DeepLabV3Plus Pytorch
1.0.0
Pascal Voc&Cityscapes用の前提条件のdeeplabv3、deeplabv3+。
| deeplabv3 | deeplabv3+ |
|---|---|
| deeplabv3_resnet50 | deeplabv3plus_resnet50 |
| deeplabv3_resnet101 | deeplabv3plus_resnet101 |
| deeplabv3_mobilenet | deeplabv3plus_mobilenet |
| deeplabv3_hrnetv2_48 | deeplabv3plus_hrnetv2_48 |
| deeplabv3_hrnetv2_32 | deeplabv3plus_hrnetv2_32 |
| deeplabv3_xception | deeplabv3plus_xcection |
すべてのモデルエントリについては、ネットワーク/モデリング.pyを参照してください。
冒険モデルのダウンロード:Dropbox、Tencent Weiyun
注:HRNETバックボーンは@Timothylimylによって寄与されました。 Google Driveで事前に訓練されたバックボーンを利用できます。
model = network . modeling . __dict__ [ MODEL_NAME ]( num_classes = NUM_CLASSES , output_stride = OUTPUT_SRTIDE )
model . load_state_dict ( torch . load ( PATH_TO_PTH )[ 'model_state' ] ) outputs = model ( images )
preds = outputs . max ( 1 )[ 1 ]. detach (). cpu (). numpy ()
colorized_preds = val_dst . decode_target ( preds ). astype ( 'uint8' ) # To RGB images, (N, H, W, 3), ranged 0~255, numpy array
# Do whatever you like here with the colorized segmentation maps
colorized_preds = Image . fromarray ( colorized_preds [ 0 ]) # to PIL Image注:このレポの事前に訓練されたすべてのモデルは、厳しい分離可能な畳み込みなしで訓練されました。
このレポでは、耳障りな分離可能な畳み込みがサポートされています。 nn.Conv2d AtrousSeparableConvolutionに変換するために、シンプルなツールnetwork.convert_to_separable_convを提供します。必要な場合は、 '-separable_conv'でmain.pyを実行してください。詳細については、「main.py」および「network/_deeplab.py」を参照してください。
単一画像:
python predict.py --input datasets/data/cityscapes/leftImg8bit/train/bremen/bremen_000000_000019_leftImg8bit.png --dataset cityscapes --model deeplabv3plus_mobilenet --ckpt checkpoints/best_deeplabv3plus_mobilenet_cityscapes_os16.pth --save_val_results_to test_results画像フォルダー:
python predict.py --input datasets/data/cityscapes/leftImg8bit/train/bremen --dataset cityscapes --model deeplabv3plus_mobilenet --ckpt checkpoints/best_deeplabv3plus_mobilenet_cityscapes_os16.pth --save_val_results_to test_results新しいバックボーンを追加する方法の詳細については、このコミット(Xception)を参照してください。
独自のデータセットでDeepLabモデルをトレーニングできます。 torch.utils.data.Datasetは、VOCデータセットのように、予測を色付けされた画像に変換するデコード方法を提供する必要があります。
class MyDataset ( data . Dataset ):
...
@ classmethod
def decode_target ( cls , mask ):
"""decode semantic mask to RGB image"""
return cls . cmap [ mask ]トレーニング:513x513ランダム作物
検証:513x513センター作物
| モデル | バッチサイズ | フロップ | 電車/ヴァルOS | miou | ドロップボックス | Tencent Weiyun |
|---|---|---|---|---|---|---|
| deeplabv3-mobilenet | 16 | 6.0g | 16/16 | 0.701 | ダウンロード | ダウンロード |
| deeplabv3-resnet50 | 16 | 51.4g | 16/16 | 0.769 | ダウンロード | ダウンロード |
| deeplabv3-resnet101 | 16 | 72.1g | 16/16 | 0.773 | ダウンロード | ダウンロード |
| deeplabv3plus-mobilenet | 16 | 17.0g | 16/16 | 0.711 | ダウンロード | ダウンロード |
| deeplabv3plus-resnet50 | 16 | 62.7g | 16/16 | 0.772 | ダウンロード | ダウンロード |
| deeplabv3plus-resnet101 | 16 | 83.4g | 16/16 | 0.783 | ダウンロード | ダウンロード |
トレーニング:768x768ランダム作物
検証:1024x2048
| モデル | バッチサイズ | フロップ | 電車/ヴァルOS | miou | ドロップボックス | Tencent Weiyun |
|---|---|---|---|---|---|---|
| deeplabv3plus-mobilenet | 16 | 135g | 16/16 | 0.721 | ダウンロード | ダウンロード |
| deeplabv3plus-resnet101 | 16 | n/a | 16/16 | 0.762 | ダウンロード | n/a |














pip install -r requirements.txtPascal VOCデータセットをダウンロードして抽出する「-download」オプションでtrain.pyを実行できます。 Defaut Pathは './datasets/data'です。
/datasets
/data
/VOCdevkit
/VOC2012
/SegmentationClass
/JPEGImages
...
