DeepLabV3Plus Pytorch
1.0.0
DeepLabv3 pré-entraîné, DeepLabv3 + pour Pascal Voc & Cityscapes.
| DeepLabv3 | DeepLabv3 + |
|---|---|
| deepLabv3_resnet50 | DeepLabv3Plus_resnet50 |
| deepLabv3_resnet101 | DeepLabv3Plus_resnet101 |
| DeepLabv3_Mobilenet | DeepLabv3Plus_Mobilenet |
| deepLabv3_hrnetv2_48 | DeepLabv3Plus_Hrnetv2_48 |
| deepLabv3_hrnetv2_32 | DeepLabv3Plus_hrnetv2_32 |
| DeepLabv3_xception | DeepLabv3Plus_xception |
Veuillez vous référer à Network / Modeling.py pour toutes les entrées de modèle.
Téléchargez des modèles pré-entraînés: Dropbox, Tencent Weiyun
Remarque: L'épine dorsale HRNET a été apportée par @timothylimyl. Une épine dorsale pré-formée est disponible sur Google Drive.
model = network . modeling . __dict__ [ MODEL_NAME ]( num_classes = NUM_CLASSES , output_stride = OUTPUT_SRTIDE )
model . load_state_dict ( torch . load ( PATH_TO_PTH )[ 'model_state' ] ) outputs = model ( images )
preds = outputs . max ( 1 )[ 1 ]. detach (). cpu (). numpy ()
colorized_preds = val_dst . decode_target ( preds ). astype ( 'uint8' ) # To RGB images, (N, H, W, 3), ranged 0~255, numpy array
# Do whatever you like here with the colorized segmentation maps
colorized_preds = Image . fromarray ( colorized_preds [ 0 ]) # to PIL ImageRemarque : Tous les modèles pré-entraînés de ce dépôt ont été formés sans convolution séparable atone.
La convolution séparable atrovitaire est soutenue dans ce repo. Nous fournissons un network.convert_to_separable_conv d'outils simple.convert_to_separable_conv pour convertir nn.Conv2d en AtrousSeparableConvolution . Veuillez exécuter main.py avec '--separable_conv' si cela est nécessaire . Voir «main.py» et «réseau / _deepLab.py» pour plus de détails.
Image unique:
python predict.py --input datasets/data/cityscapes/leftImg8bit/train/bremen/bremen_000000_000019_leftImg8bit.png --dataset cityscapes --model deeplabv3plus_mobilenet --ckpt checkpoints/best_deeplabv3plus_mobilenet_cityscapes_os16.pth --save_val_results_to test_resultsDossier d'image:
python predict.py --input datasets/data/cityscapes/leftImg8bit/train/bremen --dataset cityscapes --model deeplabv3plus_mobilenet --ckpt checkpoints/best_deeplabv3plus_mobilenet_cityscapes_os16.pth --save_val_results_to test_resultsVeuillez vous référer à cette commit (Xception) pour plus de détails sur la façon d'ajouter de nouveaux épine dorsaux.
Vous pouvez former des modèles DeepLab sur vos propres ensembles de données. Votre torch.utils.data.Dataset doit fournir une méthode de décodage qui transforme vos prédictions en images colorisées, tout comme l'ensemble de données VOC:
class MyDataset ( data . Dataset ):
...
