DeepLabV3Plus Pytorch
1.0.0
파스칼 voc 및 도시 스케이프의 경우 사전 예방 된 deeplabv3, deeplabv3+.
| deeplabv3 | deeplabv3+ |
|---|---|
| deeplabv3_resnet50 | deeplabv3plus_resnet50 |
| deeplabv3_resnet101 | deeplabv3plus_resnet101 |
| deeplabv3_mobilenet | deeplabv3plus_mobilenet |
| deeplabv3_hrnetv2_48 | deeplabv3plus_hrnetv2_48 |
| deeplabv3_hrnetv2_32 | deeplabv3plus_hrnetv2_32 |
| deeplabv3_xception | deeplabv3plus_xception |
모든 모델 항목은 Network/Modeling.py를 참조하십시오.
사전 상호 모델 다운로드 : Dropbox, Tencent Weiyun
참고 : HRNET 백본은 @Timothylimyl에 의해 기여되었습니다. 미리 훈련 된 백본은 Google 드라이브에서 제공됩니다.
model = network . modeling . __dict__ [ MODEL_NAME ]( num_classes = NUM_CLASSES , output_stride = OUTPUT_SRTIDE )
model . load_state_dict ( torch . load ( PATH_TO_PTH )[ 'model_state' ] ) outputs = model ( images )
preds = outputs . max ( 1 )[ 1 ]. detach (). cpu (). numpy ()
colorized_preds = val_dst . decode_target ( preds ). astype ( 'uint8' ) # To RGB images, (N, H, W, 3), ranged 0~255, numpy array
# Do whatever you like here with the colorized segmentation maps
colorized_preds = Image . fromarray ( colorized_preds [ 0 ]) # to PIL Image참고 :이 저장소의 모든 미리 훈련 된 모델은 황량한 분리 가능한 컨볼 루션없이 훈련되었습니다.
이 리포지토리에서는 끔찍한 분리 가능한 컨볼 루션이 지원됩니다. 우리는 간단한 도구 network.convert_to_separable_conv 제공합니다 .convert_to_separable_conv는 nn.Conv2d AtrousSeparableConvolution 으로 변환합니다. 필요한 경우 '-separable_conv'로 main.py를 실행하십시오 . 자세한 내용은 'main.py'및 'Network/_deeplab.py'를 참조하십시오.
단일 이미지 :
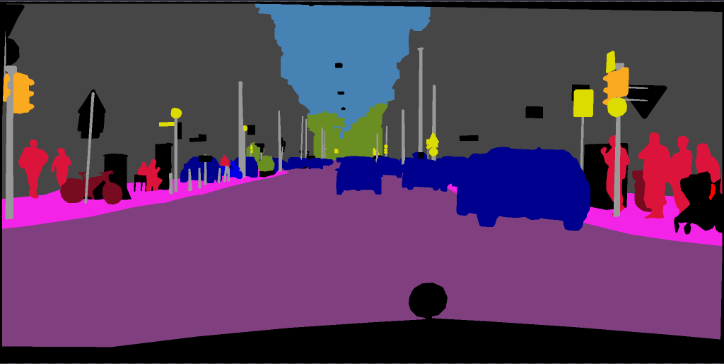
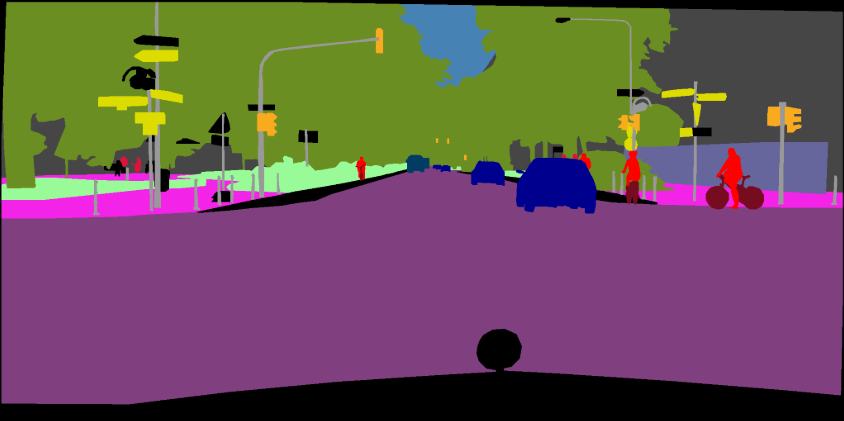
python predict.py --input datasets/data/cityscapes/leftImg8bit/train/bremen/bremen_000000_000019_leftImg8bit.png --dataset cityscapes --model deeplabv3plus_mobilenet --ckpt checkpoints/best_deeplabv3plus_mobilenet_cityscapes_os16.pth --save_val_results_to test_results이미지 폴더 :
python predict.py --input datasets/data/cityscapes/leftImg8bit/train/bremen --dataset cityscapes --model deeplabv3plus_mobilenet --ckpt checkpoints/best_deeplabv3plus_mobilenet_cityscapes_os16.pth --save_val_results_to test_results새로운 백본을 추가하는 방법에 대한 자세한 내용은이 커밋 (Xception)을 참조하십시오.
