났습니다 | |
| TRPO | 네 가지 모두 | ✔️ | ✔️ | 정책 |
| PPO | 네 가지 모두 | ✔️ | ✔️ | 정책 |
| 혼수 | 네 가지 모두 | ✔️ | 정책 | |
| maddpg | 네 가지 모두 | ✔️ | 정책을 벗어났습니다 | |
| MAA2C * | 네 가지 모두 | ✔️ | ✔️ | 정책 |
| Matrpo * | 네 가지 모두 | ✔️ | ✔️ | 정책 |
| Mappo | 네 가지 모두 | ✔️ | ✔️ | 정책 |
| 하트로 | 협동 조합 | ✔️ | ✔️ | 정책 |
| 행복 | 협동 조합 | ✔️ | ✔️ | 정책 |
| VDN | 협동 조합 | ✔️ | 정책을 벗어났습니다 | |
| Qmix | 협동 조합 | ✔️ | 정책을 벗어났습니다 | |
| FACMAC | 협동 조합 | ✔️ | 정책을 벗어났습니다 | |
| VDAC | 협동 조합 | ✔️ | ✔️ | 정책 |
| vdppo * | 협동 조합 | ✔️ | ✔️ | 정책 |
* 4 개 모두 : 협력 공동 경쟁 혼합
IQL 은 Q 학습의 다중 에이전트 버전입니다. MAA2C 및 Matrpo 는 A2C 및 TRPO의 중앙 집중식 버전입니다. VDPPO 는 PPO의 값 분해 버전입니다.
에이전트 모델은 encoder 와 core arch 두 부분으로 구성됩니다. encoder 관찰 공간에 따라 Marllib에 의해 구성됩니다. 완전한 모델을 구축하려는 경우 mlp , gru 또는 lstm 선택하십시오.
| 모델 아치 | API 예제 |
|---|---|
| MLP | marl.build_model(env, algo, {"core_arch": "mlp") |
| 그루 | marl.build_model(env, algo, {"core_arch": "gru"}) |
| lstm | marl.build_model(env, algo, {"core_arch": "lstm"}) |
| 인코더 아치 | marl.build_model(env, algo, {"core_arch": "gru", "encode_layer": "128-256"}) |
| 환경 | API 예제 |
|---|---|
| 기차 | algo.fit(env, model) |
| 디버그 | algo.fit(env, model, local_mode=True) |
| 상태를 중지하십시오 | algo.fit(env, model, stop={'episode_reward_mean': 2000, 'timesteps_total': 10000000}) |
| 정책 공유 | algo.fit(env, model, share_policy='all') # or 'group' / 'individual' |
| 모델 저장 | algo.fit(env, model, checkpoint_freq=100, checkpoint_end=True) |
| GPU 가속 | algo.fit(env, model, local_mode=False, num_gpus=1) |
| CPU 가속 | algo.fit(env, model, local_mode=False, num_workers=5) |
from marllib import marl
# prepare env
env = marl . make_env ( environment_name = "smac" , map_name = "5m_vs_6m" )
# initialize algorithm with appointed hyper-parameters
mappo = marl . algos . mappo ( hyperparam_source = "smac" )
# build agent model based on env + algorithms + user preference
model = marl . build_model ( env , mappo , { "core_arch" : "gru" , "encode_layer" : "128-256" })
# start training
mappo . fit (
env , model ,
stop = { "timesteps_total" : 1000000 },
checkpoint_freq = 100 ,
share_policy = "group"
)
# rendering
mappo . render (
env , model ,
local_mode = True ,
restore_path = { 'params_path' : "checkpoint/params.json" ,
'model_path' : "checkpoint/checkpoint-10" }
)현재 작업 디렉토리에서는 저장된 모델뿐만 아니라 모든 교육 데이터 (로깅 및 텐서 플로우 파일)를 찾을 수 있습니다. 학습 곡선을 시각화하려면 Tensorboard를 사용할 수 있습니다. 아래 단계를 따르십시오.
pip install tensorboardtensorboard --logdir .또는 자세한 지침은이 자습서를 참조하십시오.
기존의 모든 결과 목록을 보려면이 링크를 방문 할 수 있습니다. 이 결과는 이전 버전의 Marllib에서 얻어졌으며 현재 결과와 비교할 때 불일치로 이어질 수 있습니다.
Marllib은 당신이 참조 할 수있는 몇 가지 실제 예를 제공합니다.
ray.tune 사용한 정책/모델 성능을 Fintune. Google 공동 작업에서 MPE + Mappo 예제를 사용해보십시오! 더 많은 튜토리얼 문서가 여기에서 제공됩니다.
MARL (Multi-Agent 강화 학습)의 연구 및 검토 논문 모음을 이용할 수 있습니다. 이 논문은 출판 날짜와 해당 환경에 대한 평가를 바탕으로 구성되었습니다.
알고리즘 : 환경 :
| 채널 | 링크 |
|---|---|
| 문제 | Github 문제 |
향후 릴리스 로드맵은 로드맵에서 제공됩니다.
우리는 다중 에이전트 강화 학습에 관한 소규모 팀이며, 우리가 얻을 수있는 모든 도움을받을 것입니다! 참여하려면 다음은 기여 지침에 대한 정보와 로컬로 코드를 테스트하는 방법에 대한 정보가 있습니다.
예를 들어 버그보고, 문서 작성 또는 번역, 코드 검토 또는 리팩토링, 새로운 기능 요청 또는 구현 등 여러 가지 방법으로 기여할 수 있습니다.
연구에서 marllib을 사용하는 경우 Marllib 종이를 인용하십시오.
@article{hu2022marllib,
author = {Siyi Hu and Yifan Zhong and Minquan Gao and Weixun Wang and Hao Dong and Xiaodan Liang and Zhihui Li and Xiaojun Chang and Yaodong Yang},
title = {MARLlib: A Scalable and Efficient Multi-agent Reinforcement Learning Library},
journal = {Journal of Machine Learning Research},
year = {2023},
}Marllib <link>에 기반을 둔 작품
@InProceedings{hu2022policy,
title={Policy Diagnosis via Measuring Role Diversity in Cooperative Multi-agent {RL}},
author={Hu, Siyi and Xie, Chuanlong and Liang, Xiaodan and Chang, Xiaojun},
booktitle={Proceedings of the 39th International Conference on Machine Learning},
year={2022},
}
@misc{zhong2023heterogeneousagent,
title={Heterogeneous-Agent Reinforcement Learning},
author={Yifan Zhong and Jakub Grudzien Kuba and Siyi Hu and Jiaming Ji and Yaodong Yang},
archivePrefix={arXiv},
year={2023},
}

