DeepLabV3Plus Pytorch
1.0.0
Предварительный DeepLabv3, DeepLabv3+ для Pascal Voc & CityScapes.
| DeepLabv3 | DeepLabv3+ |
|---|---|
| DeepLabv3_Resnet50 | DeepLabv3plus_resnet50 |
| DeepLabv3_Resnet101 | DeepLabv3plus_resnet101 |
| DeepLabv3_mobilenet | DeepLabv3plus_mobilenet |
| DeepLabv3_hrnetv2_48 | DeepLabv3plus_hrnetv2_48 |
| DeepLabv3_hrnetv2_32 | DeepLabv3plus_hrnetv2_32 |
| DeepLabv3_xception | DeepLabv3plus_xception |
Пожалуйста, обратитесь к Network/Modeling.py для всех записей модели.
Скачать предварительные модели: Dropbox, Tencent Weiyun
Примечание: магистраль HRNet был внесен @timothylimyl. Предварительно обученная основа доступна на Google Drive.
model = network . modeling . __dict__ [ MODEL_NAME ]( num_classes = NUM_CLASSES , output_stride = OUTPUT_SRTIDE )
model . load_state_dict ( torch . load ( PATH_TO_PTH )[ 'model_state' ] ) outputs = model ( images )
preds = outputs . max ( 1 )[ 1 ]. detach (). cpu (). numpy ()
colorized_preds = val_dst . decode_target ( preds ). astype ( 'uint8' ) # To RGB images, (N, H, W, 3), ranged 0~255, numpy array
# Do whatever you like here with the colorized segmentation maps
colorized_preds = Image . fromarray ( colorized_preds [ 0 ]) # to PIL ImageПримечание . Все предварительно обученные модели в этом репо были обучены без атросной отдельной сверты.
Atrous разделяемая свертка поддерживается в этом репо. Мы предоставляем простую network.convert_to_separable_conv инструментов.convert_to_separable_conv, чтобы преобразовать nn.Conv2d в AtrousSeparableConvolution . Пожалуйста, запустите main.py с '-sparable_conv', если это требуется . См. «Main.py» и «Network/_deeplab.py» для получения более подробной информации.
Одиночное изображение:
python predict.py --input datasets/data/cityscapes/leftImg8bit/train/bremen/bremen_000000_000019_leftImg8bit.png --dataset cityscapes --model deeplabv3plus_mobilenet --ckpt checkpoints/best_deeplabv3plus_mobilenet_cityscapes_os16.pth --save_val_results_to test_resultsПапка изображений:
python predict.py --input datasets/data/cityscapes/leftImg8bit/train/bremen --dataset cityscapes --model deeplabv3plus_mobilenet --ckpt checkpoints/best_deeplabv3plus_mobilenet_cityscapes_os16.pth --save_val_results_to test_resultsПожалуйста, обратитесь к этому коммитию (xception) для получения более подробной информации о том, как добавить новые основы.
Вы можете обучить модели DeepLab на своих собственных наборах данных. Ваш torch.utils.data.Dataset должен предоставить метод декодирования, который преобразует ваши прогнозы в раскрашенные изображения, точно так же, как набор данных VOC:
class MyDataset ( data . Dataset ):
...
