DeepLabV3Plus Pytorch
1.0.0
pretraned deeplabv3, deeplabv3+ สำหรับ pascal voc & cityscapes
| deeplabv3 | deeplabv3+ |
|---|---|
| deeplabv3_resnet50 | deeplabv3plus_resnet50 |
| deeplabv3_resnet101 | deeplabv3plus_resnet101 |
| deeplabv3_mobilenet | deeplabv3plus_mobilenet |
| deeplabv3_hrnetv2_48 | deeplabv3plus_hrnetv2_48 |
| deeplabv3_hrnetv2_32 | deeplabv3plus_hrnetv2_32 |
| deeplabv3_xception | deeplabv3plus_xception |
โปรดดูเครือข่าย/การสร้างแบบจำลองสำหรับรายการทั้งหมด
ดาวน์โหลดรุ่น Pretrained: Dropbox, Tencent Weiyun
หมายเหตุ: กระดูกสันหลัง HRNET ได้รับการสนับสนุนจาก @timothylimyl มีกระดูกสันหลังที่ผ่านการฝึกอบรมมาล่วงหน้าที่ Google Drive
model = network . modeling . __dict__ [ MODEL_NAME ]( num_classes = NUM_CLASSES , output_stride = OUTPUT_SRTIDE )
model . load_state_dict ( torch . load ( PATH_TO_PTH )[ 'model_state' ] ) outputs = model ( images )
preds = outputs . max ( 1 )[ 1 ]. detach (). cpu (). numpy ()
colorized_preds = val_dst . decode_target ( preds ). astype ( 'uint8' ) # To RGB images, (N, H, W, 3), ranged 0~255, numpy array
# Do whatever you like here with the colorized segmentation maps
colorized_preds = Image . fromarray ( colorized_preds [ 0 ]) # to PIL Imageหมายเหตุ : โมเดลที่ผ่านการฝึกอบรมล่วงหน้าทั้งหมดใน repo นี้ได้รับการฝึกฝนโดยไม่มีการแยกที่แยกออกได้
รองรับการแยกที่แยกกันไม่ออกได้รับการสนับสนุนใน repo นี้ เราให้ network.convert_to_separable_conv เครื่องมือง่าย ๆ convert_to_separable_conv เพื่อแปลง nn.Conv2d เป็น AtrousSeparableConvolution โปรดเรียกใช้ main.py ด้วย '-แยกได้ _conv' หากจำเป็น ดู 'main.py' และ 'Network/_deeplab.py' สำหรับรายละเอียดเพิ่มเติม
ภาพเดียว:
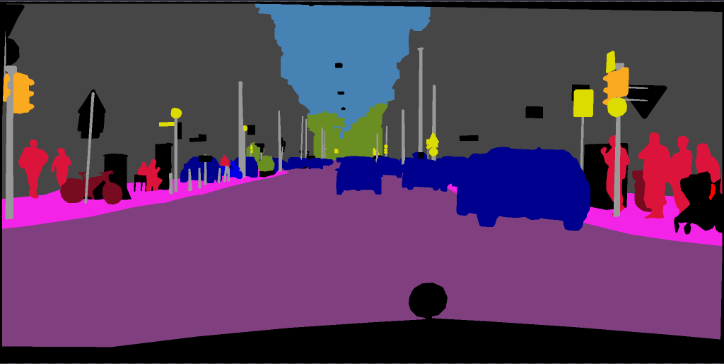
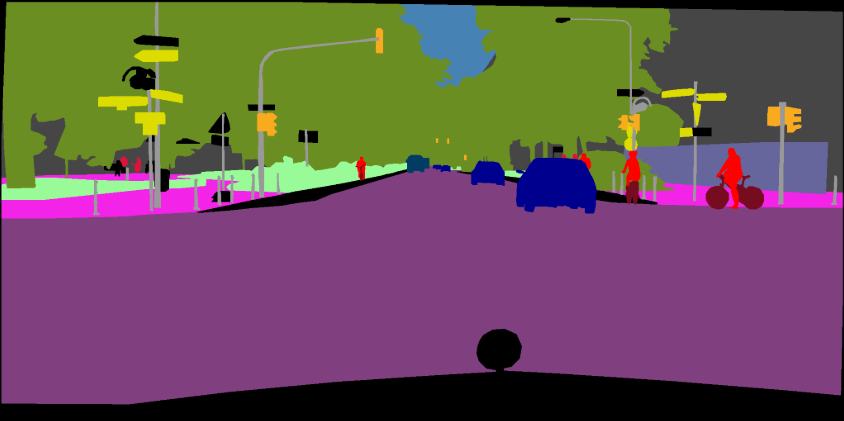
python predict.py --input datasets/data/cityscapes/leftImg8bit/train/bremen/bremen_000000_000019_leftImg8bit.png --dataset cityscapes --model deeplabv3plus_mobilenet --ckpt checkpoints/best_deeplabv3plus_mobilenet_cityscapes_os16.pth --save_val_results_to test_resultsโฟลเดอร์รูปภาพ:
python predict.py --input datasets/data/cityscapes/leftImg8bit/train/bremen --dataset cityscapes --model deeplabv3plus_mobilenet --ckpt checkpoints/best_deeplabv3plus_mobilenet_cityscapes_os16.pth --save_val_results_to test_resultsโปรดดูที่คอมมิชชันนี้ (xception) สำหรับรายละเอียดเพิ่มเติมเกี่ยวกับวิธีการเพิ่ม backbones ใหม่
คุณสามารถฝึกอบรมโมเดล Deeplab ในชุดข้อมูลของคุณเอง torch.utils.data.Dataset ของคุณควรให้วิธีการถอดรหัสที่เปลี่ยนการคาดการณ์ของคุณเป็นภาพสีเช่นเดียวกับชุดข้อมูล VOC:
class MyDataset ( data . Dataset ):
...
