DeepLabV3Plus Pytorch
1.0.0
pretrained deeplabv3 ، deeplabv3+ لـ Pascal Voc & City Cscapes.
| deeplabv3 | deeplabv3+ |
|---|---|
| deeplabv3_resnet50 | deeplabv3plus_resnet50 |
| deeplabv3_resnet101 | deeplabv3plus_resnet101 |
| deeplabv3_mobilenet | deeplabv3plus_mobilenet |
| deeplabv3_hrnetv2_48 | deeplabv3plus_hrnetv2_48 |
| deeplabv3_hrnetv2_32 | deeplabv3plus_hrnetv2_32 |
| deeplabv3_xception | deeplabv3plus_xception |
يرجى الرجوع إلى الشبكة/النمذجة .py لجميع إدخالات النماذج.
تنزيل النماذج المسبق: Dropbox ، Tencent Weiyun
ملاحظة: ساهم العمود الفقري HRNET بواسطة Timothylimyl. يتوفر العمود الفقري الذي تم تدريبه مسبقًا في Google Drive.
model = network . modeling . __dict__ [ MODEL_NAME ]( num_classes = NUM_CLASSES , output_stride = OUTPUT_SRTIDE )
model . load_state_dict ( torch . load ( PATH_TO_PTH )[ 'model_state' ] ) outputs = model ( images )
preds = outputs . max ( 1 )[ 1 ]. detach (). cpu (). numpy ()
colorized_preds = val_dst . decode_target ( preds ). astype ( 'uint8' ) # To RGB images, (N, H, W, 3), ranged 0~255, numpy array
# Do whatever you like here with the colorized segmentation maps
colorized_preds = Image . fromarray ( colorized_preds [ 0 ]) # to PIL Imageملاحظة : تم تدريب جميع النماذج التي تم تدريبها مسبقًا في هذا الريبو دون إيلاء قابل للفصل.
يتم دعم الالتفاف القابل للفصل في هذا الريبو. نحن نقدم شبكة Simple Tool network.convert_to_separable_conv لتحويل nn.Conv2d إلى AtrousSeparableConvolution . يرجى تشغيل main.py مع '-separable_conv' إذا كان ذلك مطلوبًا . انظر "Main.py" و "Network/_deeplab.py" لمزيد من التفاصيل.
صورة واحدة:
python predict.py --input datasets/data/cityscapes/leftImg8bit/train/bremen/bremen_000000_000019_leftImg8bit.png --dataset cityscapes --model deeplabv3plus_mobilenet --ckpt checkpoints/best_deeplabv3plus_mobilenet_cityscapes_os16.pth --save_val_results_to test_resultsمجلد الصورة:
python predict.py --input datasets/data/cityscapes/leftImg8bit/train/bremen --dataset cityscapes --model deeplabv3plus_mobilenet --ckpt checkpoints/best_deeplabv3plus_mobilenet_cityscapes_os16.pth --save_val_results_to test_resultsيرجى الرجوع إلى هذا الالتزام (Xception) لمزيد من التفاصيل حول كيفية إضافة العمود الفقري الجديد.
يمكنك تدريب طرز DeepLab على مجموعات البيانات الخاصة بك. يجب أن توفر torch.utils.data.Dataset طريقة فك تشفيرها التي تحول تنبؤاتك إلى الصور الملونة ، تمامًا مثل مجموعة بيانات VOC:
class MyDataset ( data . Dataset ):
...