자신의 데이터 세트에서 Deeplab 모델을 훈련시킬 수 있습니다. torch.utils.data.Dataset 은 VOC 데이터 세트와 마찬가지로 예측을 색상화 된 이미지로 변환하는 디코딩 방법을 제공해야합니다.
class MyDataset ( data . Dataset ):
...
@ classmethod
def decode_target ( cls , mask ):
"""decode semantic mask to RGB image"""
return cls . cmap [ mask ] 훈련 : 513x513 임의의 작물
검증 : 513x513 센터 작물
| 모델 | 배치 크기 | 플롭 | 기차/발 OS | 미우 | 드롭 박스 | Tencent Weiyun |
|---|---|---|---|---|---|---|
| Deeplabv3-Mobilenet | 16 | 6.0g | 16/16 | 0.701 | 다운로드 | 다운로드 |
| deeplabv3-resnet50 | 16 | 51.4g | 16/16 | 0.769 | 다운로드 | 다운로드 |
| deeplabv3-resnet101 | 16 | 72.1g | 16/16 | 0.773 | 다운로드 | 다운로드 |
| deeplabv3plus-mobilenet | 16 | 17.0g | 16/16 | 0.711 | 다운로드 | 다운로드 |
| Deeplabv3plus-Resnet50 | 16 | 62.7g | 16/16 | 0.772 | 다운로드 | 다운로드 |
| Deeplabv3plus-Resnet101 | 16 | 83.4g | 16/16 | 0.783 | 다운로드 | 다운로드 |
훈련 : 768x768 임의의 작물
검증 : 1024x2048
| 모델 | 배치 크기 | 플롭 | 기차/발 OS | 미우 | 드롭 박스 | Tencent Weiyun |
|---|---|---|---|---|---|---|
| deeplabv3plus-mobilenet | 16 | 135g | 16/16 | 0.721 | 다운로드 | 다운로드 |
| Deeplabv3plus-Resnet101 | 16 | N/A | 16/16 | 0.762 | 다운로드 | N/A |














pip install -r requirements.txtPascal VOC 데이터 세트를 다운로드하여 추출하려면 "-download"옵션으로 Train.py를 실행할 수 있습니다. defaut 경로는 './datasets/data'입니다.
/datasets
/data
/VOCdevkit
/VOC2012
/SegmentationClass
/JPEGImages
...
...
/VOCtrainval_11-May-2012.tar
...
[2]의 4 장 참조
The original dataset contains 1464 (train), 1449 (val), and 1456 (test) pixel-level annotated images. We augment the dataset by the extra annotations provided by [76], resulting in 10582 (trainaug) training images. The performance is measured in terms of pixel intersection-over-union averaged across the 21 classes (mIOU).
./datasets/data/train_aug.txt 에는 10582 Trainaug 이미지의 파일 이름이 포함되어 있습니다 (Val 이미지는 제외). Dropbox 또는 Tencent Weiyun에서 레이블을 다운로드하십시오. 이 라벨은 Drsleep의 Repo에서 나옵니다.
Trainaug 레이블 (SegmentationClassaug)을 VOC2012 디렉토리로 추출하십시오.
/datasets
/data
/VOCdevkit
/VOC2012
/SegmentationClass
/SegmentationClassAug # <= the trainaug labels
/JPEGImages
...
...
/VOCtrainval_11-May-2012.tar
...
시각화를 위해 Vistom Sever를 시작하십시오. 시각화가 필요하지 않은 경우 '-enable_vis'를 제거하십시오.
# Run visdom server on port 28333
visdom -port 28333Pascal Voc2012에서 모델을 훈련시키기 위해 "--yeal 2012_aug" 로 main.py를 실행하십시오. '-gpu_id 0,1,2,3'과 4 GPU에 대한 교육을 평행하게 할 수도 있습니다.