...
/VOCtrainval_11-May-2012.tar
...
[2]の第4章を参照してください
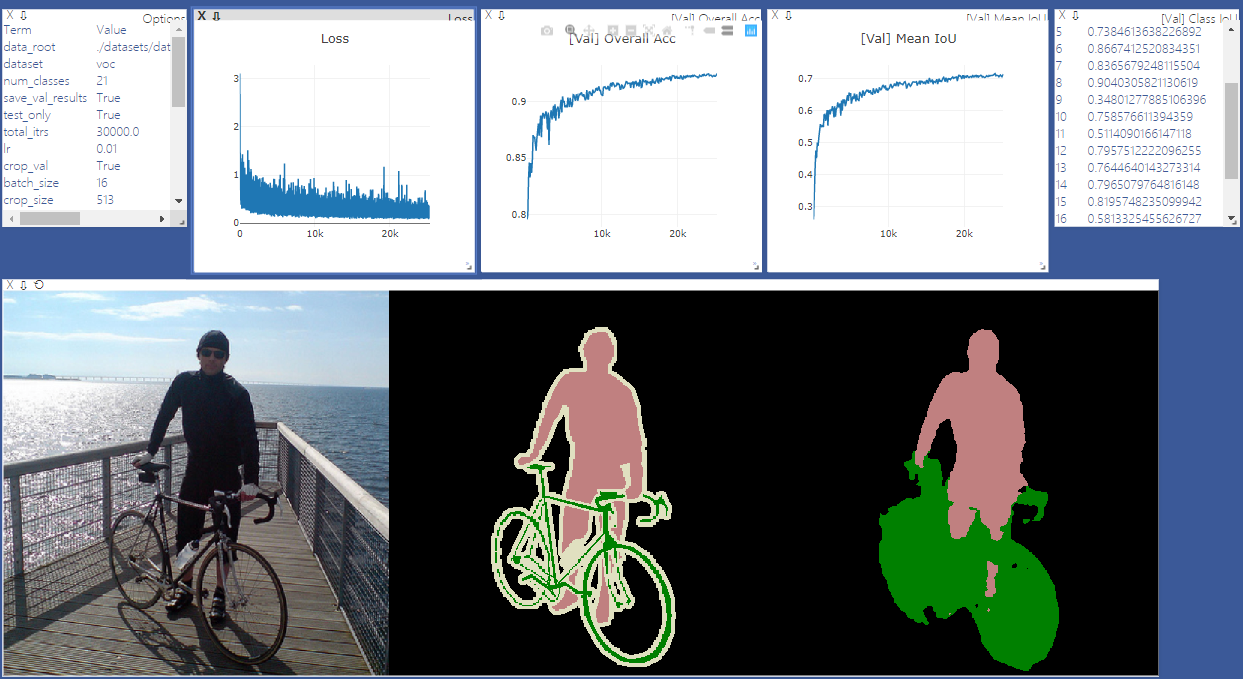
The original dataset contains 1464 (train), 1449 (val), and 1456 (test) pixel-level annotated images. We augment the dataset by the extra annotations provided by [76], resulting in 10582 (trainaug) training images. The performance is measured in terms of pixel intersection-over-union averaged across the 21 classes (mIOU).