@ classmethod
def decode_target ( cls , mask ):
"""decode semantic mask to RGB image"""
return cls . cmap [ mask ] التدريب: 513x513 محصول عشوائي
التحقق من الصحة: 513x513 محصول المركز
| نموذج | حجم الدُفعة | يتخبط | قطار/Val OS | ميو | Dropbox | Tencent Weiyun |
|---|---|---|---|---|---|---|
| deeplabv3-mobilenet | 16 | 6.0g | 16/16 | 0.701 | تحميل | تحميل |
| deeplabv3-resnet50 | 16 | 51.4 جم | 16/16 | 0.769 | تحميل | تحميل |
| deeplabv3-resnet101 | 16 | 72.1g | 16/16 | 0.773 | تحميل | تحميل |
| deeplabv3plus-mobilenet | 16 | 17.0g | 16/16 | 0.711 | تحميل | تحميل |
| deeplabv3plus-resnet50 | 16 | 62.7 جم | 16/16 | 0.772 | تحميل | تحميل |
| deeplabv3plus-resnet101 | 16 | 83.4g | 16/16 | 0.783 | تحميل | تحميل |
التدريب: 768x768 محصول عشوائي
التحقق من الصحة: 1024x2048
| نموذج | حجم الدُفعة | يتخبط | قطار/Val OS | ميو | Dropbox | Tencent Weiyun |
|---|---|---|---|---|---|---|
| deeplabv3plus-mobilenet | 16 | 135 جم | 16/16 | 0.721 | تحميل | تحميل |
| deeplabv3plus-resnet101 | 16 | ن/أ | 16/16 | 0.762 | تحميل | ن/أ |












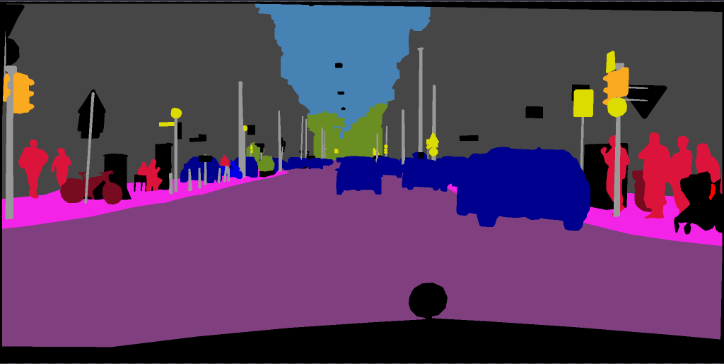

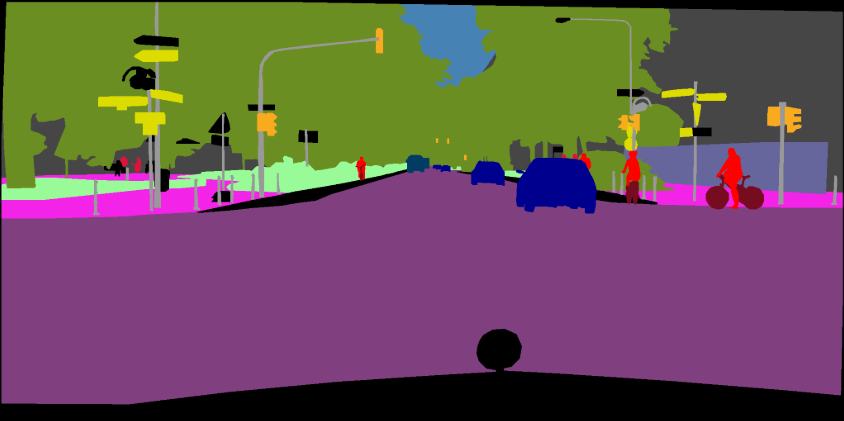

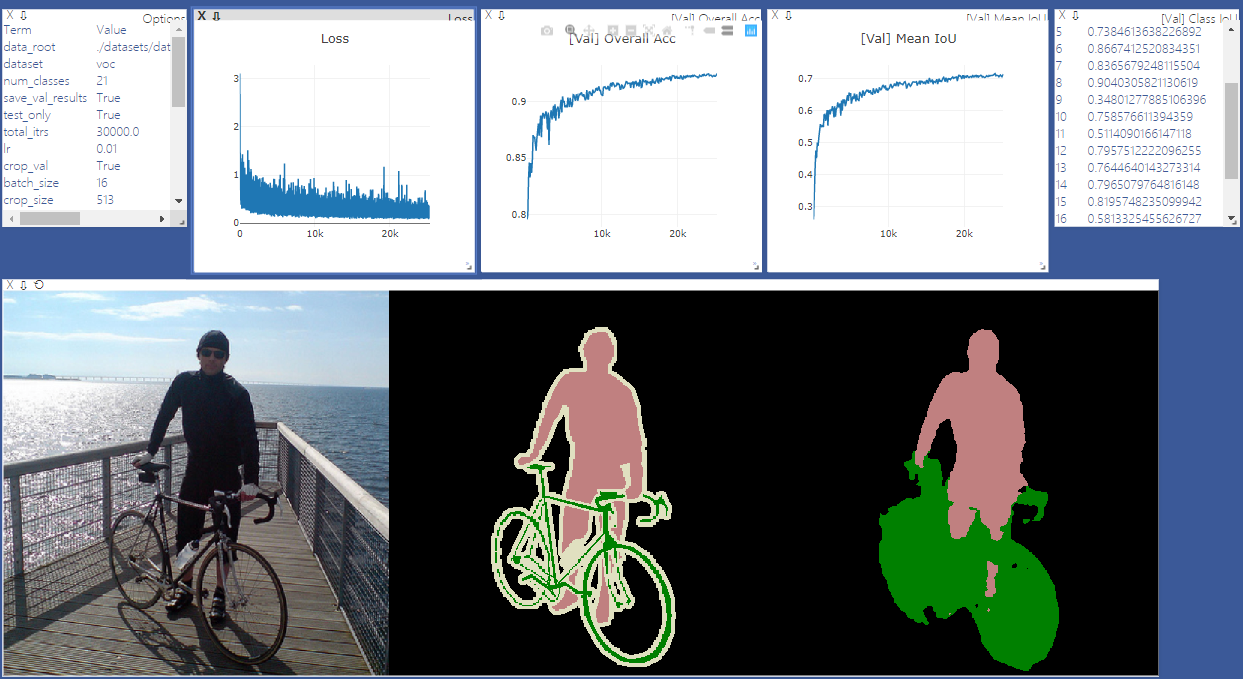
pip install -r requirements.txtيمكنك تشغيل Train.py مع خيار "-Download" لتنزيل واستخراج مجموعة بيانات Pascal Voc. مسار Defaut هو './datasets/data':
/datasets
/data
/VOCdevkit
/VOC2012
/SegmentationClass
/JPEGImages
...
...
/VOCtrainval_11-May-2012.tar
...
انظر الفصل 4 من [2]
The original dataset contains 1464 (train), 1449 (val), and 1456 (test) pixel-level annotated images. We augment the dataset by the extra annotations provided by [76], resulting in 10582 (trainaug) training images. The performance is measured in terms of pixel intersection-over-union averaged across the 21 classes (mIOU).