참고 :이 저장소에는 SyncBN이 없으므로 멀티 GPU 및 작은 배치 크기 로 훈련하면 성능이 저하 될 수 있습니다. SyncBN에 대한 자세한 내용은 Pytorch-Encoding을 참조하십시오
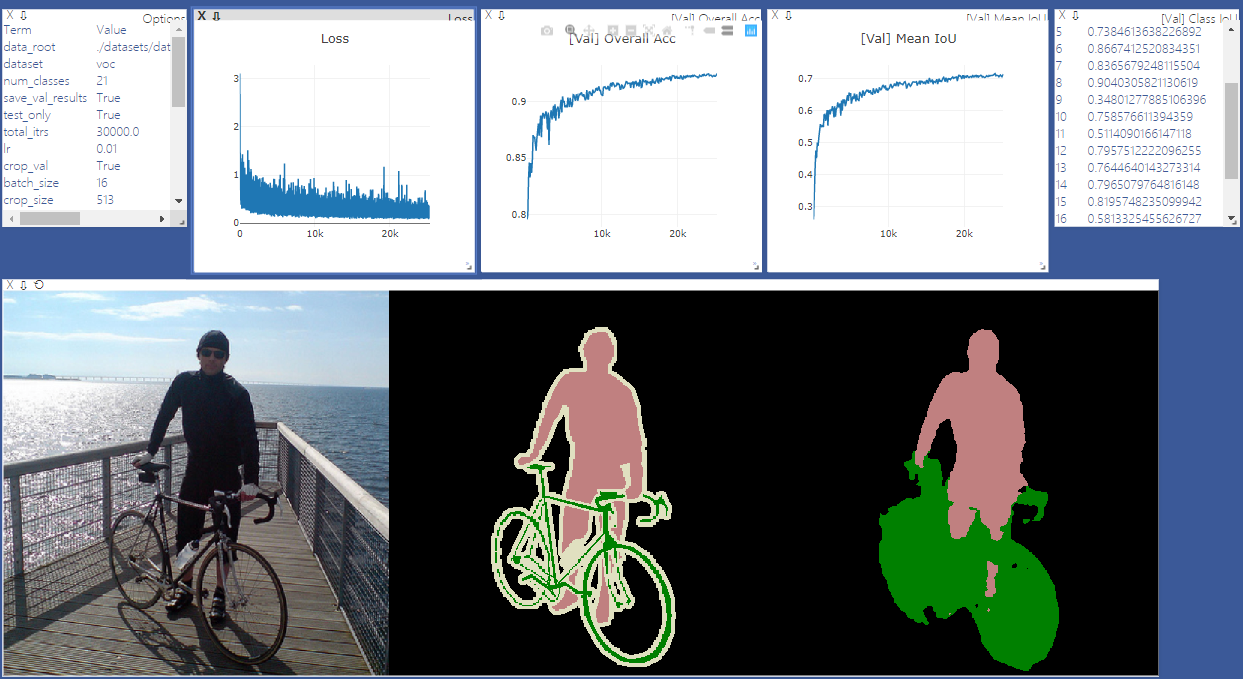
python main.py --model deeplabv3plus_mobilenet --enable_vis --vis_port 28333 --gpu_id 0 --year 2012_aug --crop_val --lr 0.01 --crop_size 513 --batch_size 16 --output_stride 16'---continue_training'으로 main.py를 실행하여 your_ckpt에서 Optimizer 및 Scheduler의 state_dict를 복원하십시오.
python main.py ... --ckpt YOUR_CKPT --continue_training결과는 ./Results에서 저장됩니다.
python main.py --model deeplabv3plus_mobilenet --enable_vis --vis_port 28333 --gpu_id 0 --year 2012_aug --crop_val --lr 0.01 --crop_size 513 --batch_size 16 --output_stride 16 --ckpt checkpoints/best_deeplabv3plus_mobilenet_voc_os16.pth --test_only --save_val_results /datasets
/data
/cityscapes
/gtFine
/leftImg8bit
python main.py --model deeplabv3plus_mobilenet --dataset cityscapes --enable_vis --vis_port 28333 --gpu_id 0 --lr 0.1 --crop_size 768 --batch_size 16 --output_stride 16 --data_root ./datasets/data/cityscapes [1] 의미 론적 이미지 세분화를위한 황제 컨볼 루션을 다시 생각합니다
[2] 시맨틱 이미지 분할을위한 황제 분리 가능한 컨볼 루션이있는 인코더 디코더


