DeepLabV3Plus Pytorch
1.0.0
預處理的DeepLabV3,DeepLabV3+用於Pascal VOC和CityScapes。
| DeepLabv3 | deeplabv3+ |
|---|---|
| DeepLabv3_Resnet50 | deeplabv3plus_resnet50 |
| DeepLabv3_Resnet101 | deeplabv3plus_resnet101 |
| deeplabv3_mobilenet | deeplabv3plus_mobilenet |
| deeplabv3_hrnetv2_48 | deeplabv3plus_hrnetv2_48 |
| deeplabv3_hrnetv2_32 | deeplabv3plus_hrnetv2_32 |
| deeplabv3_xception | deeplabv3plus_xception |
有關所有模型條目,請參閱網絡/建模。
下載預估計的型號:Dropbox,Tencent Weiyun
注意:HRNET主鏈由@timophymyl貢獻。 Google Drive可以使用預訓練的骨幹。
model = network . modeling . __dict__ [ MODEL_NAME ]( num_classes = NUM_CLASSES , output_stride = OUTPUT_SRTIDE )
model . load_state_dict ( torch . load ( PATH_TO_PTH )[ 'model_state' ] ) outputs = model ( images )
preds = outputs . max ( 1 )[ 1 ]. detach (). cpu (). numpy ()
colorized_preds = val_dst . decode_target ( preds ). astype ( 'uint8' ) # To RGB images, (N, H, W, 3), ranged 0~255, numpy array
# Do whatever you like here with the colorized segmentation maps
colorized_preds = Image . fromarray ( colorized_preds [ 0 ]) # to PIL Image注意:本倉庫中的所有預訓練模型均經過訓練,沒有可分離的捲積。
在此存儲庫中支持了可分離的捲積。我們提供nn.Conv2d簡單的工具network.convert_to_separable_conv AtrousSeparableConvolution如果需要,請用' - separable_conv'運行main.py。有關更多詳細信息,請參見“ main..py”和“網絡/_deeplab.py”。
單圖:
python predict.py --input datasets/data/cityscapes/leftImg8bit/train/bremen/bremen_000000_000019_leftImg8bit.png --dataset cityscapes --model deeplabv3plus_mobilenet --ckpt checkpoints/best_deeplabv3plus_mobilenet_cityscapes_os16.pth --save_val_results_to test_results圖像文件夾:
python predict.py --input datasets/data/cityscapes/leftImg8bit/train/bremen --dataset cityscapes --model deeplabv3plus_mobilenet --ckpt checkpoints/best_deeplabv3plus_mobilenet_cityscapes_os16.pth --save_val_results_to test_results有關如何添加新骨幹的更多詳細信息,請參考此提交(Xception)。
您可以在自己的數據集上訓練DeepLab模型。您的torch.utils.data.Dataset應該提供一種解碼方法,將您的預測轉換為有色圖像,就像VOC數據集一樣:
class MyDataset ( data . Dataset ):
...
