DeepLabV3Plus Pytorch
1.0.0
Deeplabv3 pretrained, deeplabv3+ untuk voc & cityscapes.
| Deeplabv3 | DEEPLABV3+ |
|---|---|
| deeplabv3_resnet50 | deeplabv3plus_resnet50 |
| deeplabv3_resnet101 | deeplabv3plus_resnet101 |
| deeplabv3_mobilenet | deeplabv3plus_mobilenet |
| deeplabv3_hrnetv2_48 | deeplabv3plus_hrnetv2_48 |
| deeplabv3_hrnetv2_32 | deeplabv3plus_hrnetv2_32 |
| deeplabv3_xception | deeplabv3plus_xception |
Silakan merujuk ke network/modeling.py untuk semua entri model.
Unduh model pretrained: dropbox, tencent weiyun
Catatan: Tulang punggung HRNET disumbangkan oleh @timothylimyl. Backbone pra-terlatih tersedia di Google Drive.
model = network . modeling . __dict__ [ MODEL_NAME ]( num_classes = NUM_CLASSES , output_stride = OUTPUT_SRTIDE )
model . load_state_dict ( torch . load ( PATH_TO_PTH )[ 'model_state' ] ) outputs = model ( images )
preds = outputs . max ( 1 )[ 1 ]. detach (). cpu (). numpy ()
colorized_preds = val_dst . decode_target ( preds ). astype ( 'uint8' ) # To RGB images, (N, H, W, 3), ranged 0~255, numpy array
# Do whatever you like here with the colorized segmentation maps
colorized_preds = Image . fromarray ( colorized_preds [ 0 ]) # to PIL ImageCATATAN : Semua model pra-terlatih dalam repo ini dilatih tanpa konvolusi yang dapat dipisahkan.
Konvolusi yang dapat dipisahkan dengan sangat buruk didukung dalam repo ini. Kami menyediakan network.convert_to_separable_conv alat sederhana.convert_to_separable_conv untuk mengonversi nn.Conv2d ke AtrousSeparableConvolution . Harap jalankan Main.py dengan '--Peparable_conv' jika diperlukan . Lihat 'Main.py' dan 'Network/_DeePlab.py' untuk lebih detailnya.
Gambar tunggal:
python predict.py --input datasets/data/cityscapes/leftImg8bit/train/bremen/bremen_000000_000019_leftImg8bit.png --dataset cityscapes --model deeplabv3plus_mobilenet --ckpt checkpoints/best_deeplabv3plus_mobilenet_cityscapes_os16.pth --save_val_results_to test_resultsFolder Gambar:
python predict.py --input datasets/data/cityscapes/leftImg8bit/train/bremen --dataset cityscapes --model deeplabv3plus_mobilenet --ckpt checkpoints/best_deeplabv3plus_mobilenet_cityscapes_os16.pth --save_val_results_to test_resultsSilakan merujuk ke komit ini (Xception) untuk detail lebih lanjut tentang cara menambahkan tulang punggung baru.
Anda dapat melatih model Deeplab pada dataset Anda sendiri. torch.utils.data.Dataset Anda harus memberikan metode decoding yang mengubah prediksi Anda menjadi gambar yang diwarnai, seperti halnya VOC Dataset:
class MyDataset ( data . Dataset ):
...