@ classmethod
def decode_target ( cls , mask ):
"""decode semantic mask to RGB image"""
return cls . cmap [ mask ] Обучение: 513x513 Случайный урожай
Валидация: 513x513 Центральный урожай
| Модель | Размер партии | Флопс | поезда/Валь ОС | Миу | Dropbox | Tencent Weiyun |
|---|---|---|---|---|---|---|
| Deeplabv3-Mobilenet | 16 | 6,0 г | 16/16 | 0,701 | Скачать | Скачать |
| DeepLabv3-resnet50 | 16 | 51.4G | 16/16 | 0,769 | Скачать | Скачать |
| DeepLabv3-resnet101 | 16 | 72,1 г | 16/16 | 0,773 | Скачать | Скачать |
| DeepLabv3plus-Mobilenet | 16 | 17,0 г | 16/16 | 0,711 | Скачать | Скачать |
| DeepLabv3plus-resnet50 | 16 | 62,7 г | 16/16 | 0,772 | Скачать | Скачать |
| DeepLabv3plus-resnet101 | 16 | 83,4 г | 16/16 | 0,783 | Скачать | Скачать |
Обучение: 768x768 случайный урожай
Валидация: 1024x2048
| Модель | Размер партии | Флопс | поезда/Валь ОС | Миу | Dropbox | Tencent Weiyun |
|---|---|---|---|---|---|---|
| DeepLabv3plus-Mobilenet | 16 | 135G | 16/16 | 0,721 | Скачать | Скачать |
| DeepLabv3plus-resnet101 | 16 | N/a | 16/16 | 0,762 | Скачать | N/a |












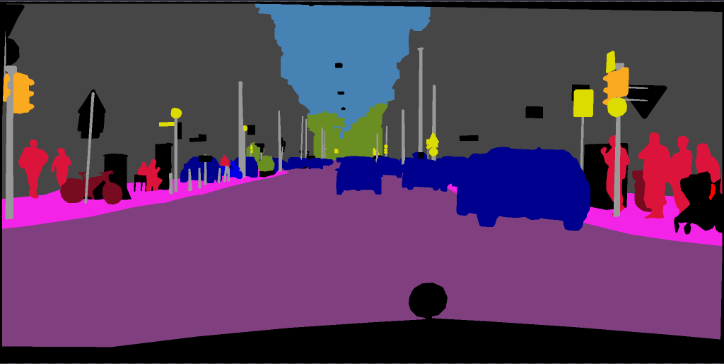

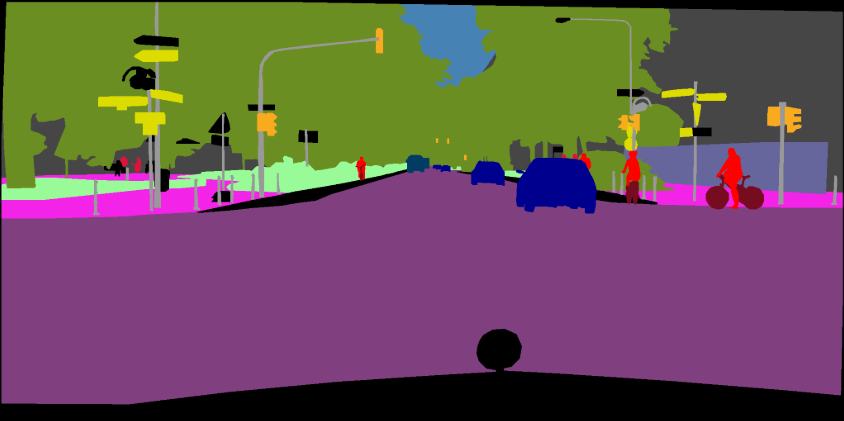

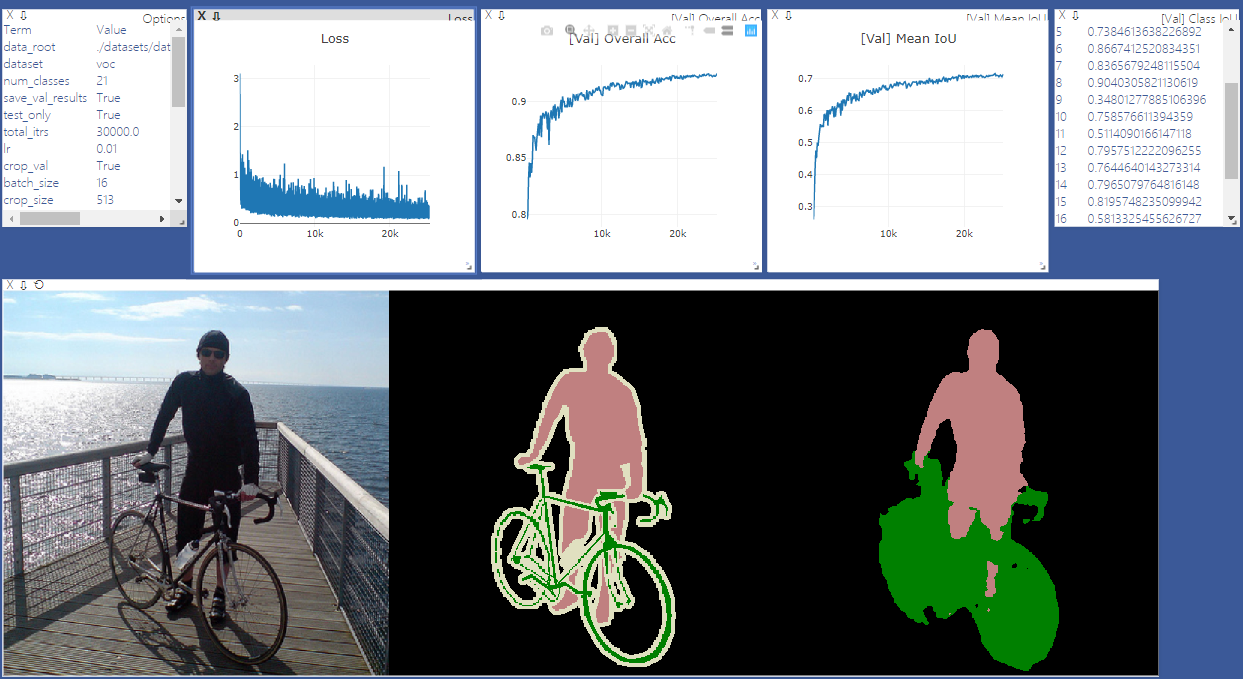
pip install -r requirements.txtВы можете запустить Train.py с опцией «--download», чтобы загрузить и извлечь набор данных Pascal VOC. Путь Defaut - ./datasets/data ':
/datasets
/data
/VOCdevkit
/VOC2012
/SegmentationClass
/JPEGImages
...
...
/VOCtrainval_11-May-2012.tar
...
См. Главу 4 [2]
The original dataset contains 1464 (train), 1449 (val), and 1456 (test) pixel-level annotated images. We augment the dataset by the extra annotations provided by [76], resulting in 10582 (trainaug) training images. The performance is measured in terms of pixel intersection-over-union averaged across the 21 classes (mIOU).
./datasets/data/train_aug.txt включает в себя имена файлов 10582 изображений Trainaug (изображения VAL исключены). Пожалуйста, загрузите их лейблы с Dropbox или Tencent Weiyun. Эти этикетки поступают из репо доля.