./datasets/data/train_aug.txtには、10582 Trainaug画像のファイル名が含まれています(VAL画像は除外されています)。 DropboxまたはTencent Weiyunからラベルをダウンロードしてください。これらのラベルは、Drsleepのリポジトリから来ています。
voc2012ディレクトリにtrainaugラベル(SegmentationClassaug)を抽出します。
/datasets
/data
/VOCdevkit
/VOC2012
/SegmentationClass
/SegmentationClassAug # <= the trainaug labels
/JPEGImages
...
...
/VOCtrainval_11-May-2012.tar
...
視覚化のために訪問を開始します。視覚化が必要ない場合は、 '-Enable_Vis'を削除してください。
# Run visdom server on port 28333
visdom -port 28333Pascal voc2012でモデルをトレーニングするには、「-year 2012_aug」でmain.pyを実行します。
注:このリポジトリにはsyncbnはありません。したがって、複数のGPUと小さなバッチサイズでのトレーニングにより、パフォーマンスが低下する場合があります。 Syncbnの詳細については、Pytorch-Encodingを参照してください
python main.py --model deeplabv3plus_mobilenet --enable_vis --vis_port 28333 --gpu_id 0 --year 2012_aug --crop_val --lr 0.01 --crop_size 513 --batch_size 16 --output_stride 16'--continue_training'でmain.pyを実行して、your_ckptからoptimizerとスケジューラのstate_dictを復元します。
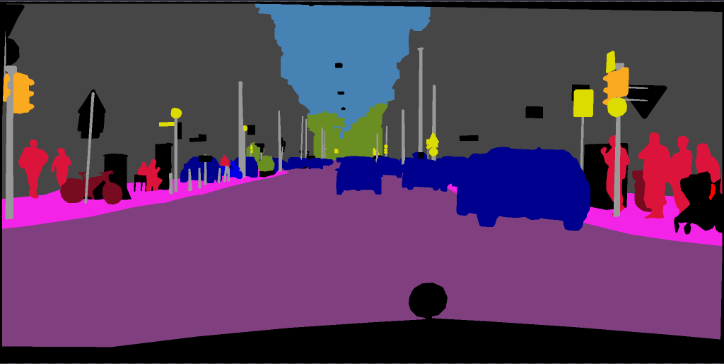
python main.py ... --ckpt YOUR_CKPT --continue_training結果は./resultsで保存されます。
python main.py --model deeplabv3plus_mobilenet --enable_vis --vis_port 28333 --gpu_id 0 --year 2012_aug --crop_val --lr 0.01 --crop_size 513 --batch_size 16 --output_stride 16 --ckpt checkpoints/best_deeplabv3plus_mobilenet_voc_os16.pth --test_only --save_val_results /datasets
/data
/cityscapes
/gtFine
/leftImg8bit
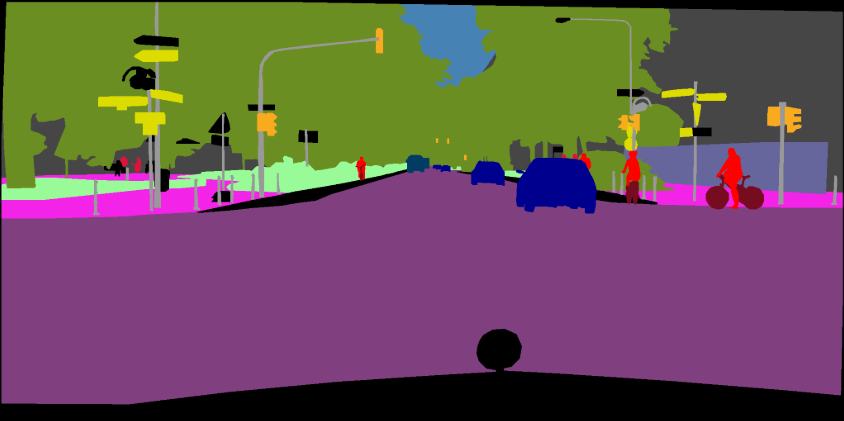
python main.py --model deeplabv3plus_mobilenet --dataset cityscapes --enable_vis --vis_port 28333 --gpu_id 0 --lr 0.1 --crop_size 768 --batch_size 16 --output_stride 16 --data_root ./datasets/data/cityscapes [1]セマンティック画像セグメンテーションのための耳障りな畳み込みを再考します
[2]セマンティック画像セグメンテーションのための不安定な分離可能な畳み込みを備えたエンコーダデコーダー