./datasets/data/train_aug.txt تتضمن أسماء الملفات لـ 10582 Tertaug Images (يتم استبعاد صور Val). يرجى تنزيل ملصقاتهم من Dropbox أو Tencent Weiyun. هذه الملصقات تأتي من ريبو Drsleep.
استخراج ملصقات Trainaug (SegmentationClassaug) إلى دليل Voc2012.
/datasets
/data
/VOCdevkit
/VOC2012
/SegmentationClass
/SegmentationClassAug # <= the trainaug labels
/JPEGImages
...
...
/VOCtrainval_11-May-2012.tar
...
ابدأ Visdom Sever لتصور. يرجى إزالة "-enable_vis" إذا لم يكن هناك حاجة للتصور.
# Run visdom server on port 28333
visdom -port 28333قم بتشغيل main.py مع "-year 2012_aug" لتدريب نموذجك على Pascal Voc2012 أغسطس. يمكنك أيضًا موازاة تدريبك على 4 وحدات معالجة الرسومات مع '-gpu_id 0،1،2،3'
ملاحظة: لا يوجد مزامنة في هذا الريبو ، لذلك قد يؤدي التدريب مع وحدات معالجة الرسومات المتعددة وحجم الدُفعة الصغيرة إلى تدهور الأداء. انظر ترميز Pytorch لمزيد من التفاصيل حول syncbn
python main.py --model deeplabv3plus_mobilenet --enable_vis --vis_port 28333 --gpu_id 0 --year 2012_aug --crop_val --lr 0.01 --crop_size 513 --batch_size 16 --output_stride 16قم بتشغيل main.py مع '--continue_training' لاستعادة state_dict of Optimizer and Scheduler من your_ckpt.
python main.py ... --ckpt YOUR_CKPT --continue_trainingسيتم حفظ النتائج في ./results.
python main.py --model deeplabv3plus_mobilenet --enable_vis --vis_port 28333 --gpu_id 0 --year 2012_aug --crop_val --lr 0.01 --crop_size 513 --batch_size 16 --output_stride 16 --ckpt checkpoints/best_deeplabv3plus_mobilenet_voc_os16.pth --test_only --save_val_results /datasets
/data
/cityscapes
/gtFine
/leftImg8bit
python main.py --model deeplabv3plus_mobilenet --dataset cityscapes --enable_vis --vis_port 28333 --gpu_id 0 --lr 0.1 --crop_size 768 --batch_size 16 --output_stride 16 --data_root ./datasets/data/cityscapes [1] إعادة التفكير في الالتفاف الافتراضي لتجزئة الصور الدلالية
[2] ترميز الترميز مع الالتفاف القابل للفصل لتجزئة الصور الدلالية