@ classmethod
def decode_target ( cls , mask ):
"""decode semantic mask to RGB image"""
return cls . cmap [ mask ]培訓:513x513隨機作物
驗證:513x513中心作物
| 模型 | 批量大小 | 拖鞋 | 火車/瓦爾操作系統 | miou | Dropbox | 騰訊Weiyun |
|---|---|---|---|---|---|---|
| DeepLabv3-Mobilenet | 16 | 6.0g | 16/16 | 0.701 | 下載 | 下載 |
| DeepLabv3-Resnet50 | 16 | 51.4g | 16/16 | 0.769 | 下載 | 下載 |
| DeepLabv3-Resnet101 | 16 | 72.1g | 16/16 | 0.773 | 下載 | 下載 |
| deeplabv3plus-mobilenet | 16 | 17.0g | 16/16 | 0.711 | 下載 | 下載 |
| deeplabv3plus-resnet50 | 16 | 62.7g | 16/16 | 0.772 | 下載 | 下載 |
| deeplabv3plus-resnet101 | 16 | 83.4克 | 16/16 | 0.783 | 下載 | 下載 |
培訓:768x768隨機作物
驗證:1024x2048
| 模型 | 批量大小 | 拖鞋 | 火車/瓦爾操作系統 | miou | Dropbox | 騰訊Weiyun |
|---|---|---|---|---|---|---|
| deeplabv3plus-mobilenet | 16 | 135克 | 16/16 | 0.721 | 下載 | 下載 |
| deeplabv3plus-resnet101 | 16 | N/A。 | 16/16 | 0.762 | 下載 | N/A。 |












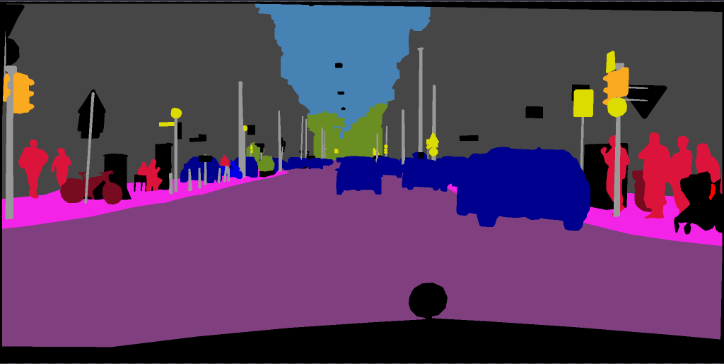

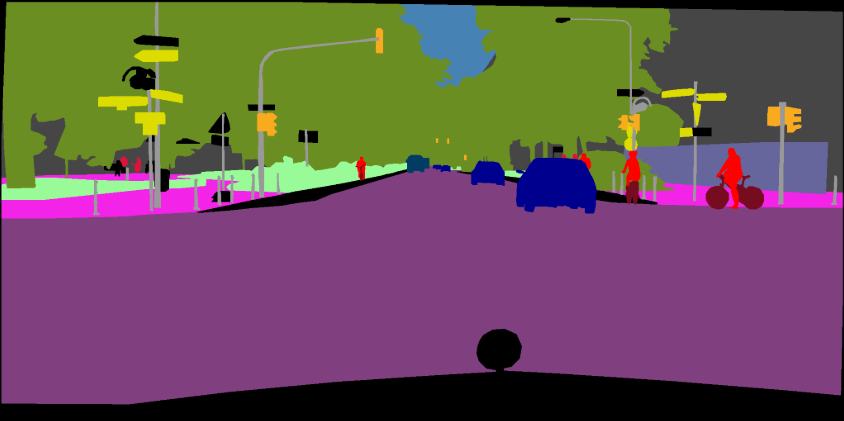

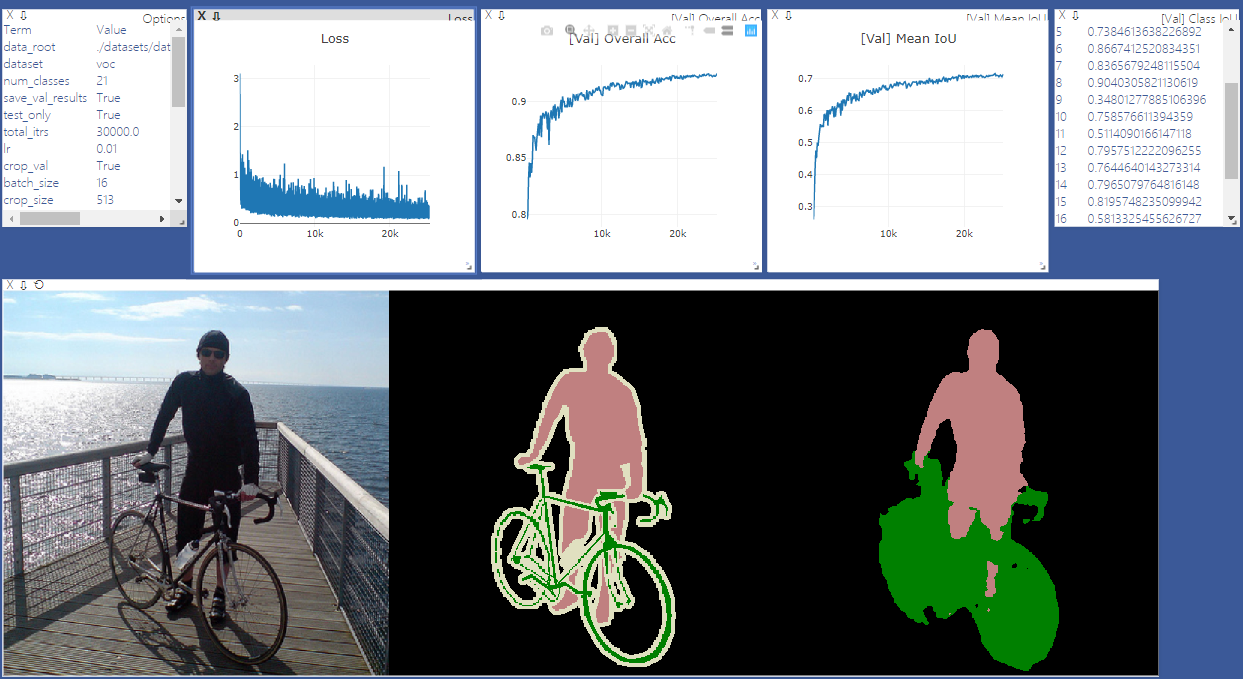
pip install -r requirements.txt您可以使用“ - 下載”選項運行train.py,以下載和提取Pascal VOC數據集。 defaut路徑是'./datasets/data':
/datasets
/data
/VOCdevkit
/VOC2012
/SegmentationClass
/JPEGImages
...
...
/VOCtrainval_11-May-2012.tar
...
參見[2]的第4章
The original dataset contains 1464 (train), 1449 (val), and 1456 (test) pixel-level annotated images. We augment the dataset by the extra annotations provided by [76], resulting in 10582 (trainaug) training images. The performance is measured in terms of pixel intersection-over-union averaged across the 21 classes (mIOU).