@ classmethod
def decode_target ( cls , mask ):
"""decode semantic mask to RGB image"""
return cls . cmap [ mask ] Pelatihan: 513x513 Tanaman acak
Validasi: 513x513 Pusat Tanaman
| Model | Ukuran batch | Jepit | kereta/val os | Miou | Dropbox | Tencent Weiyun |
|---|---|---|---|---|---|---|
| DEEPLABV3-Mobilenet | 16 | 6.0g | 16/16 | 0.701 | Unduh | Unduh |
| DEEPLABV3-RESNET50 | 16 | 51.4g | 16/16 | 0.769 | Unduh | Unduh |
| DEEPLABV3-RESNET101 | 16 | 72.1g | 16/16 | 0.773 | Unduh | Unduh |
| DEEPLABV3PLUS-Mobilenet | 16 | 17.0g | 16/16 | 0.711 | Unduh | Unduh |
| DEEPLABV3PLUS-RESNET50 | 16 | 62.7g | 16/16 | 0.772 | Unduh | Unduh |
| DEEPLABV3PLUS-RESNET101 | 16 | 83.4g | 16/16 | 0.783 | Unduh | Unduh |
Pelatihan: 768x768 Tanaman acak
Validasi: 1024x2048
| Model | Ukuran batch | Jepit | kereta/val os | Miou | Dropbox | Tencent Weiyun |
|---|---|---|---|---|---|---|
| DEEPLABV3PLUS-Mobilenet | 16 | 135g | 16/16 | 0.721 | Unduh | Unduh |
| DEEPLABV3PLUS-RESNET101 | 16 | N/a | 16/16 | 0.762 | Unduh | N/a |












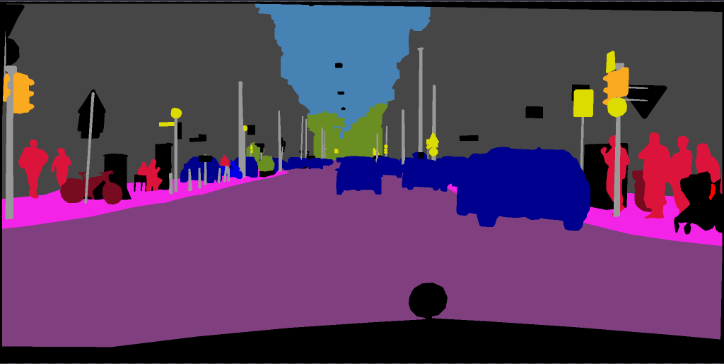

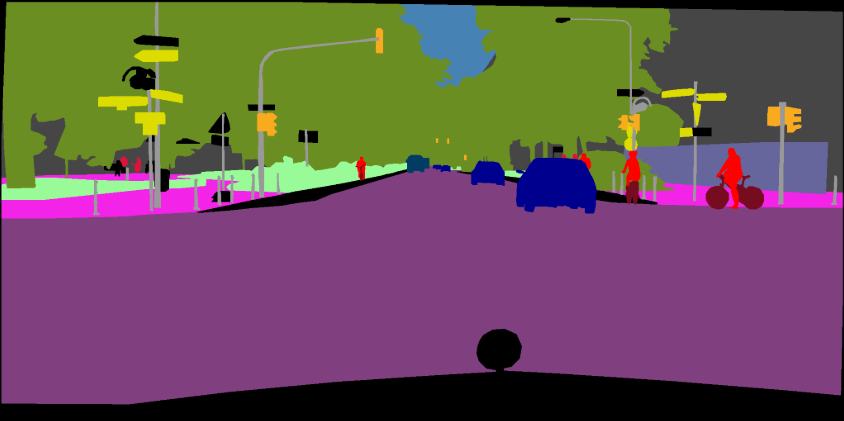

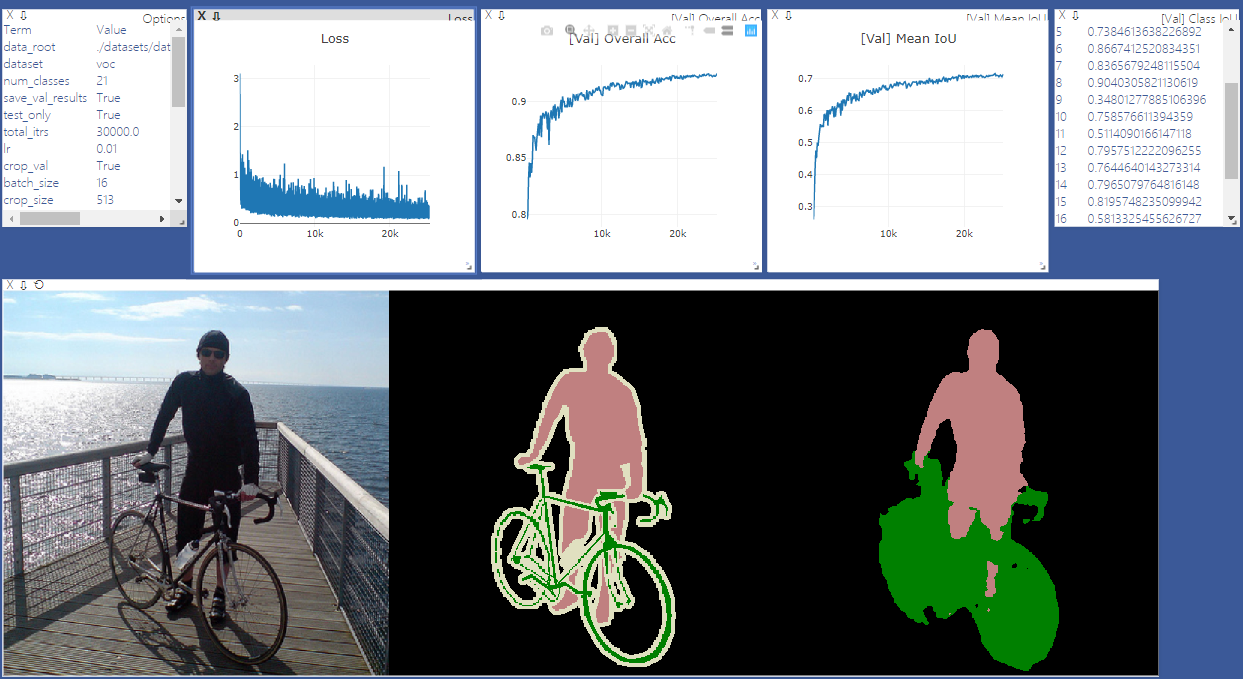
pip install -r requirements.txtAnda dapat menjalankan opsi Train.py dengan "-Download" untuk mengunduh dan mengekstrak dataset VOC Pascal. Jalur defaut adalah './datasets/data':
/datasets
/data
/VOCdevkit
/VOC2012
/SegmentationClass
/JPEGImages
...
...
/VOCtrainval_11-May-2012.tar
...
Lihat Bab 4 dari [2]
The original dataset contains 1464 (train), 1449 (val), and 1456 (test) pixel-level annotated images. We augment the dataset by the extra annotations provided by [76], resulting in 10582 (trainaug) training images. The performance is measured in terms of pixel intersection-over-union averaged across the 21 classes (mIOU).
./datasets/data/train_aug.txt menyertakan nama file 10582 gambar trainaug (gambar Val dikecualikan). Silakan mengunduh label mereka dari Dropbox atau Tencent Weiyun. Label -label itu berasal dari repo Drsleep.