Извлеките Trainaug Labels (SegmationClassaug) в каталог VOC2012.
/datasets
/data
/VOCdevkit
/VOC2012
/SegmentationClass
/SegmentationClassAug # <= the trainaug labels
/JPEGImages
...
...
/VOCtrainval_11-May-2012.tar
...
Начните визуал для визуализации. Пожалуйста, удалите '-enable_vis', если визуализация не нужна.
# Run visdom server on port 28333
visdom -port 28333Запустите main.py с "--год 2012_AUG" , чтобы обучить свою модель на Pascal VOC2012 августа. Вы также можете параллельно обучение на 4 графических процессорах с '-gpu_id 0,1,2,3'
Примечание: в этом репо нет синхян, поэтому обучение с многочисленными графическими процессорами и небольшим размером партии может ухудшить производительность. См. Pytorch-кодирование для получения более подробной информации о Syncbn
python main.py --model deeplabv3plus_mobilenet --enable_vis --vis_port 28333 --gpu_id 0 --year 2012_aug --crop_val --lr 0.01 --crop_size 513 --batch_size 16 --output_stride 16Запустите main.py с '-continue_training', чтобы восстановить состояние state_dict оптимизатора и планировщика из your_ckpt.
python main.py ... --ckpt YOUR_CKPT --continue_trainingРезультаты будут сохранены на ./Results.
python main.py --model deeplabv3plus_mobilenet --enable_vis --vis_port 28333 --gpu_id 0 --year 2012_aug --crop_val --lr 0.01 --crop_size 513 --batch_size 16 --output_stride 16 --ckpt checkpoints/best_deeplabv3plus_mobilenet_voc_os16.pth --test_only --save_val_results /datasets
/data
/cityscapes
/gtFine
/leftImg8bit
python main.py --model deeplabv3plus_mobilenet --dataset cityscapes --enable_vis --vis_port 28333 --gpu_id 0 --lr 0.1 --crop_size 768 --batch_size 16 --output_stride 16 --data_root ./datasets/data/cityscapes [1] Переосмысление прозрачной сверты для семантической сегментации изображения
[2] Энкодер-декодер с Atrous Scretabile Convolrotest для сегментации семантического изображения