@ classmethod
def decode_target ( cls , mask ):
"""decode semantic mask to RGB image"""
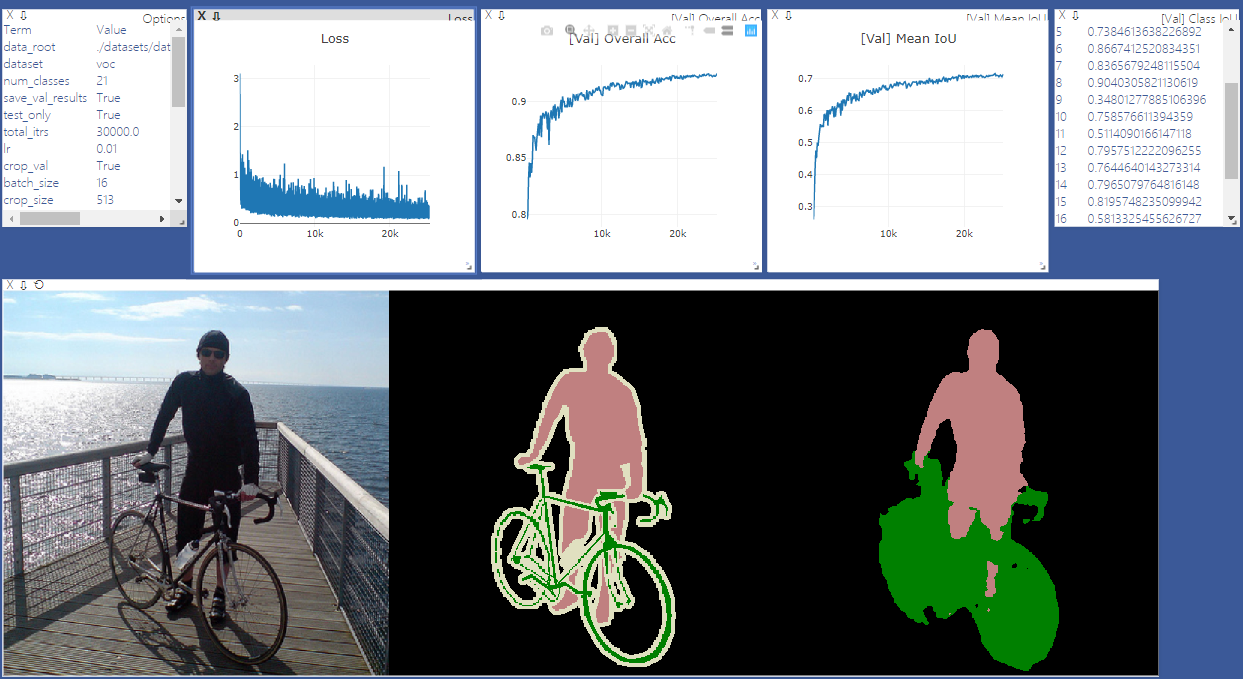
return cls . cmap [ mask ] การฝึกอบรม: 513x513 การเพาะปลูกแบบสุ่ม
การตรวจสอบความถูกต้อง: 513x513 Center Crop
| แบบอย่าง | ขนาดแบทช์ | ความกระฉับกระเฉง | รถไฟ/Val OS | Miou | กล่องดร็อปบ็อกซ์ | Tencent Weiyun |
|---|---|---|---|---|---|---|
| deeplabv3-mobilenet | 16 | 6.0g | 16/16 | 0.701 | การดาวน์โหลด | การดาวน์โหลด |
| deeplabv3-resnet50 | 16 | 51.4g | 16/16 | 0.769 | การดาวน์โหลด | การดาวน์โหลด |
| deeplabv3-resnet101 | 16 | 72.1g | 16/16 | 0.773 | การดาวน์โหลด | การดาวน์โหลด |
| deeplabv3plus-mobilenet | 16 | 17.0g | 16/16 | 0.711 | การดาวน์โหลด | การดาวน์โหลด |
| deeplabv3plus-resnet50 | 16 | 62.7g | 16/16 | 0.772 | การดาวน์โหลด | การดาวน์โหลด |
| deeplabv3plus-resnet101 | 16 | 83.4g | 16/16 | 0.783 | การดาวน์โหลด | การดาวน์โหลด |
การฝึกอบรม: 768x768 การเพาะปลูกแบบสุ่ม
การตรวจสอบ: 1024x2048
| แบบอย่าง | ขนาดแบทช์ | ความกระฉับกระเฉง | รถไฟ/Val OS | Miou | กล่องดร็อปบ็อกซ์ | Tencent Weiyun |
|---|---|---|---|---|---|---|
| deeplabv3plus-mobilenet | 16 | 135 กรัม | 16/16 | 0.721 | การดาวน์โหลด | การดาวน์โหลด |
| deeplabv3plus-resnet101 | 16 | N/A | 16/16 | 0.762 | การดาวน์โหลด | N/A |














pip install -r requirements.txtคุณสามารถเรียกใช้ Train.py ด้วยตัวเลือก "--download" เพื่อดาวน์โหลดและแยกชุดข้อมูล Pascal VOC เส้นทาง defaut คือ './datasets/data':
/datasets
/data
/VOCdevkit
/VOC2012
/SegmentationClass
/JPEGImages
...