./datasets/data/train_aug.txt包含10582 trainaug圖像的文件名(不包括val圖像)。請從Dropbox或Tencent Weiyun下載其標籤。這些標籤來自Drsleep的回購。
提取Trainaug標籤(SemmentationClassaug)到VOC2012目錄。
/datasets
/data
/VOCdevkit
/VOC2012
/SegmentationClass
/SegmentationClassAug # <= the trainaug labels
/JPEGImages
...
...
/VOCtrainval_11-May-2012.tar
...
啟動視覺切割以進行可視化。如果不需要可視化,請刪除“ -enable_vis”。
# Run visdom server on port 28333
visdom -port 28333運行main.py,使用“ - 年度2012_AUG”在8月2日在Pascal VOC2012上訓練您的模型。您也可以在4 GPU上與'-GPU_ID 0,1,2,3'在4 GPU上平行培訓
注意:此存儲庫中沒有Syncbn,因此使用多個GPU和小批量尺寸的培訓可能會降低性能。有關Syncbn的更多詳細信息,請參見pytorch編碼
python main.py --model deeplabv3plus_mobilenet --enable_vis --vis_port 28333 --gpu_id 0 --year 2012_aug --crop_val --lr 0.01 --crop_size 513 --batch_size 16 --output_stride 16使用' - continue_training'運行main.py,以從your_ckpt恢復優化器和調度程序的狀態。
python main.py ... --ckpt YOUR_CKPT --continue_training結果將保存在./ results。
python main.py --model deeplabv3plus_mobilenet --enable_vis --vis_port 28333 --gpu_id 0 --year 2012_aug --crop_val --lr 0.01 --crop_size 513 --batch_size 16 --output_stride 16 --ckpt checkpoints/best_deeplabv3plus_mobilenet_voc_os16.pth --test_only --save_val_results /datasets
/data
/cityscapes
/gtFine
/leftImg8bit
python main.py --model deeplabv3plus_mobilenet --dataset cityscapes --enable_vis --vis_port 28333 --gpu_id 0 --lr 0.1 --crop_size 768 --batch_size 16 --output_stride 16 --data_root ./datasets/data/cityscapes [1]重新思考對語義圖像分割的靜置卷積
[2]用可分離的捲積編碼器進行編碼,以進行語義圖像分割