Ekstrak Label Trainaug (SegmentationClassaug) ke direktori VOC2012.
/datasets
/data
/VOCdevkit
/VOC2012
/SegmentationClass
/SegmentationClassAug # <= the trainaug labels
/JPEGImages
...
...
/VOCtrainval_11-May-2012.tar
...
Mulai Visdom Sever untuk visualisasi. Harap hapus '--enable_vis' jika visualisasi tidak diperlukan.
# Run visdom server on port 28333
visdom -port 28333Jalankan Main.py dengan "--tahun 2012_Aug" untuk melatih model Anda di Pascal VOC2012 Agustus. Anda juga dapat sejajar dengan pelatihan Anda pada 4 GPU dengan '--GPU_ID 0,1,2,3'
Catatan: Tidak ada sinkronisasi dalam repo ini, jadi pelatihan dengan GPU multple dan ukuran batch kecil dapat menurunkan kinerja. Lihat Pytorch-encoding untuk detail lebih lanjut tentang Syncbn
python main.py --model deeplabv3plus_mobilenet --enable_vis --vis_port 28333 --gpu_id 0 --year 2012_aug --crop_val --lr 0.01 --crop_size 513 --batch_size 16 --output_stride 16Jalankan Main.py dengan '--continue_training' untuk mengembalikan state_dict of optimizer dan penjadwal dari your_ckpt.
python main.py ... --ckpt YOUR_CKPT --continue_trainingHasil akan disimpan di ./RESULTS.
python main.py --model deeplabv3plus_mobilenet --enable_vis --vis_port 28333 --gpu_id 0 --year 2012_aug --crop_val --lr 0.01 --crop_size 513 --batch_size 16 --output_stride 16 --ckpt checkpoints/best_deeplabv3plus_mobilenet_voc_os16.pth --test_only --save_val_results /datasets
/data
/cityscapes
/gtFine
/leftImg8bit
python main.py --model deeplabv3plus_mobilenet --dataset cityscapes --enable_vis --vis_port 28333 --gpu_id 0 --lr 0.1 --crop_size 768 --batch_size 16 --output_stride 16 --data_root ./datasets/data/cityscapes [1] Memikirkan Kembali Konvolusi Atrous untuk Segmentasi Gambar Semantik
[2] Encoder-Decoder dengan konvolusi terpisah yang buruk untuk segmentasi gambar semantik