...
/VOCtrainval_11-May-2012.tar
...
ดูบทที่ 4 ของ [2]
The original dataset contains 1464 (train), 1449 (val), and 1456 (test) pixel-level annotated images. We augment the dataset by the extra annotations provided by [76], resulting in 10582 (trainaug) training images. The performance is measured in terms of pixel intersection-over-union averaged across the 21 classes (mIOU).
./datasets/data/train_aug.txt รวมชื่อไฟล์ของภาพ 10582 Trainaug (ไม่รวมภาพวาลไว้) โปรดดาวน์โหลดป้ายกำกับจาก Dropbox หรือ Tencent Weiyun ฉลากเหล่านั้นมาจาก repo ของ Drsleep
แยกฉลาก Trainaug (SegmentationClassaug) ไปยังไดเรกทอรี VOC2012
/datasets
/data
/VOCdevkit
/VOC2012
/SegmentationClass
/SegmentationClassAug # <= the trainaug labels
/JPEGImages
...
...
/VOCtrainval_11-May-2012.tar
...
เริ่ม Visdom Sever สำหรับการสร้างภาพข้อมูล โปรดลบ '-enable_vis' หากไม่จำเป็นต้องมีการสร้างภาพข้อมูล
# Run visdom server on port 28333
visdom -port 28333เรียกใช้ main.py ด้วย "-ปี 2012_aug" เพื่อฝึกอบรมโมเดลของคุณใน Pascal VOC2012 สิงหาคมคุณยังสามารถขนานกับการฝึกอบรมของคุณใน 4 GPU ด้วย '-GPU_ID 0,1,2,3'
หมายเหตุ: ไม่มี SyncBN ใน repo นี้ดังนั้นการฝึกอบรมด้วย GPU หลายตัวและขนาดแบทช์ขนาดเล็ก อาจลดประสิทธิภาพลง ดูการเข้ารหัส pytorch สำหรับรายละเอียดเพิ่มเติมเกี่ยวกับ syncbn
python main.py --model deeplabv3plus_mobilenet --enable_vis --vis_port 28333 --gpu_id 0 --year 2012_aug --crop_val --lr 0.01 --crop_size 513 --batch_size 16 --output_stride 16เรียกใช้ main.py ด้วย '-continue_training' เพื่อกู้คืน state_dict ของ Optimizer และ Scheduler จาก Your_ckpt
python main.py ... --ckpt YOUR_CKPT --continue_trainingผลลัพธ์จะถูกบันทึกที่./results
python main.py --model deeplabv3plus_mobilenet --enable_vis --vis_port 28333 --gpu_id 0 --year 2012_aug --crop_val --lr 0.01 --crop_size 513 --batch_size 16 --output_stride 16 --ckpt checkpoints/best_deeplabv3plus_mobilenet_voc_os16.pth --test_only --save_val_results /datasets
/data
/cityscapes
/gtFine
/leftImg8bit
python main.py --model deeplabv3plus_mobilenet --dataset cityscapes --enable_vis --vis_port 28333 --gpu_id 0 --lr 0.1 --crop_size 768 --batch_size 16 --output_stride 16 --data_root ./datasets/data/cityscapes [1] ทบทวนการคิด atrous atrous สำหรับการแบ่งส่วนภาพความหมาย
[2] ตัวเข้ารหัส-ตัวพิมพ์ที่มีการแบ่งแยกแบบแยกกันไม่ได้สำหรับการแบ่งส่วนภาพความหมาย