@ classmethod
def decode_target ( cls , mask ):
"""decode semantic mask to RGB image"""
return cls . cmap [ mask ] Formation: 513x513 Cravel aléatoire
Validation: 513x513 Crame centrale
| Modèle | Taille de lot | Flops | Train / Val OS | mi- | Dropbox | Tencent Weiyun |
|---|---|---|---|---|---|---|
| DeepLabv3-Mobilenet | 16 | 6,0 g | 16/16 | 0,701 | Télécharger | Télécharger |
| DeepLabv3-Resnet50 | 16 | 51,4g | 16/16 | 0,769 | Télécharger | Télécharger |
| DeepLabv3-RESNET101 | 16 | 72.1g | 16/16 | 0,773 | Télécharger | Télécharger |
| DeepLabv3Plus-Mobilenet | 16 | 17.0g | 16/16 | 0,711 | Télécharger | Télécharger |
| DeepLabv3Plus-Resnet50 | 16 | 62,7g | 16/16 | 0,772 | Télécharger | Télécharger |
| DeepLabv3Plus-Resnet101 | 16 | 83,4g | 16/16 | 0,783 | Télécharger | Télécharger |
Formation: 768x768 Cravel aléatoire
Validation: 1024x2048
| Modèle | Taille de lot | Flops | Train / Val OS | mi- | Dropbox | Tencent Weiyun |
|---|---|---|---|---|---|---|
| DeepLabv3Plus-Mobilenet | 16 | 135g | 16/16 | 0,721 | Télécharger | Télécharger |
| DeepLabv3Plus-Resnet101 | 16 | N / A | 16/16 | 0,762 | Télécharger | N / A |












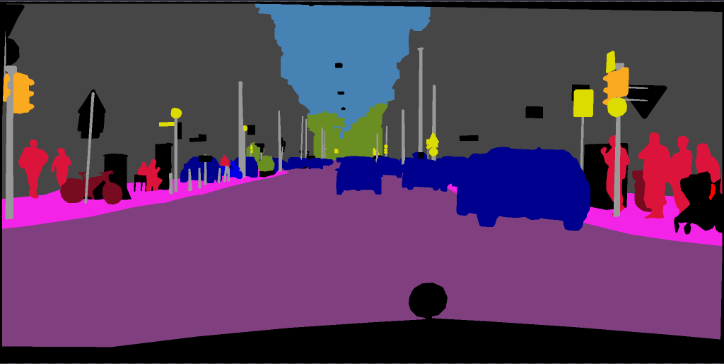

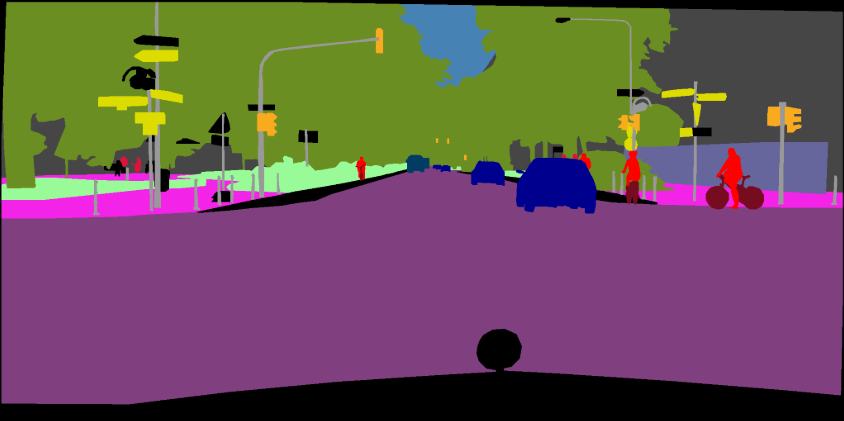

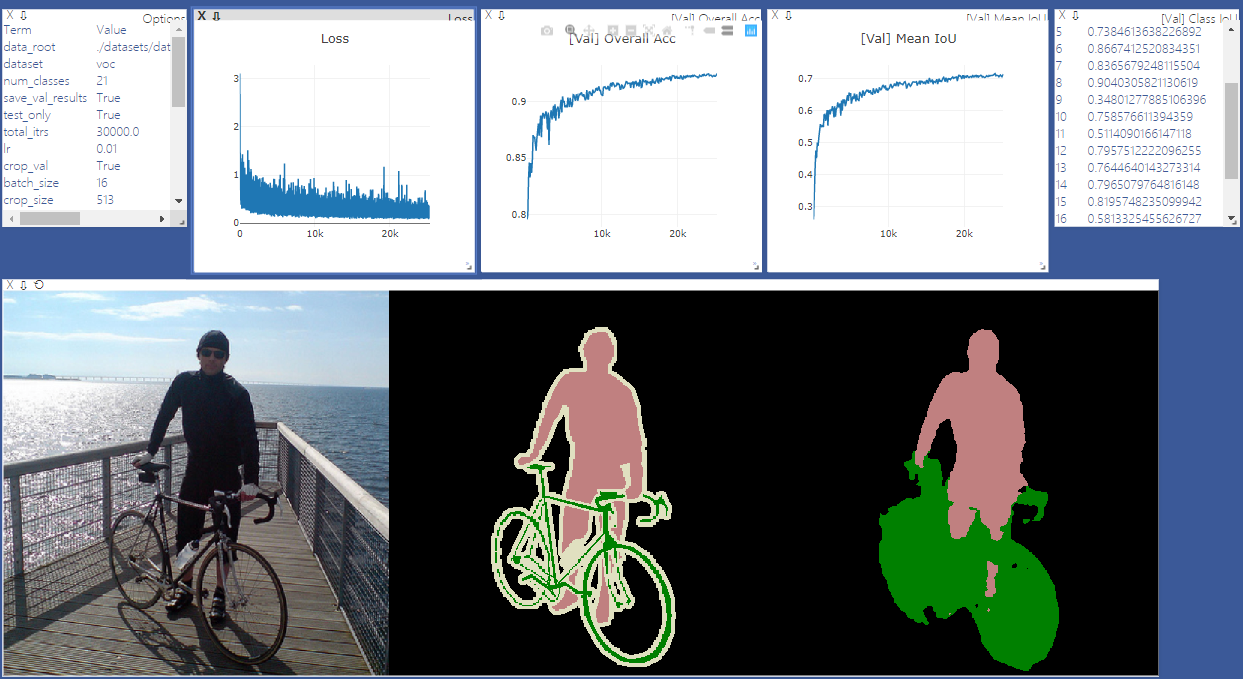
pip install -r requirements.txtVous pouvez exécuter Train.py avec l'option "- download" pour télécharger et extraire l'ensemble de données PASCAL VOC. Le chemin défaut est './datasets/data':
/datasets
/data
/VOCdevkit
/VOC2012
/SegmentationClass
/JPEGImages
...
...
/VOCtrainval_11-May-2012.tar
...
Voir le chapitre 4 de [2]
The original dataset contains 1464 (train), 1449 (val), and 1456 (test) pixel-level annotated images. We augment the dataset by the extra annotations provided by [76], resulting in 10582 (trainaug) training images. The performance is measured in terms of pixel intersection-over-union averaged across the 21 classes (mIOU).
./datasets/data/train_aug.txt inclut les noms de fichiers de 10582 images trains (les images VAL sont exclues). Veuillez télécharger leurs étiquettes à partir de Dropbox ou Tencent Weiyun. Ces étiquettes proviennent du dépôt de Drsleep.
Extraire les étiquettes Trainaug (SegmentationClassaug) dans le répertoire VOC2012.
/datasets
/data
/VOCdevkit
/VOC2012
/SegmentationClass
/SegmentationClassAug # <= the trainaug labels
/JPEGImages
...
...
/VOCtrainval_11-May-2012.tar
...
Commencez Visdom Sever pour la visualisation. Veuillez supprimer '--enable_vis' si la visualisation n'est pas nécessaire.
# Run visdom server on port 28333
visdom -port 28333Exécutez main.py avec "- année 2012_aug" pour former votre modèle sur Pascal VOC2012 août. Vous pouvez également parallèle votre formation sur 4 GPU avec '--gpu_id 0,1,2,3'
Remarque: il n'y a pas de synchronisation dans ce dépôt, donc une formation avec des GPU multiples et une petite taille de lot peut dégrader les performances. Voir le codage de pytorch pour plus de détails sur SyncBN
python main.py --model deeplabv3plus_mobilenet --enable_vis --vis_port 28333 --gpu_id 0 --year 2012_aug --crop_val --lr 0.01 --crop_size 513 --batch_size 16 --output_stride 16Exécutez main.py avec '--contiue_training' pour restaurer l'état_dict d'Optimizer et Scheduler de votre_CKPT.
python main.py ... --ckpt YOUR_CKPT --continue_trainingLes résultats seront enregistrés sur ./Results.
python main.py --model deeplabv3plus_mobilenet --enable_vis --vis_port 28333 --gpu_id 0 --year 2012_aug --crop_val --lr 0.01 --crop_size 513 --batch_size 16 --output_stride 16 --ckpt checkpoints/best_deeplabv3plus_mobilenet_voc_os16.pth --test_only --save_val_results /datasets
/data
/cityscapes
/gtFine
/leftImg8bit
python main.py --model deeplabv3plus_mobilenet --dataset cityscapes --enable_vis --vis_port 28333 --gpu_id 0 --lr 0.1 --crop_size 768 --batch_size 16 --output_stride 16 --data_root ./datasets/data/cityscapes [1] Repenser une convolution atrovitaire pour la segmentation sémantique de l'image
[2] Encodeur-décodeur avec convolution séparable atone pour la segmentation sémantique de l'image


